Container > NHN Kubernetes Service(NKS) > 使用ガイド
クラスター
クラスターは、ユーザーのKubernetesを構成するインスタンスのグループです。
Kubernetesバージョンサポートポリシー
NKSのKubernetesバージョンサポートポリシーは次のとおりです。
- 最新Kubernetesバージョンをサポート
- NKSは最新のKubernetesバージョンを継続的に提供し、クラスタが最新のバージョンを維持できるようにします。
- クラスタを新しいバージョンで作成したり、既存のクラスタを新しいバージョンにアップグレードして使用できます。
- 作成可能なバージョン
- クラスタとして作成可能なKubernetesバージョンは4つに維持されます。
- 従って、作成可能なバージョンが一つ追加されると、既存の作成可能バージョンリストから最も低いバージョンが削除されます。
- サービスサポートバージョン
- サービスサポートが終了したバージョンを使用するクラスタは、NKSの新規機能動作を保証しません。
- NKSのクラスタのバージョンアップグレード機能でクラスタのKubernetesバージョンをアップグレードできます。
- サービスサポートKubernetesバージョンは5つに維持されます。
- 従って、作成可能なバージョンが一つ追加されると、既存のサービスサポート可能バージョンリストから最も低いバージョンが削除されます。
Kubernetesバージョン別の作成可能バージョンに追加/削除する時点と、サービスサポート終了時点は以下の通りです。 (ただし、この表は2023年9月26日基準で作成されたもので、新規作成可能バージョンのバージョン名と提供時期は弊社内部事情により変更される場合があります)
| バージョン | 作成可能バージョンに追加 | 作成可能バージョンから削除 | サービスサポート終了 |
|---|---|---|---|
| v1.22.3 | 2022. 01. | 2023. 05. | 2023. 08. |
| v1.23.3 | 2022. 03. | 2023. 08. | 2024. 02. |
| v1.24.3 | 2022. 09. | 2024. 02. | 2024. 05.(予定) |
| v1.25.4 | 2023. 01. | 2024. 05.(予定) | 2024. 08.(予定) |
| v1.26.3 | 2023. 05. | 2024. 08.(予定) | 2025. 02.(予定) |
| v1.27.3 | 2023. 08. | 2025. 02.(予定) | 2025. 05.(予定) |
| v1.28.3 | 2024. 02. | 2025. 05.(予定) | 2025. 08.(予定) |
| v1.29.x | 2024. 05.(予定) | 2025. 08.(予定) | 2025. 11.(予定) |
クラスター作成
NHN Kubernetes Service(NKS)を使用するには、まずクラスターを作成する必要があります。
[注意]クラスタを使用するための権限設定
クラスタを作成したいユーザーは、対象プロジェクトに対して必ず基本インフラサービスの Infrastructure ADMINまたは Infrastructure LoadBalancer ADMIN権限を持っている必要があります。 当該権限がある場合にのみ、基本インフラサービスをベースとするクラスタを正常に作成し、活用できます。これらのいずれかの権限を持つ状態で他の権限が追加されることは使用に問題がありません。 権限設定についてはプロジェクトメンバー管理をご覧ください。 クラスタ作成時点の権限設定内容が将来変更(任意の権限追加または削除)される場合、クラスタの一部機能の使用に制限がかかる場合があります。 詳しくはクラスタOWNER変更をご覧ください。 Container > NHN Kubernetes Service(NKS) ページでクラスタ作成をクリックすると、クラスタ作成ページが表示されます。クラスタの作成に必要な項目は次のとおりです。
| 項目 | 説明 |
|---|---|
| クラスター名 | Kubernetesクラスターの名前。32文字以内で小文字と数字、(-)のみ入力可能です。小文字で始まり、小文字または数字で終わる必要があります。RFC 4122標準のUUID形式は使用できません。 |
| Kubernetesのバージョン | 使用するKubernetesのバージョン |
| VPC | クラスターに接続するVPCネットワーク |
| サブネット | VPCに定義されたサブネットのうち、クラスターを構成するインスタンスに接続するサブネット |
| NCRサービスゲートウェイ | NCRタイプのサービスゲートウェイ (ただし、サブネットにインターネットゲートウェイが接続されていない場合に限る) |
| OBSサービスゲートウェイ | OBSタイプのサービスゲートウェイ (ただし、サブネットにインターネットゲートウェイが接続されていない場合に限る) |
| K8sサービスネットワーク | クラスタのservice object CIDR設定 |
| Podネットワーク | クラスタのPodネットワーク設定 |
| Podサブネットサイズ | クラスタのPodサブネットサイズ設定 |
| Kubernetes APIエンドポイント | Public:エンドポイントにドメインアドレスを割り当て、Floating IPを接続 Private:エンドポイントを内部ネットワークアドレスに設定 |
| 強化されたセキュリティルール | ワーカーノードセキュリティグループ作成時、必須セキュリティルールのみ作成。クラスタワーカーノード必須セキュリティルール項目参照 True:必須セキュリティルールのみ作成 False:必須セキュリティルールとすべてのポートを許可するセキュリティルールを作成 |
| イメージ | クラスターを構成するインスタンスに使用するイメージ |
| アベイラビリティゾーン | 基本ノードグループインスタンスを作成する領域 |
| インスタンスタイプ | 基本ノードグループインスタンスの仕様 |
| ノード数 | 基本ノードグループインスタンスの数 |
| キーペア | 基本ノードグループアクセスに使用するキーペア |
| ブロックストレージタイプ | 基本ノードグループインスタンスのブロックストレージの種類 |
| ブロックストレージサイズ | 基本ノードグループインスタンスのブロックストレージサイズ |
| 追加ネットワーク | 基本ワーカーノードグループに作成する追加ネットワーク/サブネット |
[注意] VPCネットワークサブネットとK8sサービスネットワーク、 PodネットワークのCIDRは、以下の制約事項に該当しないように設定する必要があります。 - リンクローカルアドレス帯域(169.254.0.0/16)と重複することはできません。 - VPCネットワークサブネット、追加ネットワークサブネット、 PodネットワークとK8sサービスネットワーク帯域は重複することができません。 - NKS内部で使用しているIP帯域(198.18.0.0/19)と重複することはできません。 - /24より大きいCIDRブロックは入力できません(次のようなCIDRブロックは使用できません。 /26, /30)。 - v1.23.3以下クラスタの場合ドッカーBIP(bridged IP range)と重複できません(172.17.0.0/16).
クラスタ作成時に設定したサービスゲートウェイは削除しないでください。 - 選択したサブネットがインターネットゲートウェイに接続されていない場合、NCRサービスゲートウェイとOBSサービスゲートウェイの設定が必要です。 - この2つのサービスゲートウェイはNKSクラスタ構成及び基本機能に必要なイメージ/バイナリを受信する際に使用されます。 - クラスタ作成時に設定したサービスゲートウェイを削除すると、クラスタが正常に動作しません。
クラスタ作成時に設定したサブネットのインターネットゲートウェイ接続の有無を変更しないでください。 - クラスタ作成時に設定したサブネットのインターネットゲートウェイ接続の有無によって、イメージ/バイナリを受け取るレジストリが変わります。 - クラスタ作成後、サブネットのインターネットゲートウェイ接続の有無が変更されると、設定されたレジストリに接続できず、クラスタが正常に動作しません。 [最大作成可能なノード数] クラスタ作成時に作成可能な最大ノード数はPodネットワーク、 Podサブネットサイズ設定で決定されます。 計算方法 : 2 ^ (Podサブネットサイズ - Podネットワークのホストビット) - 3 例: - Podサブネットサイズ= 24 - Podネットワーク= 10.100.0.0/16 - 計算 : 2 ^ (24 - 16) - 3 = 最大253個ノード作成可能 [ノードごとにPodに割り当てることができる最大IP数] 一つのノードで使用可能な最大IP数と、作成可能な最大ノード数はPodサブネットサイズ設定で決定されます。 計算方法 : 2 ^ (32 - pods_network_subnet) - 2 例: - Podサブネットサイズ= 24 - 計算 : 2 ^ (32 - 24) - 2 =最大254個のIPを使用可能 [クラスタでPodに割り当てることができる最大IP数] 計算方法 :ノードごとにPodに割り当てることができる最大IP数 * 最大作成可能なノード数 例: - Podサブネットサイズ= 24 - Podネットワーク= 10.100.0.0/16 - 計算 : 254(ノードごとにPodに割り当て可能な最大IP数) * 253(最大作成可能なノード数) =最大64,262個のIPを使用可能
NHN Kubernetes Service(NKS)は複数のバージョンをサポートしています。バージョンによっては一部機能に制約がある場合があります。
| バージョン | クラスタ新規作成 | 作成されたクラスタの使用 |
|---|---|---|
| v1.17.6 | 不可 | 可能 |
| v1.18.19 | 不可 | 可能 |
| v1.19.13 | 不可 | 可能 |
| v1.20.12 | 不可 | 可能 |
| v1.21.6 | 不可 | 可能 |
| v1.22.3 | 不可 | 可能 |
| v1.23.3 | 不可 | 可能 |
| v1.24.3 | 不可 | 可能 |
| v1.25.4 | 可能 | 可能 |
| v1.26.3 | 可能 | 可能 |
| v1.27.3 | 可能 | 可能 |
| v1.28.3 | 可能 | 可能 |
NHN Kubernetes Service(NKS)はバージョンによって異なる種類のContainer Network Interface(CNI)を提供します。2023/03/31以降はv1.24.3バージョン以上のクラスタを作成する時、CNIがCalicoで作成されます。 FlannelとCalico CNIのNetwork modeは全てVXLAN方式で作します。
| バージョン | クラスタ作成時にインストールしたCNIの種類およびバージョン | CNI変更可否 |
|---|---|---|
| v1.17.6 | Flannel v0.12.0 | 不可 |
| v1.18.19 | Flannel v0.12.0 | 不可 |
| v1.19.13 | Flannel v0.14.0 | 不可 |
| v1.20.12 | Flannel v0.14.0 | 不可 |
| v1.21.6 | Flannel v0.14.0 | 不可 |
| v1.22.3 | Flannel v0.14.0 | 不可 |
| v1.23.3 | Flannel v0.14.0 | 不可 |
| v1.24.3 | Flannel v0.14.0またはCalico v3.24.1 (注1)(#footnote_calico_version_1) | 条件付きで可能 (注2)(#footnote_calico_version_2) |
| v1.25.4 | Flannel v0.14.0またはCalico v3.24.1 (注1)(#footnote_calico_version_1) | 条件付きで可能 (注2)(#footnote_calico_version_2) |
| v1.26.3 | Flannel v0.14.0またはCalico v3.24.1 1 | 条件付き可能 2 |
| v1.27.3 | Calico v3.24.1 | 不可 |
| v1.28.3 | Calico v3.24.1 | 不可 |
注釈 * (注1)2023/03/31以前に作成されたクラスタにはFlannelがインストールされています。 2023/03/31以降に作成されるv1.24.3以上のクラスタはCalicoがインストールされます。 * (注2)CNIの変更はv1.24.3以上のクラスタでのみサポートされ、現在FlannelからCalicoへの変更のみサポートします。
クラスタワーカーノード必須セキュリティルール項目
| 方向 | IPプロトコル | ポート範囲 | Ether | 遠隔 | 説明 | 特記事項 |
|---|---|---|---|---|---|---|
| ingress | TCP | 10250 | IPv4 | ワーカーノード | kubeletポート、方向: metrics-server(worker node) -> kubelet(worker node) | |
| ingress | TCP | 10250 | IPv4 | マスターノード | kubeletポート、方向: kube-apiserver(NKS Control plane) -> kubelet(worker node) | |
| ingress | TCP | 5473 | IPv4 | ワーカーノード | calico-typhaポート、方向: calico-node(worker node) -> calico-typha(worker node) | CNIがcalicoの場合に作成 |
| ingress | UDP | 8472 | IPv4 | ワーカーノード | flannel vxlan overlay networkポート、方向: pod(worker node) -> pod(worker node) | CNIがflannelの場合に作成される |
| ingress | UDP | 8472 | IPv4 | ワーカーノード | flannel vxlan overlay networkポート、方向: pod(NKS Control plane) -> pod(worker node) | CNIがflannelの場合に作成される |
| ingress | UDP | 4789 | IPv4 | ワーカーノード | calico-node vxlan overlay networkポート、方向: pod(worker node) -> pod(worker node) | CNIがcalicoの場合に作成される |
| ingress | UDP | 4789 | IPv4 | マスターノード | calico-node vxlan overlay networkポート、方向: pod(NKS Control plane) -> pod(worker node) | CNIがcalicoの場合に作成される |
| egress | TCP | 2379 | IPv4 | マスターノード | etcdポート、方向: calico-kube-controller(worker node) -> etcd(NKS Control plane) | |
| egress | TCP | 6443 | IPv4 | Kubernetes APIエンドポイント | kube-apiserverポート、方向: kubelet, kube-proxy(worker node) -> kube-apiserver(NKS Control plane) | |
| egress | TCP | 6443 | IPv4 | マスターノード | kube-apiserverポート、方向: default kubernetes service(worker node) -> kube-apiserver(NKS Control plane) | |
| egress | TCP | 5473 | IPv4 | ワーカーノード | CNIがcalicoの場合に作成される、 calico-typhaポート、方向: calico-node(worker node) -> calico-typha(worker node) | |
| egress | TCP | 53 | IPv4 | ワーカーノード | DNSポート、方向: worker node -> external | |
| egress | TCP | 443 | IPv4 | すべて許可 | HTTPSポート、方向: worker node -> external | |
| egress | TCP | 80 | IPv4 | すべて許可 | HTTPポート、方向: worker node -> external | |
| egress | UDP | 8472 | IPv4 | ワーカーノード | flannel vxlan overlay networkポート、方向: pod(worker node) -> pod(worker node) | CNIがflannelの場合に作成される |
| egress | UDP | 8472 | IPv4 | マスターノード | flannel vxlan overlay networkポート、方向: pod(worker node) -> pod(NKS Control plane) | CNIがflannelの場合に作成される |
| egress | UDP | 4789 | IPv4 | ワーカーノード | calico-node vxlan overlay networkポート、方向: pod(worker node) -> pod(worker node) | CNIがcalicoの場合に作成される |
| egress | UDP | 4789 | IPv4 | マスターノード | calico-node vxlan overlay networkポート、方向: pod(worker node) -> pod(NKS Control plane) | CNIがcalicoの場合に作成される |
| egress | UDP | 53 | IPv4 | すべて許可 | DNSポート、方向: worker node -> external |
強化されたセキュリティルールを使用する場合、NodePortタイプのサービスとNHN Cloud NASサービスで使用するポートに対するセキュリティルールに追加されていません。 必要に応じて以下のセキュリティルールを追加設定する必要があります。
| 方向 | IPプロトコル | ポート範囲 | Ether | 遠隔 | 説明 |
|---|---|---|---|---|---|
| ingress, egress | TCP | 30000 - 32767 | IPv4 | すべて許可 | NKS service object NodePort、方向: external -> worker node |
| egress | TCP | 2049 | IPv4 | NHN Cloud NASサービスIPアドレス | csi-nfs-nodeのrpc nfsポート、方向: csi-nfs-node(worker node) -> NHN Cloud NASサービス |
| egress | TCP | 111 | IPv4 | NHN Cloud NASサービスIPアドレス | csi-nfs-nodeのrpc portmapperポート、方向: csi-nfs-node(worker node) -> NHN Cloud NASサービス |
| egress | TCP | 635 | IPv4 | NHN Cloud NASサービスIPアドレス | csi-nfs-nodeのrpc mountdポート、方向: csi-nfs-node(worker node) -> NHN Cloud NASサービス |
強化されたセキュリティルールを使用しない場合、NodePortタイプのサービスと外部ネットワーク通信に必要なセキュリティルールが追加で作成されます。
| 方向 | IPプロトコル | ポート範囲 | Ether | 遠隔 | 説明 |
|---|---|---|---|---|---|
| ingress | TCP | 1 - 65535 | IPv4 | ワーカーノード | すべてのポート、方向: worker node -> worker node |
| ingress | TCP | 1 - 65535 | IPv4 | マスターノード | すべてのポート、方向: NKS Control plane -> worker node |
| ingress | TCP | 30000 - 32767 | IPv4 | すべて許可 | NKS service object NodePort、方向: external -> worker node |
| ingress | UDP | 1 - 65535 | IPv4 | ワーカーノード | すべてのポート、方向: worker node -> worker node |
| ingress | UDP | 1 - 65535 | IPv4 | マスターノード | すべてのポート、方向: NKS Control plane -> worker node |
| egress | 任意 | 1 - 65535 | IPv4 | すべて許可 | すべてのポート、方向: worker node - > external |
| egress | 任意 | 1 - 65535 | IPv6 | すべて許可 | すべてのポート、方向: worker node - > external |
必要な情報を入力し、クラスター作成を押すと、クラスターの作成が始まります。クラスターリストで状態を確認できます。作成には約10分かかります。クラスターの設定によっては、さらに時間がかかる場合もあります。
クラスター照会
作成したクラスタはContainer > NHN Kubernetes Service(NKS)サービスページで確認できます。クラスタリストには各クラスタの簡単な情報が表示されます。
| 項目 | 説明 |
|---|---|
| クラスタ名 | クラスタの名前 |
| ノード数 | クラスタの全体ワーカーノード数 |
| Kubernetesバージョン | Kubernetesバージョン情報 |
| kubeconfigファイル | クラスタを制御するためのkubeconfigファイルのダウンロードボタン |
| 作業状態 | クラスタに出したコマンドの作業状態 |
| k8s API状態 | Kubernetes APIエンドポイントの動作状態 |
| k8s Node状態 | Kubernetes Nodeリソースの状態 |
作業状態のアイコン別の意味は次のとおりです。
| アイコン | 意味 |
|---|---|
| 緑色のソリッドアイコン | 作業正常終了 |
| 円形回転アイコン | 作業進行中 |
| 赤色のソリッドアイコン | 作業失敗 |
| 灰色のソリッドアイコン | クラスタ使用不可 |
k8s API状態のアイコン別の意味は次のとおりです。
| アイコン | 意味 |
|---|---|
| 緑色のソリッドアイコン | 正常動作中 |
| 黄色のソリッドアイコン | 情報の有効期間(5分)が残り少ないため、情報が正確ではない |
| 赤色のソリッドアイコン | Kubernetes APIエンドポイントが正常に動作していないか、情報の有効期限が切れている |
k8s Node状態のアイコン別の意味は次のとおりです。
| アイコン | 意味 |
|---|---|
| 緑色のソリッドアイコン | クラスタのすべてのノードがReady状態 |
| 黄色のソリッドアイコン | Kubernetes APIエンドポイントが正常に動作していないか、クラスタ内にNotReady状態のノードが存在する |
| 赤色のソリッドアイコン | クラスタのすべてのノードがNotReady状態 |
クラスタを選択すると、下部にクラスタ情報が表示されます。
| 項目 | 説明 |
|---|---|
| クラスター名 | Kubernetesクラスターの名前とID |
| ノード数 | クラスターを構成するすべてのノードインスタンス数 |
| Kubernetesバージョン | 使用中のKubernetesバージョン |
| CNI | 使用中のKubernetes CNI種類 |
| K8sサービスネットワーク | クラスタのservice object CIDR設定 |
| Podネットワーク | 使用中のKubernetes Podネットワーク設定 |
| Podサブネットサイズ | 使用中のKubernetes Podサブネットサイズ設定 |
| VPC | クラスターに接続したVPCネットワーク |
| サブネット | クラスターを構成するノードインスタンスに接続したサブネット |
| APIエンドポイント | クラスターにアクセスして操作するためのAPIエンドポイントURI |
| 設定ファイル | クラスターにアクセスして操作するために必要な設定ファイルのダウンロードボタン |
クラスター削除
削除するクラスターを選択し、クラスター削除を押すと削除が行われます。削除には約5分かかります。クラスターの状態によっては、さらに時間がかかる場合もあります。
クラスタOWNER変更
[参考] 基本的にクラスタOWNERはクラスタを作成したユーザーを意味しますが、状況に応じて他のユーザーに変更可能です。 クラスタは、作成時点のOWNER権限に基づいて動作します。 当該権限はKubernetesとNHN Cloud基本インフラサービスの連動過程で使用されます。 Kubernetesで使用する基本インフラサービスは次のとおりです。
| 基本インフラサービス | Kubernetesとの連動 |
|---|---|
| Compute | Kubernetesクラスタオートスケーラによるワーカーノード増設または縮小時にInstanceサービス使用 |
| Network | Kubernetes LoadBalancerサービス作成時にLoad BalancerおよびFloating IPサービス使用 |
| Storage | Kubernetesパシステントボリューム作成時にBlock Storageサービス使用 |
動作中に以下のような状況が発生する場合は、Kubernetesで基本インフラサービスを使用できなくなります。
| 状況 | 事例 |
|---|---|
| プロジェクトでクラスタOWNER離脱 | クラスタOWNERの退社によるプロジェクトメンバー削除または人為的なプロジェクトメンバー削除 |
| クラスタOWNERの権限変更 | クラスタ作成後に任意の権限追加または削除 |
上記のような理由でクラスタの運用に問題が発生し、メンバーや権限設定により正常化できない場合、NKSコンソールのクラスタOWNER変更機能を利用して正常化できます。 クラスタOWNER変更機能の使用方法は次のとおりです。
[参考]コンソールでクラスタOWNER変更作業を行うユーザーが対象クラスタの新しいOWNERになります。 OWNER変更作業完了後のクラスタは、新しいOWNERの権限に基づいて動作します。
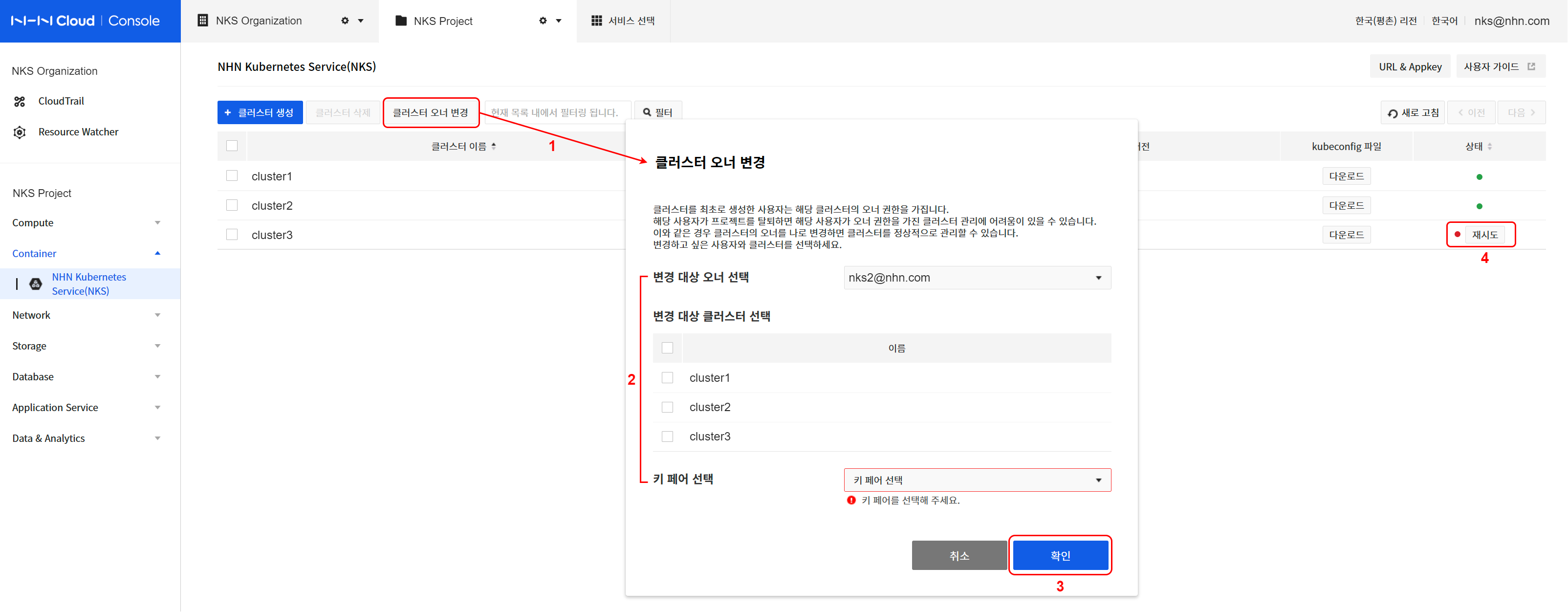
- クラスタオーナーの変更をクリックします。
- 変更対象オーナーおよびクラスタを指定します。
- 変更対象クラスタを特定するための現在のオーナーを指定します。
- 表示されたクラスタリストから変更対象を選択します。
- 新規ワーカーノード作成時に使用する自分のキーペアを指定します。
- オーナーの変更を行うには確認をクリックします。
- 変更対象クラスタの状態を確認します。
- NKSコンソールのクラスタリストで指定したクラスタの作業進行状態を確認します。
- OWNER変更作業進行中のクラスタの状態はHANDOVER_IN_PROGRESSです。正常に完了した場合はHANDOVER_COMPLETE状態に変わります。
- 該当クラスタ下位のすべてのノードグループもHANDOVER_* 状態に変わります。
- 作業に問題が発生した場合にはHANDOVER_FAILED状態に変わり、正常化するまでクラスタ形状変更作業(ノード追加など)は許可されません。
*このような状態のクラスタには状態アイコンの横に再試行ボタンが表示されます。
- クラスタ状態の正常化のために再試行をクリックし、キーペアを指定して確認をクリックします。
[注意]クラスタOWNERの変更とキーペア
NHN Cloud基本インフラサービスのキーペアリソースは、特定のユーザーに帰属し、他のユーザーと共有できません。 (NHN Cloudコンソールでキーペア作成後にダウンロードしたPEMファイルとは別) したがってクラスタを作成する時に指定されたキーペアリソースもクラスタOWNER変更時に新規OWNERのものとして新たに指定する必要があります。
クラスタOWNER変更後に作成されたワーカーノード(インスタンス)には、新しく指定されたキーペア(PEMファイル)を利用して接続できます。 しかし、OWNER変更前に作成されたワーカーノードに接続するには、既存OWNERのキーペア(PEMファイル)が必要です。 したがって、OWNERを変更しても、既存キーペア(PEMファイル)はプロジェクト管理者レベルで適切に管理する必要があります。
ノードグループ
ノードグループはKubernetesを構成するワーカーノードインスタンスのグループです。
ノードグループ照会
クラスタリストからクラスタ名を押すと、ノードグループリストを確認できます。ノードグループを選択すると、下部にノードグループ情報が表示されます。
| 項目 | 説明 |
|---|---|
| ノードグループ名 | ノードグループの名前 |
| ノード数 | ノードグループに属するノード数 |
| Kubernetesバージョン | ノードグループに適用されたKubernetesバージョン情報 |
| アベイラビリティゾーン | ノードグループに適用されたアベイラビリティゾーン情報 |
| インスタンスタイプ | ノードグループのインスタンスタイプ |
| イメージタイプ | ノードグループのイメージタイプ |
| 作業状態 | ノードグループに出したコマンドの作業状態 |
| k8s Node状態 | ノードグループに属するKubernetes Nodeリソースの状態 |
作業状態のアイコン別の意味は次のとおりです。
| アイコン | 意味 |
|---|---|
| 緑色のソリッドアイコン | 作業正常終了 |
| 円形回転アイコン | 作業進行中 |
| 赤色のソリッドアイコン | 作業失敗 |
| 灰色のソリッドアイコン | クラスタおよびノードグループ使用不可 |
k8s Node状態のアイコン別の意味は次のとおりです。
| アイコン | 意味 |
|---|---|
| 緑色のソリッドアイコン | ノードグループのすべてのノードがReady状態 |
| 黄色のソリッドアイコン | Kubernetes APIエンドポイントが正常に動作していないか、ノードグループ内にNotReady状態のノードが存在する |
| 赤色のソリッドアイコン | ノードグループのすべてのノードがNotReady状態 |
ノードグループを選択すると、下部にノードグループ情報が表示されます。
- 基本情報 基本情報タブでは、次のような情報を確認できます。
| 項目 | 説明 |
|---|---|
| ノードグループ名 | ノードグループ名とID |
| クラスター名 | ノードグループが属しているクラスターの名前とID |
| Kubernetesバージョン | 使用中のKubernetesバージョン |
| アベイラビリティゾーン | ノードグループインスタンスが作成された領域 |
| インスタンスタイプ | ノードグループインスタンスの仕様 |
| イメージタイプ | ノードグループインスタンスに使用したイメージの種類 |
| ブロックストレージサイズ | ノードグループインスタンスのブロックストレージサイズ |
| 作成日 | ノードグループが作成された日時 |
| 修正日 | ノードグループが最後に修正された日時 |
- ノードリスト ノードリストタブでは、ノードグループを構成するインスタンスのリストを確認できます。
ノードグループ作成
クラスターを作成すると、基本ノードグループが作成されますが、必要に応じて追加ノードグループを作成できます。基本ノードグループのインスタンスより高い仕様のコンテナ起動環境が必要な場合や、スケールアウト(scale out、拡張)のためにさらに多くのワーカーノードインスタンスが必要な場合は、追加ノードグループを作成して使用できます。ノードグループリストページでノードグループ作成ボタンを押すと、ノードグループ作成ページが表示されます。ノードグループの作成に必要な項目は次のとおりです。
| 項目 | 説明 |
|---|---|
| アベイラビリティゾーン | クラスターを構成するインスタンスを作成する領域 |
| ノードグループ名 | 追加ノードグループの名前。32文字以内で小文字と数字、(-)のみ入力可能です。小文字で始まり、小文字または数字で終わる必要があります。RFC 4122標準のUUID形式は使用できません。 |
| インスタンスタイプ | 追加ノードグループのインスタンス仕様 |
| ノード数 | 追加ノードグループインスタンス数 |
| キーペア | 追加ノードグループアクセスに使用するキーペア |
| ブロックストレージタイプ | 追加ノードグループインスタンスのブロックストレージ種類 |
| ブロックストレージサイズ | 追加ノードグループインスタンスのブロックストレージサイズ |
| 追加ネットワーク | 基本ワーカーノードグループに作成する追加ネットワーク/サブネット |
必要な情報を入力し、ノードグループ作成ボタンを押すと、ノードグループの作成が始まります。ノードグループリストで状態を確認できます。ノードグループの作成には約5分かかります。ノードグループの設定によっては、さらに時間がかかる場合もあります。
[注意] 該当クラスタを作成したユーザーのみノードグループを作成できます。
ノードグループ削除
ノードグループリストから削除するノードグループを選択し、ノードグループ削除ボタンを押すと、削除が行われます。ノードグループの削除には約5分かかります。ノードグループの状態によっては、さらに時間がかかる場合もあります。
ノードグループにノード追加
動作中のノードグループにノードを追加できます。ノードグループ情報照会ページのノードリストタブを押すと、現在のノードリストが表示されます。ノード追加ボタン押し、ノード数を入力するとノードが追加されます。
[注意] オートスケーラーが有効になっているノードグループは、手動でノードを追加できません。
ノードグループからノード削除
動作中のノードグループからノードを削除できます。ノードグループ情報照会ページのノードリストタブを押すと、現在のノードリストが表示されます。ノードリストの中から削除するノードを選択し、ノード削除ボタンを押すと、確認ダイアログボックスが表示されます。削除するノード名をもう一度確認して確認ボタンを押すとノードが削除されます。
[注意] 削除されるノードで動作していたPodは強制終了します。削除されるノードで動作中のPodを安全に他のノードへ移すにはdrainコマンドを実行する必要があります。ノードがdrainされた後も新しいPodはこのノードにスケジューリングされる場合があります。新しいPodが削除されるノードにスケジューリングされることを防止するにはcordonコマンドを実行する必要があります。ノードを安全に管理するためのより詳しい内容は、下記の文書を参照してください。
[注意] オートスケーラーが有効になっているノードグループは、手動でノードを削除できません。
ノードの停止と起動
ノードグループに属すノードのうち一部を停止させ、停止したノードを再度起動できます。ノードグループ情報照会ページのノードリストタブをクリックすると現在のノードリストが現れます。停止するノードを選択し、ノード停止ボタンをクリックするとノードが停止します。停止したノードを選択し、ノード起動ボタンをクリックするとノードが再び起動します。
動作プロセス
起動状態のノードを停止すると次の順序で動作します。
- 当該ノードがdrainされます。
- 当該ノードがKubernetesノードリソースから削除されます。
- 当該ノードをインスタンスレベルでSHUTDOWN状態にします。
停止状態のノードを起動すると、次の順序で動作します。 * 当該ノードをインスタンスレベルでACTIVE状態にします。 * 当該ノードがKubernetesノードリソースに再び追加されます。
制約事項
ノードの停止と起動機能は、次の制約事項があります。
- 起動状態のノードを停止することができ、停止状態のノードを起動することができます。
- ワーカーノードグループ内のすべてのノードを停止することはできません。
- オートスケーラーが有効になっているノードグループはノードを停止できません。
- 停止したノードが存在するノードグループはオートスケーラーを有効にできません。
- 停止したノードが存在するノードグループはアップグレードできません。
状態表示
ノードの状態に基づいてノードリストタブの状態アイコンが表示されます。アイコンの各色の状態は次のとおりです。
- 緑色:起動状態のノード
- 灰色:停止状態のノード
- 赤色:異常状態のノード
GPUノードグループ使用
KubernetesでGPU基盤ワークロードの実行が必要な場合、 GPUインスタンスで構成されたノードグループを作成できます。
クラスターまたはノードグループ作成プロセスでインスタンスタイプを選択する時、 g2タイプを選択するとGPUノードグループを作成できます。
[参考] NHN Cloud GPUインスタンスで提供されるGPUはNVIDIA系です。 (使用可能なGPUの仕様を確認) NVIDIA GPUを利用するために必要なKubernetesのnvidia-device-pluginは、GPUノードグループの作成時に自動的にインストールされます。
作成されたGPUノードの基本的な設定のヘルスチェックおよび簡単な動作テストは次のような方法を利用できます。
ノード水準のヘルスチェック
GPUノードに接続した後、nvidia-smiコマンドを実行します。
次のような内容が出力されればGPU driverが正常に動作しているということです。
$ nvidia-smi
Mon Jul 27 14:38:07 2020
+-----------------------------------------------------------------------------+
| NVIDIA-SMI 418.152.00 Driver Version: 418.152.00 CUDA Version: 10.1 |
|-------------------------------+----------------------+----------------------+
| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
|===============================+======================+======================|
| 0 Tesla T4 Off | 00000000:00:05.0 Off | 0 |
| N/A 30C P8 9W / 70W | 0MiB / 15079MiB | 0% Default |
+-------------------------------+----------------------+----------------------+
+-----------------------------------------------------------------------------+
| Processes: GPU Memory |
| GPU PID Type Process name Usage |
|=============================================================================|
| No running processes found |
+-----------------------------------------------------------------------------+
Kubernetes水準のヘルスチェック
kubectlコマンドを使用してクラスター水準で使用可能なGPUリソース情報を確認します。
以下は各ノードで使用可能なGPUコアの個数を出力するコマンドおよび実行結果です。
$ kubectl get nodes -A -o custom-columns='NAME:.metadata.name,GPU Allocatable:.status.allocatable.nvidia\.com/gpu,GPU Capacity:.status.capacity.nvidia\.com/gpu'
NAME GPU Allocatable GPU Capacity
my-cluster-default-w-vdqxpwisjjsk-node-1 1 1
GPUテストのためのサンプルワークロード実行
Kubernetesクラスターに属すGPUノードはCPUとメモリの他にnvidia.com/gpuという名前のリソースを提供します。
GPUを使用したい場合はnvidia.com/gpuリソースを割り当てられるように、下記のサンプルファイルのように入力してください。
- resnet.yaml
apiVersion: v1
kind: Pod
metadata:
name: resnet-gpu-pod
spec:
imagePullSecrets:
- name: nvcr.dgxkey
containers:
- name: resnet
image: nvcr.io/nvidia/tensorflow:18.07-py3
command: ["mpiexec"]
args: ["--allow-run-as-root", "--bind-to", "socket", "-np", "1", "python", "/opt/tensorflow/nvidia-examples/cnn/resnet.py", "--layers=50", "--precision=fp16", "--batch_size=64", "--num_iter=90"]
resources:
limits:
nvidia.com/gpu: 1
上記のファイルを実行すると次のような結果を確認できます。
$ kubectl create -f resnet.yaml
pod/resnet-gpu-pod created
$ kubectl get pods resnet-gpu-pod
NAME READY STATUS RESTARTS AGE
resnet-gpu-pod 0/1 Running 0 17s
$ kubectl logs resnet-gpu-pod -n default -f
PY 3.5.2 (default, Nov 23 2017, 16:37:01)
[GCC 5.4.0 20160609]
TF 1.8.0
Script arguments:
--layers 50
--display_every 10
--iter_unit epoch
--batch_size 64
--num_iter 100
--precision fp16
Training
WARNING:tensorflow:Using temporary folder as model directory: /tmp/tmpjw90ypze
2020-07-31 00:57:23.020712: I tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:898] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero
2020-07-31 00:57:23.023190: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1356] Found device 0 with properties:
name: Tesla T4 major: 7 minor: 5 memoryClockRate(GHz): 1.59
pciBusID: 0000:00:05.0
totalMemory: 14.73GiB freeMemory: 14.62GiB
2020-07-31 00:57:23.023226: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1435] Adding visible gpu devices: 0
2020-07-31 00:57:23.846680: I tensorflow/core/common_runtime/gpu/gpu_device.cc:923] Device interconnect StreamExecutor with strength 1 edge matrix:
2020-07-31 00:57:23.846743: I tensorflow/core/common_runtime/gpu/gpu_device.cc:929] 0
2020-07-31 00:57:23.846753: I tensorflow/core/common_runtime/gpu/gpu_device.cc:942] 0: N
2020-07-31 00:57:23.847023: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1053] Created TensorFlow device (/job:localhost/replica:0/task:0/device:GPU:0 with 14151 MB memory) -> physical GPU (device: 0, name: Tesla T4, pci bus id: 0000:00:05.0, compute capability: 7.5)
Step Epoch Img/sec Loss LR
1 1.0 3.1 7.936 8.907 2.00000
10 10.0 68.3 1.989 2.961 1.65620
20 20.0 214.0 0.002 0.978 1.31220
30 30.0 213.8 0.008 0.979 1.00820
40 40.0 210.8 0.095 1.063 0.74420
50 50.0 211.9 0.261 1.231 0.52020
60 60.0 211.6 0.104 1.078 0.33620
70 70.0 211.3 0.340 1.317 0.19220
80 80.0 206.7 0.168 1.148 0.08820
90 90.0 210.4 0.092 1.073 0.02420
100 100.0 210.4 0.001 0.982 0.00020
[参考] GPUが必要ないワークロードがGPUノードに割り当てられることを防ぎたい場合はTaintおよびTolerationの概要を参照してください。
オートスケーラー
オートスケーラーはノードグループの可用リソースが足りなくてPodをスケジューリングできなかったり、ノードの使用率が一定水準以下で維持する時、ノードの数を自動的に調整する機能です。この機能はノードグループごとに設定することができ、独立して動作します。この機能はKubernetesプロジェクトの公式サポート機能であるcluster-autoscaler機能をベースにします。詳細な事項はCluster Autoscalerを参照してください。
[参考] NHN Kubernetes Service(NKS)に適用された
cluster-autoscalerのバージョンは1.19.0です。
用語整理
オートスケーラー機能で使用する用語とその意味は次のとおりです。
| 用語 | 意味 |
|---|---|
| 増設 | ノードの数を増加させることです。 |
| 削除 | ノードの数を減らすことです。 |
[注意] ワーカーノードがインターネットに接続できない環境で動作している場合、オートスケーラーコンテナイメージをワーカーノードに直接インストールする必要があります。この作業が必要な対象は次のとおりです。
- パンギョリージョン:2020年11月24日以前に作成したノードグループ
- 坪村リージョン:2020年11月19日以前に作成したノードグループ
オートスケーラーのコンテナイメージパスは次のとおりです。
- k8s.gcr.io/autoscaling/cluster-autoscaler:v1.19.0
オートスケーラー設定
オートスケーラー機能はノードグループごとに設定して動作します。オートスケーラー機能は下記の方法で設定できます。
- クラスター作成時、基本ノードグループに設定
- ノードグループを追加する時、追加ノードグループに設定
- 作成されているノードグループに設定
オートスケーラーを有効にすると、下記の項目を設定できます。
| 設定項目 | 意味 | 有効範囲 | デフォルト値 | 単位 |
|---|---|---|---|---|
| 最小ノード数 | 削除可能な最小ノード数 | 1-10 | 1 | 台 |
| 最大ノード数 | 増設可能な最大ノード数 | 1-10 | 10 | 台 |
| 削除 | ノードの削除を行うかどうかの設定 | 有効/無効 | 有効 | - |
| リソース使用量しきい値 | 削除の基準であるリソース使用量しきい値の基準値 | 1-100 | 50 | % |
| しきい値維持時間 | 削除対象になるノードのしきい値以下のリソース使用量維持時間 | 1-1440 | 10 | 分 |
| 増設後の遅延時間 | ノード増設後、削除対象ノードでモニタリングを開始するまでの遅延時間 | 10-1440 | 10 | 分 |
[注意] オートスケーラーが有効になっているノードグループは手動でノードを追加または削除できません。
増設および削除条件
下記の条件を全て満たすとノードを増設します。
- Podがスケジューリングできるノードがない
- 現在のノード数が最大ノード数より少ない
下記の条件を全て満たすとノードを減らします。
- ノードのリソース使用量がしきい値以下をしきい値維持時間継続
- 現在のノード数が最小ノード数より多い
特定のノードに下記の条件を満たすPodが1つでも存在する場合は、そのノードはノード削除候補から除外されます。
- "PodDisruptionBudget"で制約を受けるPod
- "kube-system"名前空間のPod
- "deployment"、"replicaset"などの制御オブジェクトにより始まっていないPod
- ローカルストレージを使用するPod
- "node selector"などの制約により他のノードに移動できないPod
増設および削除条件の詳細はCluster Autoscaler FAQを参照してください。
動作例
オートスケーラーの動作を例を用いて確認します。
1. オートスケーラー有効化
対象クラスターの基本ノードグループのオートスケーラー機能を有効化します。この例では、基本ノードグループのノード数を1で作成し、オートスケーラー設定項目は下記のように設定しました。
| 設定項目 | 設定値 |
|---|---|
| 最小ノード数 | 1 |
| 最大ノード数 | 5 |
| 削除 | 有効 |
| リソース使用量しきい値 | 50 |
| しきい値維持時間 | 3 |
| 増設後の遅延時間 | 5 |
2. Pod配布
下記のマニフェストでPodを配布します。
[注意] このマニフェストのようにコンテナのリソースリクエストが明示されている必要があります。
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-deployment
labels:
app: nginx
spec:
replicas: 15
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx:1.14.2
ports:
- containerPort: 80
resources:
requests:
cpu: "100m"
配布リクエストしたPodのCPUリソースの合計がノード1つのリソースより大きいため、以下のように複数のPodがPending状態になります。この状況でノードの増設が発生します。
# kubectl get pods
NAME READY STATUS RESTARTS AGE
nginx-deployment-756fd4cdf-5gftm 1/1 Running 0 34s
nginx-deployment-756fd4cdf-64gtv 0/1 Pending 0 34s
nginx-deployment-756fd4cdf-7bsst 0/1 Pending 0 34s
nginx-deployment-756fd4cdf-8892p 1/1 Running 0 34s
nginx-deployment-756fd4cdf-8k4cc 1/1 Running 0 34s
nginx-deployment-756fd4cdf-cprp7 0/1 Pending 0 34s
nginx-deployment-756fd4cdf-cvs97 1/1 Running 0 34s
nginx-deployment-756fd4cdf-h7ftk 1/1 Running 0 34s
nginx-deployment-756fd4cdf-hv2fz 0/1 Pending 0 34s
nginx-deployment-756fd4cdf-j789l 0/1 Pending 0 34s
nginx-deployment-756fd4cdf-jrkfj 0/1 Pending 0 34s
nginx-deployment-756fd4cdf-m887q 0/1 Pending 0 34s
nginx-deployment-756fd4cdf-pvnfc 0/1 Pending 0 34s
nginx-deployment-756fd4cdf-wrj8b 1/1 Running 0 34s
nginx-deployment-756fd4cdf-x7ns5 0/1 Pending 0 34s
3. ノード増設確認
以下は、増設前のノードリストです。
# kubectl get nodes
NAME STATUS ROLES AGE VERSION
autoscaler-test-default-w-ohw5ab5wpzug-node-0 Ready <none> 45m v1.23.3
約5~10分後、以下のようにノードが増設されたことを確認できます。
# kubectl get nodes
NAME STATUS ROLES AGE VERSION
autoscaler-test-default-w-ohw5ab5wpzug-node-0 Ready <none> 48m v1.23.3
autoscaler-test-default-w-ohw5ab5wpzug-node-1 Ready <none> 77s v1.23.3
autoscaler-test-default-w-ohw5ab5wpzug-node-2 Ready <none> 78s v1.23.3
Pending状態だったPodがノード増設後に正常スケジューリングされたことを確認できます。
# kubectl get pods -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
nginx-deployment-756fd4cdf-5gftm 1/1 Running 0 4m29s 10.100.8.13 autoscaler-test-default-w-ohw5ab5wpzug-node-0 <none> <none>
nginx-deployment-756fd4cdf-64gtv 1/1 Running 0 4m29s 10.100.22.5 autoscaler-test-default-w-ohw5ab5wpzug-node-1 <none> <none>
nginx-deployment-756fd4cdf-7bsst 1/1 Running 0 4m29s 10.100.22.4 autoscaler-test-default-w-ohw5ab5wpzug-node-1 <none> <none>
nginx-deployment-756fd4cdf-8892p 1/1 Running 0 4m29s 10.100.8.10 autoscaler-test-default-w-ohw5ab5wpzug-node-0 <none> <none>
nginx-deployment-756fd4cdf-8k4cc 1/1 Running 0 4m29s 10.100.8.12 autoscaler-test-default-w-ohw5ab5wpzug-node-0 <none> <none>
nginx-deployment-756fd4cdf-cprp7 1/1 Running 0 4m29s 10.100.12.7 autoscaler-test-default-w-ohw5ab5wpzug-node-2 <none> <none>
nginx-deployment-756fd4cdf-cvs97 1/1 Running 0 4m29s 10.100.8.14 autoscaler-test-default-w-ohw5ab5wpzug-node-0 <none> <none>
nginx-deployment-756fd4cdf-h7ftk 1/1 Running 0 4m29s 10.100.8.11 autoscaler-test-default-w-ohw5ab5wpzug-node-0 <none> <none>
nginx-deployment-756fd4cdf-hv2fz 1/1 Running 0 4m29s 10.100.12.5 autoscaler-test-default-w-ohw5ab5wpzug-node-2 <none> <none>
nginx-deployment-756fd4cdf-j789l 1/1 Running 0 4m29s 10.100.22.6 autoscaler-test-default-w-ohw5ab5wpzug-node-1 <none> <none>
nginx-deployment-756fd4cdf-jrkfj 1/1 Running 0 4m29s 10.100.12.4 autoscaler-test-default-w-ohw5ab5wpzug-node-2 <none> <none>
nginx-deployment-756fd4cdf-m887q 1/1 Running 0 4m29s 10.100.22.3 autoscaler-test-default-w-ohw5ab5wpzug-node-1 <none> <none>
nginx-deployment-756fd4cdf-pvnfc 1/1 Running 0 4m29s 10.100.12.6 autoscaler-test-default-w-ohw5ab5wpzug-node-2 <none> <none>
nginx-deployment-756fd4cdf-wrj8b 1/1 Running 0 4m29s 10.100.8.15 autoscaler-test-default-w-ohw5ab5wpzug-node-0 <none> <none>
nginx-deployment-756fd4cdf-x7ns5 1/1 Running 0 4m29s 10.100.12.3 autoscaler-test-default-w-ohw5ab5wpzug-node-2 <none> <none>
ノード増設イベントは、以下のコマンドで確認できます。
# kubectl get events --field-selector reason="TriggeredScaleUp"
LAST SEEN TYPE REASON OBJECT MESSAGE
4m Normal TriggeredScaleUp pod/nginx-deployment-756fd4cdf-64gtv pod triggered scale-up: [{default-worker-bf5999ab 1->3 (max: 5)}]
4m Normal TriggeredScaleUp pod/nginx-deployment-756fd4cdf-7bsst pod triggered scale-up: [{default-worker-bf5999ab 1->3 (max: 5)}]
...
4. Pod削除後、ノード削除確認
配布されているデプロイメント(deployment)を削除すると、配布されていたPodが削除されます。
# kubectl get pods
NAME READY STATUS RESTARTS AGE
nginx-deployment-756fd4cdf-5gftm 0/1 Terminating 0 20m
nginx-deployment-756fd4cdf-64gtv 0/1 Terminating 0 20m
nginx-deployment-756fd4cdf-7bsst 0/1 Terminating 0 20m
nginx-deployment-756fd4cdf-8892p 0/1 Terminating 0 20m
nginx-deployment-756fd4cdf-8k4cc 0/1 Terminating 0 20m
nginx-deployment-756fd4cdf-cprp7 0/1 Terminating 0 20m
nginx-deployment-756fd4cdf-h7ftk 0/1 Terminating 0 20m
nginx-deployment-756fd4cdf-hv2fz 0/1 Terminating 0 20m
nginx-deployment-756fd4cdf-j789l 0/1 Terminating 0 20m
nginx-deployment-756fd4cdf-jrkfj 0/1 Terminating 0 20m
nginx-deployment-756fd4cdf-m887q 0/1 Terminating 0 20m
nginx-deployment-756fd4cdf-pvnfc 0/1 Terminating 0 20m
nginx-deployment-756fd4cdf-wrj8b 0/1 Terminating 0 20m
nginx-deployment-756fd4cdf-x7ns5 0/1 Terminating 0 20m
#
# kubectl get pods
No resources found in default namespace.
#
監視後、ノード削除が発生してノード数が1個に減っていることを確認できます。ノード削除にかかる時間は設定によって異なります。
# kubectl get nodes
NAME STATUS ROLES AGE VERSION
autoscaler-test-default-w-ohw5ab5wpzug-node-0 Ready <none> 71m v1.23.3
ノード削除イベントは、下記のコマンドで確認できます。
# kubectl get events --field-selector reason="ScaleDown"
LAST SEEN TYPE REASON OBJECT MESSAGE
13m Normal ScaleDown node/autoscaler-test-default-w-ohw5ab5wpzug-node-1 node removed by cluster autoscaler
13m Normal ScaleDown node/autoscaler-test-default-w-ohw5ab5wpzug-node-2 node removed by cluster autoscaler
各ノードグループのオートスケーラーの状態情報はconfigmap/cluster-autoscaler-statusで確認できます。このconfigmapはノードグループごとに別々の名前空間に作成されます。オートスケーラーが作成する各ノードグループの名前空間の名前ルールは次のとおりです。
- 形式:nhn-ng-{ノードグループ名}
- {ノードグループ名}にはノードグループの名前が入ります。
- 基本ノードグループのノードグループ名は"default-worker"です。
基本ノードグループのオートスケーラーの状態情報を確認する方法は次のとおりです。より詳細な情報はCluster Autoscaler FAQを参照してください。
# kubectl get configmap/cluster-autoscaler-status -n nhn-ng-default-worker -o yaml
apiVersion: v1
data:
status: |+
Cluster-autoscaler status at 2020-11-03 12:39:12.190150095 +0000 UTC:
Cluster-wide:
Health: Healthy (ready=1 unready=0 notStarted=0 longNotStarted=0 registered=1 longUnregistered=0)
LastProbeTime: 2020-11-03 12:39:12.185954244 +0000 UTC m=+43.664545435
LastTransitionTime: 2020-11-03 12:38:41.705407217 +0000 UTC m=+13.183998415
ScaleUp: NoActivity (ready=1 registered=1)
LastProbeTime: 2020-11-03 12:39:12.185954244 +0000 UTC m=+43.664545435
LastTransitionTime: 2020-11-03 12:38:41.705407217 +0000 UTC m=+13.183998415
ScaleDown: NoCandidates (candidates=0)
LastProbeTime: 2020-11-03 12:39:12.185954244 +0000 UTC m=+43.664545435
LastTransitionTime: 2020-11-03 12:38:41.705407217 +0000 UTC m=+13.183998415
NodeGroups:
Name: default-worker-f9a9ee5e
Health: Healthy (ready=1 unready=0 notStarted=0 longNotStarted=0 registered=1 longUnregistered=0 cloudProviderTarget=1 (minSize=1, maxSize=5))
LastProbeTime: 2020-11-03 12:39:12.185954244 +0000 UTC m=+43.664545435
LastTransitionTime: 2020-11-03 12:38:41.705407217 +0000 UTC m=+13.183998415
ScaleUp: NoActivity (ready=1 cloudProviderTarget=1)
LastProbeTime: 2020-11-03 12:39:12.185954244 +0000 UTC m=+43.664545435
LastTransitionTime: 2020-11-03 12:38:41.705407217 +0000 UTC m=+13.183998415
ScaleDown: NoCandidates (candidates=0)
LastProbeTime: 2020-11-03 12:39:12.185954244 +0000 UTC m=+43.664545435
LastTransitionTime: 2020-11-03 12:38:41.705407217 +0000 UTC m=+13.183998415
kind: ConfigMap
metadata:
annotations:
cluster-autoscaler.kubernetes.io/last-updated: 2020-11-03 12:39:12.190150095 +0000
UTC
creationTimestamp: "2020-11-03T12:38:28Z"
name: cluster-autoscaler-status
namespace: nhn-ng-default-worker
resourceVersion: "1610"
selfLink: /api/v1/namespaces/nhn-ng-default-worker/configmaps/cluster-autoscaler-status
uid: e72bd1a2-a56f-41b4-92ee-d11600386558
[参考] 状態情報の内容のうち、
Cluster-wide領域の内容はNodeGroups領域の内容と同じです。
HPA(HorizontalPodAutoscale)機能と連携した動作例
HPA(Horizontal Pod Autoscaler)機能はCPU使用量などのリソース使用量を監視してレプリケーションコントローラー(ReplicationController)、デプロイメント(Deployment)、レプリカセット(ReplicaSet)、ステートフルセット(StatefulSet)のPod数を自動的にスケールします。Pod数を調節しているとノードに可用リソースが不足したりリソースが多く残る状況が発生する場合があります。この時、オートスケーラー機能と連携してノードの数を増やしたり減らすことができます。この例ではHPA機能とオートスケーラー機能を連携して動作することを示しています。HPAの詳細な説明はHorizontal Pod Autoscaler文書を参照してください。
1. オートスケーラー有効化
上の例のようにオートスケーラーを有効化します。
2. HPA設定
Webリクエストを受けると一定時間CPU負荷を作成するコンテナを配布します。そしてサービスを表示させます。次はphp-apache.yamlファイルの内容です。
apiVersion: apps/v1
kind: Deployment
metadata:
name: php-apache
spec:
selector:
matchLabels:
run: php-apache
replicas: 1
template:
metadata:
labels:
run: php-apache
spec:
containers:
- name: php-apache
image: k8s.gcr.io/hpa-example
ports:
- containerPort: 80
resources:
limits:
cpu: 500m
requests:
cpu: 200m
---
apiVersion: v1
kind: Service
metadata:
name: php-apache
labels:
run: php-apache
spec:
ports:
- port: 80
selector:
run: php-apache
# kubectl apply -f php-apache.yaml
deployment.apps/php-apache created
service/php-apache created
HPAを設定します。上で作成したphp-apache deploymentオブジェクトに対して最小Pod数1、最大Pod数、目標CPU loadは50%に設定します。
# kubectl autoscale deployment php-apache --cpu-percent=50 --min=1 --max=30
horizontalpodautoscaler.autoscaling/php-apache autoscaled
HPAの状態を照会すると、設定値と現在の状態を確認できます。まだCPU負荷をかけるweb requestを送っていないためCPU loadが0%です。
# kubectl get hpa
NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE
php-apache Deployment/php-apache 0%/50% 1 30 1 80s
3. 負荷認可
新しいターミナルで負荷をかけるPodを実行します。このPodは無限にWebリクエストを送ります。Ctrl+Cで止めることができます。
# kubectl run -i --tty load-generator --rm --image=busybox --restart=Never -- /bin/sh -c "while sleep 0.01; do wget -q -O- http://php-apache; done"
If you don't see a command prompt, try pressing enter.
OK!OK!OK!OK!OK!OK!OK!
kubectl top nodesコマンドを利用してノードの現在リソース使用量を確認できます。負荷をかけるPod実行後、時間が経つとCPU負荷が大きくなることを確認できます。
# kubectl top nodes
NAME CPU(cores) CPU% MEMORY(bytes) MEMORY%
autoscaler-test-default-w-ohw5ab5wpzug-node-0 66m 6% 1010Mi 58%
(しばらくすると)
# kubectl top nodes
NAME CPU(cores) CPU% MEMORY(bytes) MEMORY%
autoscaler-test-default-w-ohw5ab5wpzug-node-0 574m 57% 1013Mi 58%
HPAの状態を照会するとCPU loadが増加して、これを合わせるためにREPLICAS(=Pod数)の数が増えたことを確認できます。
# kubectl get hpa
NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE
php-apache Deployment/php-apache 250%/50% 1 30 5 2m44s
4. オートスケーラー動作確認
Podを照会するとPodの数が増えて一部Podはnode-0にスケジューリングされてRunning状態になりますが、一部はPending状態になっていることを確認できます。
# kubectl get pods -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
load-generator 1/1 Running 0 2m 10.100.8.39 autoscaler-test-default-w-ohw5ab5wpzug-node-0 <none> <none>
php-apache-79544c9bd9-6f7nm 0/1 Pending 0 65s <none> <none> <none> <none>
php-apache-79544c9bd9-82xkn 1/1 Running 0 80s 10.100.8.41 autoscaler-test-default-w-ohw5ab5wpzug-node-0 <none> <none>
php-apache-79544c9bd9-cjj9q 0/1 Pending 0 80s <none> <none> <none> <none>
php-apache-79544c9bd9-k6nnt 1/1 Running 0 4m27s 10.100.8.38 autoscaler-test-default-w-ohw5ab5wpzug-node-0 <none> <none>
php-apache-79544c9bd9-mplnn 0/1 Pending 0 19s <none> <none> <none> <none>
php-apache-79544c9bd9-t2knw 1/1 Running 0 80s 10.100.8.40 autoscaler-test-default-w-ohw5ab5wpzug-node-0 <none> <none>
Podをスケジューリングできない状況がオートスケーラーのノード増設条件です。 Cluster Autoscaler Podが提供する状態情報を照会するとScaleUpがInProgress状態になったことを確認できます。
# kubectl get cm/cluster-autoscaler-status -n nhn-ng-default-worker -o yaml
apiVersion: v1
data:
status: |+
Cluster-autoscaler status at 2020-11-24 13:00:40.210137143 +0000 UTC:
Cluster-wide:
Health: Healthy (ready=1 unready=0 notStarted=0 longNotStarted=0 registered=1 longUnregistered=0)
LastProbeTime: 2020-11-24 13:00:39.930763305 +0000 UTC m=+1246178.729396969
LastTransitionTime: 2020-11-10 02:51:14.353177175 +0000 UTC m=+13.151810823
ScaleUp: InProgress (ready=1 registered=1)
LastProbeTime: 2020-11-24 13:00:39.930763305 +0000 UTC m=+1246178.729396969
LastTransitionTime: 2020-11-24 12:58:34.83642035 +0000 UTC m=+1246053.635054003
ScaleDown: NoCandidates (candidates=0)
LastProbeTime: 2020-11-24 13:00:39.930763305 +0000 UTC m=+1246178.729396969
LastTransitionTime: 2020-11-20 01:42:32.287146552 +0000 UTC m=+859891.085780205
NodeGroups:
Name: default-worker-bf5999ab
Health: Healthy (ready=1 unready=0 notStarted=0 longNotStarted=0 registered=1 longUnregistered=0 cloudProviderTarget=2 (minSize=1, maxSize=3))
LastProbeTime: 2020-11-24 13:00:39.930763305 +0000 UTC m=+1246178.729396969
LastTransitionTime: 2020-11-10 02:51:14.353177175 +0000 UTC m=+13.151810823
ScaleUp: InProgress (ready=1 cloudProviderTarget=2)
LastProbeTime: 2020-11-24 13:00:39.930763305 +0000 UTC m=+1246178.729396969
LastTransitionTime: 2020-11-24 12:58:34.83642035 +0000 UTC m=+1246053.635054003
ScaleDown: NoCandidates (candidates=0)
LastProbeTime: 2020-11-24 13:00:39.930763305 +0000 UTC m=+1246178.729396969
LastTransitionTime: 2020-11-20 01:42:32.287146552 +0000 UTC m=+859891.085780205
...
しばらくするとノード(node-8)が1つ増えていることを確認できます。
# kubectl get nodes
NAME STATUS ROLES AGE VERSION
autoscaler-test-default-w-ohw5ab5wpzug-node-0 Ready <none> 22d v1.23.3
autoscaler-test-default-w-ohw5ab5wpzug-node-8 Ready <none> 90s v1.23.3
Pending状態だったPodが全て正常スケジューリングされてRunning状態になったことを確認できます。
# kubectl get pods -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
load-generator 1/1 Running 0 5m32s 10.100.8.39 autoscaler-test-default-w-ohw5ab5wpzug-node-0 <none> <none>
php-apache-79544c9bd9-6f7nm 1/1 Running 0 4m37s 10.100.42.3 autoscaler-test-default-w-ohw5ab5wpzug-node-8 <none> <none>
php-apache-79544c9bd9-82xkn 1/1 Running 0 4m52s 10.100.8.41 autoscaler-test-default-w-ohw5ab5wpzug-node-0 <none> <none>
php-apache-79544c9bd9-cjj9q 1/1 Running 0 4m52s 10.100.42.5 autoscaler-test-default-w-ohw5ab5wpzug-node-8 <none> <none>
php-apache-79544c9bd9-k6nnt 1/1 Running 0 7m59s 10.100.8.38 autoscaler-test-default-w-ohw5ab5wpzug-node-0 <none> <none>
php-apache-79544c9bd9-mplnn 1/1 Running 0 3m51s 10.100.42.4 autoscaler-test-default-w-ohw5ab5wpzug-node-8 <none> <none>
php-apache-79544c9bd9-t2knw 1/1 Running 0 4m52s 10.100.8.40 autoscaler-test-default-w-ohw5ab5wpzug-node-0 <none> <none>
負荷のために実行しておいたPod(load-generator)をCtrl+Cで中断させてしばらくすると負荷が減ります。負荷が減るとPodが占有していたCPU使用量が減ってPodの数が減ります。
# kubectl get hpa
NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE
php-apache Deployment/php-apache 0%/50% 1 30 1 31m
Podの数が減ってノードのリソース使用量が減るとノードが縮小します。新たに追加されたnode-8が縮小したことを確認できます。
# kubectl get nodes
NAME STATUS ROLES AGE VERSION
autoscaler-test-default-w-ohw5ab5wpzug-node-0 Ready <none> 22d v1.23.3
ユーザースクリプト(old)
クラスタを作成する時と追加ノードグループを作成する時、ユーザースクリプトを登録できます。ユーザースクリプト機能には次のような特徴があります。
- 機能設定
- この機能はワーカーノードグループごとに設定できます。
- クラスタ作成時に入力したユーザースクリプトは基本ワーカーノードグループに適用されます。
- 追加ノードグループの作成時に入力したユーザースクリプトは該当ワーカーノードグループに適用されます。
- ワーカーノードグループが作成された後はユーザースクリプトの内容を変更できません。
- スクリプト実行タイミング
- ユーザースクリプトはワーカーノード初期化プロセスのうち、インスタンス初期化プロセスで実行されます。
- ユーザースクリプトが実行された後、そのインスタンスを「ワーカーノードグループ」のワーカーノードに設定して登録します。
- スクリプト内容
- ユーザースクリプトの最初の行は必ず#!で始まる必要があります。
- スクリプトの最大サイズは64KBです。
- スクリプトはroot権限で実行されます。
- スクリプトの実行記録は以下の位置に保存されます。
- スクリプト終了コード:
/var/log/userscript.exitcode - スクリプト標準出力および標準エラーストリーム:
/var/log/userscript.output
- スクリプト終了コード:
ユーザースクリプト
2022年7月26日以降に作成されるノードグループには新しいバージョンのユーザースクリプト機能が搭載されます。以前のバージョンの機能と比較して次のような特徴があります。
- ワーカーノードグループが作成された後もユーザースクリプトの内容を変更できます。
- ただし、変更された内容はユーザースクリプト変更後に作成されるノードにのみ適用されます。
-
スクリプト実行記録は次の位置に保存されます。
- スクリプト終了コード:
/var/log/userscript_v2.exitcode - スクリプト標準出力および標準エラーストリーム:
/var/log/userscript_v2.output
- スクリプト終了コード:
-
以前のバージョンとの関係
- 新規バージョンの機能が以前のバージョンの機能を代替します。
- コンソール、 APIを介してノードグループを作成するとき、設定したユーザースクリプトは新規バージョンの機能に設定されます。
- 以前のバージョンのユーザースクリプトを設定したワーカーノードグループは、以前のバージョンの機能と新規バージョンの機能が別々に動作します。
- 以前のバージョンで設定したユーザースクリプトの内容は変更できません。
- 新規バージョンで設定したユーザースクリプトの内容は変更できます。
- 以前のバージョンと新規バージョンにそれぞれユーザースクリプトを設定すると、次の順序で実行されます。
- 以前のバージョンのユーザースクリプト
- 新規バージョンのユーザースクリプト
- 新規バージョンの機能が以前のバージョンの機能を代替します。
インスタンスタイプの変更
ワーカーノードグループのインスタンスタイプを変更します。ワーカーノードグループに属す全てのワーカーノードのインスタンスタイプが変更されます。
進行プロセス
インスタンスタイプの変更は次の順序で行います。
- クラスタオートスケーラ機能を無効化します。
- 該当ワーカーノードグループにバッファノードを追加します。
- ワーカーノードグループ内のすべてのワーカーノードに対して以下の業を順次実行します。
- 該当ワーカーノードで動作中のPodを追放し、ノードをスケジュール不可能な状態に切り替えます。
- ワーカーノードのインスタンスタイプを変更します。
- ノードをスケジュール可能な状態に切り替えます。
- バッファノードで動作中のPodを追放し、バッファノードを削除します。
- クラスタオートスケーラ機能を再度有効にします。
インスタンスタイプの変更は、ワーカーコンポーネントアップグレードと同様の方法で行われます。バッファノードの作成と削除、Podの追放についてはクラスタアップグレードを参照してください。
制約事項
インスタンスの現在タイプによって変更できるタイプが異なります。
- m2、c2、r2、t2、x1タイプのインスタンスはm2、c2、r2、t2、x1タイプに変更できます。
- m2、c2、r2、t2、x1、g2タイプのインスタンスはu2タイプに変更できません。
- u2タイプのインスタンスは作成後にタイプを変更できません。同じu2タイプへの変更もできません。
カスタムイメージをワーカーイメージとして活用
ユーザーのカスタムイメージをベースにしたウォーカーノードグループを作成することができます。カスタムイメージがワーカーノードイメージとして活用できるようにNHN Cloud Image Builderサービスで追加作業(NKSワーカーノード化)が必要です。 Image BuilderサービスでNHN Kubernetes Service(NKS)ワーカーノードアプリケーションでイメージテンプレートを作成してカスタムワーカーノードイメージを作成できます。 Image Builderサービスの詳細についてはImage Builderユーザーガイドを参照してください。
[注意] NKSワーカーノード化作業にはパッケージのインストールや設定変更などが含まれているため、正常に動作しないイメージで作業を進める場合、失敗する可能性があります。 Image Builderサービスの使用に対して課金される場合があります。
制約事項
NHN Cloudインスタンスをベースに作成したカスタムイメージのみ、ワーカーノードイメージとして使用できます。該当機能は特定インスタンスイメージに対してのみ提供されます。カスタムイメージを作成する基盤インスタンスのイメージに合わせて、正しいバージョンのワーカーノード化アプリケーションを選択する必要があります。インスタンスイメージごとに選択しなければならないアプリケーションバージョン情報は下表を参照してください。
| OS | イメージ | アプリケーションバージョン |
|---|---|---|
| CentOS | CentOS 7.9 (2022.11.22) | 1.0 |
| CentOS 7.9 (2023.05.25) | 1.1 | |
| CentOS 7.9 (2023.08.22) | 1.2 | |
| CentOS 7.9 (2023.11.21) | 1.3 | |
| CentOS 7.9 (2024.02.20) | 1.4 | |
| Rocky | Rocky Linux 8.6 (2023.03.21) | 1.0 |
| Rocky Linux 8.7 (2023.05.25) | 1.1 | |
| Rocky Linux 8.8 (2023.08.22) | 1.2 | |
| Rocky Linux 8.8 (2023.11.21) | 1.3 | |
| Rocky Linux 8.9 (2024.02.20) | 1.4 | |
| Ubuntu | Ubuntu Server 18.04.6 LTS (2023.03.21) | 1.0 |
| Ubuntu Server 20.04.6 LTS (2023.05.25) | 1.1 | |
| Ubuntu Server 20.04.6 LTS (2023.08.22) | 1.2 | |
| Ubuntu Server 20.04.6 LTS (2023.11.21) | 1.3 | |
| Ubuntu Server 22.04.3 LTS (2023.11.21) | 1.3 | |
| Ubuntu Server 20.04.6 LTS (2024.02.20) | 1.4 | |
| Ubuntu Server 22.04.3 LTS (2024.02.20) | 1.4 | |
| Debian | Debian 11.6 Bullseye (2023.03.21) | 1.0 |
| Debian 11.6 Bullseye (2023.05.25) | 1.1 | |
| Debian 11.7 Bullseye (2023.08.22) | 1.2 | |
| Debian 11.8 Bullseye (2023.11.21) | 1.3 | |
| Debian 11.8 Bullseye (2024.02.20) | 1.4 |
[参考] カスタムイメージをワーカーノードイメージに変換する過程で選択したオプションによってGPUドライバーがインストールされます。 したがって、 カスタムGPUワーカーノードイメージを作成する場合にも、カスタムイメージの作成をGPUインスタンスで行う必要はありません。
進行過程
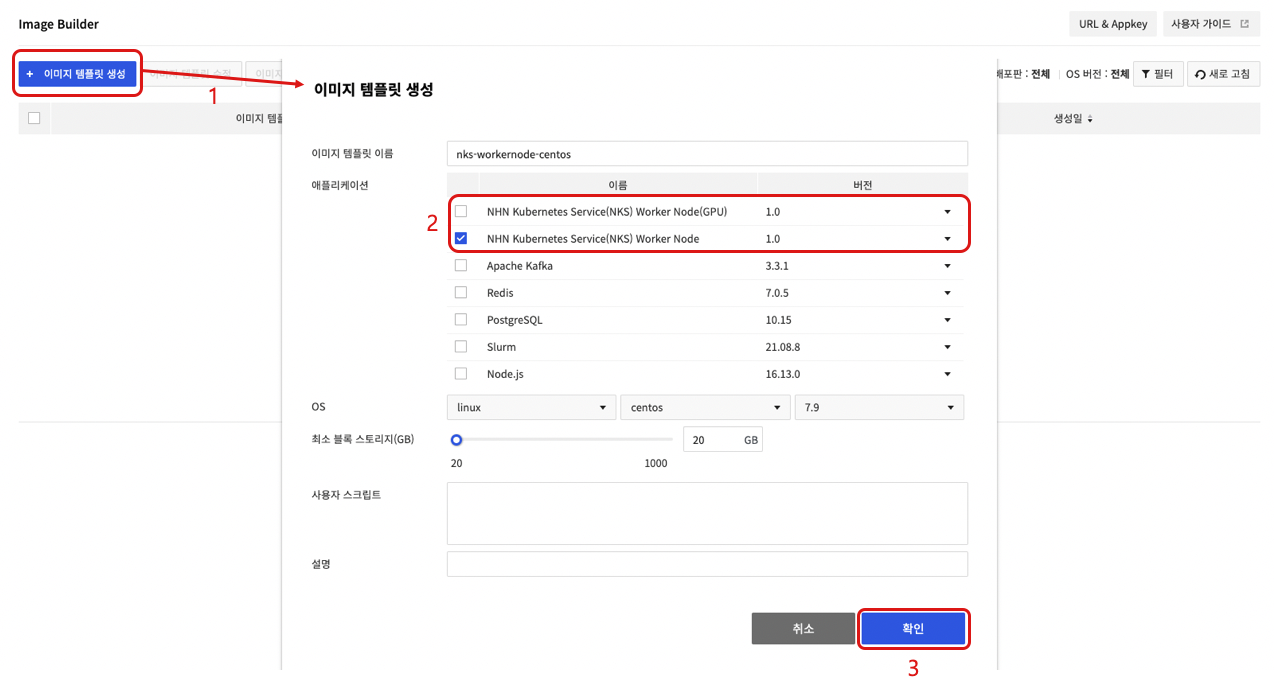
カスタムイメージをワーカーノードイメージとして活用するため、Image Builderサービスで下記のようなプロセスを実行します。
- イメージテンプレートを作成をクリックします。
- アプリケーションを選択した後、イメージテンプレート名、OS、最小ブロックストレージ(GB)、ユーザースクリプト、説明を作成します。
- GPU Flavorを使用しないワーカーノードグループの場合、NHN Kubernetes Service(NKS) Worker Nodeアプリケーションを選択します。
- GPU Flavorを使用するワーカーノードグループの場合、NHN Kubernetes Service(NKS) Worker Node(GPU)アプリケーションを選択します。
- 確認を押してイメージテンプレートを作成します。
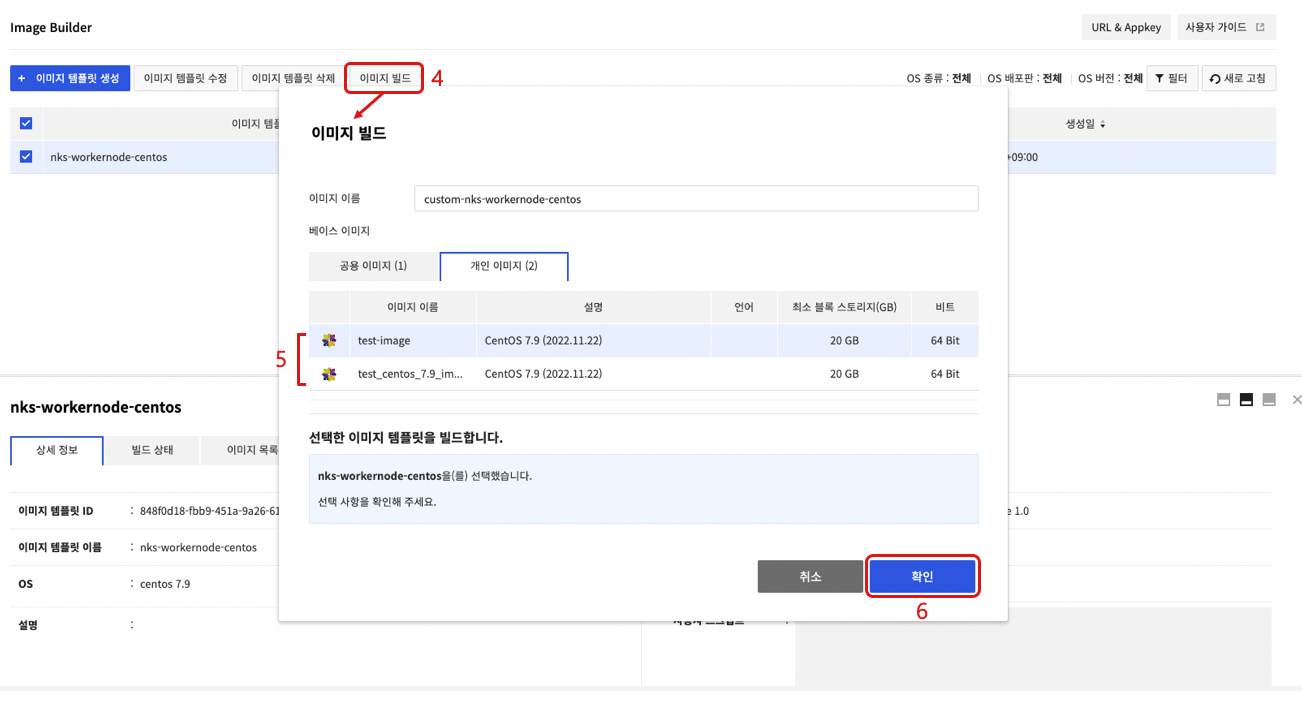
- 作成されたイメージテンプレートを選択した後、イメージビルドを選択します。
- イメージビルド画面で個人イメージタブを選択した後、NKS Worker Node化を進めるカスタムイメージを選択します。
- 確認をクリックすると、NKSワーカーノード化が進行された後、新しいイメージを作成します。
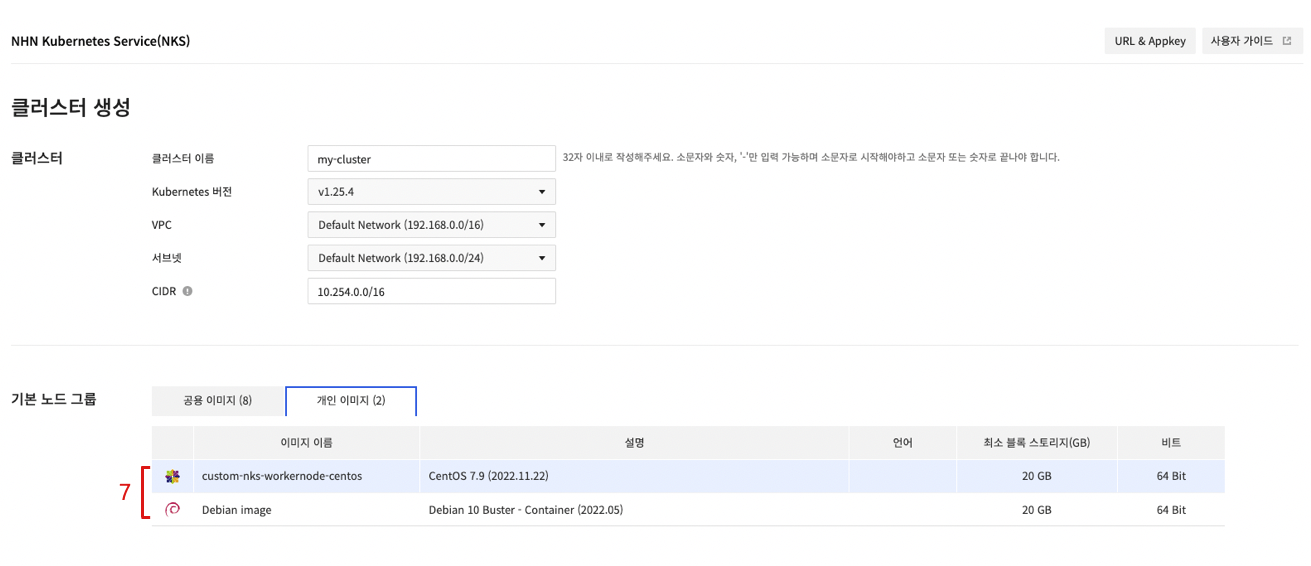
- クラスタ作成またはノードグループ作成画面で作成されたカスタムイメージを選択します。
クラスター管理
遠隔のホストからクラスターを操作し、管理するには、Kubernetesが提供するコマンドラインツール(CLI)、kubectlが必要です。
kubectlインストール
kubectlは、インストール不要で、実行ファイルをダウンロードしてすぐに使用できます。各OSのダウンロードパスは次のとおりです。
[注意] ワーカーノードでパッケージマネージャーを利用してkubeadm、kubelet、kubectlなどのKubernetes関連コンポーネントをインストールすると、クラスタの誤作動を引き起こす可能性があります。ワーカーノードにkubectlをインストールする場合、下記のダウンロードコマンドを参考にしてファイルをダウンロードしてください。
| OS | ダウンロードコマンド |
|---|---|
| Linux | curl -LO https://storage.googleapis.com/kubernetes-release/release/v1.15.7/bin/linux/amd64/kubectl |
| MacOS | curl -LO https://storage.googleapis.com/kubernetes-release/release/v1.15.7/bin/darwin/amd64/kubectl |
| Windows | curl -LO https://storage.googleapis.com/kubernetes-release/release/v1.15.7/bin/windows/amd64/kubectl.exe |
その他、インストール方法とオプションなどの詳細は、Install and Set Up kubectl文書を参照してください。
権限変更
ダウンロードしたファイルは基本的に実行権限がありません。実行権限を追加する必要があります。
$ chmod +x kubectl
位置変更またはパス指定
どのパスからでもkubectlを実行できるように環境変数に指定されたパスに移すか、kubectlがあるパスを環境変数に追加します。
- 環境変数に指定したパスへ移動
$ sudo mv kubectl /usr/local/bin/
- 環境変数にパスを追加
// kubectlがあるパスで実行
$ export PATH=$PATH:$(pwd)
設定
kubectlでKubernetesクラスターにアクセスするには、クラスター設定ファイル(kubeconfig)が必要です。NHN Cloud WebコンソールでContainer > NHN Kubernetes Service(NKS)サービスページを開き、アクセスするクラスターを選択します。下部、基本情報タブで設定ファイル項目のダウンロードボタンを押して設定ファイルをダウンロードします。ダウンロードした設定ファイルは、任意の位置へ移動させ、kubectl実行時に参照できるように準備します。
[注意] NHN Cloud Webコンソールからダウンロードした設定ファイルは、クラスター情報と認証のためのトークンなどが含まれています。設定ファイルがある場合は該当Kubernetesクラスターにアクセスできる権限を持ちます。設定ファイルを絶対に紛失しないように注意してください。
kubectlは実行するたびにクラスター設定ファイルが必要です。したがって、毎回--kubeconfigオプションを利用してクラスター設定ファイルを指定する必要があります。しかし、環境変数にクラスター設定ファイルパスが保存されている場合は、毎回オプションを指定する必要はありません。
$ export KUBECONFIG={クラスター設定ファイルパス}
クラスター設定ファイルのパスを環境変数に保存したくない場合は、kubectlの基本設定ファイル、$HOME/.kube/configにコピーして使用することもできます。しかし、クラスターを複数運用する場合は、環境変数の値を変更する方法が便利です。
接続確認
kubectl versionコマンドで、正常に設定できているかを確認します。問題がなければServer Versionが出力されます。
$ kubectl version
Client Version: version.Info{Major:"1", Minor:"15", GitVersion:"v1.15.7", GitCommit:"6c143d35bb11d74970e7bc0b6c45b6bfdffc0bd4", GitTreeState:"clean", BuildDate:"2019-12-11T12:42:56Z", GoVersion:"go1.12.12", Compiler:"gc", Platform:"darwin/amd64"}
Server Version: version.Info{Major:"1", Minor:"15", GitVersion:"v1.15.7", GitCommit:"6c143d35bb11d74970e7bc0b6c45b6bfdffc0bd4", GitTreeState:"clean", BuildDate:"2019-12-11T12:34:17Z", GoVersion:"go1.12.12", Compiler:"gc", Platform:"linux/amd64"}
- Client Version:実行したkubectlファイルのバージョン情報
- Server Version:クラスターを構成しているKubernetesのバージョン情報
CSR(CertificateSigningRequest)
Kubernetesの認証API(Certificate API)を通してKubernetes APIクライアントのためのX.509証明書(certificate)をリクエストして発行できます。 CSRリソースは証明書をリクエストして、リクエストに対して承認/拒否を決定できるようにします。詳細事項はCertificate Signing Requests文書を参照してください。
CSRリクエストと発行承認例
まず秘密鍵(private key)を作成します。証明書作成に関する詳細はCertificates文書を参照してください。
$ openssl genrsa -out dev-user1.key 2048
Generating RSA private key, 2048 bit long modulus
...........................................................................+++++
..................+++++
e is 65537 (0x010001)
$ openssl req -new -key dev-user1.key -subj "/CN=dev-user1" -out dev-user1.csr
作成した秘密鍵情報を含むCSRリソースを作成して証明書発行をリクエストします。
$ BASE64_CSR=$(cat dev-user1.csr | base64 | tr -d '\n')
$ cat <<EOF > csr.yaml -
apiVersion: certificates.k8s.io/v1
kind: CertificateSigningRequest
metadata:
name: dev-user1
spec:
groups:
- system:authenticated
request: ${BASE64_CSR}
signerName: kubernetes.io/kube-apiserver-client
expirationSeconds: 86400 # one day
usages:
- client auth
EOF
$ kubectl apply -f csr.yaml
certificatesigningrequest.certificates.k8s.io/dev-user1 created
登録されたCSRはPending状態です。この状態は発行承認または拒否を待っている状態です。
$ kubectl get csr
NAME AGE SIGNERNAME REQUESTOR REQUESTEDDURATION CONDITION
dev-user1 3s kubernetes.io/kube-apiserver-client admin 24h Pending
この証明書発行リクエストに対して承認処理を行います。
$ kubectl certificate approve dev-user1
certificatesigningrequest.certificates.k8s.io/dev-user1 approved
CSRをもう一度確認するとApproved,Issued状態に変更されたことを確認できます。
$ kubectl get csr
NAME AGE SIGNERNAME REQUESTOR REQUESTEDDURATION CONDITION
dev-user1 28s kubernetes.io/kube-apiserver-client admin 24h Approved,Issued
証明書は次のように照会できます。証明書はstatusのcertificateフィールドの値です。
$ apiVersion: certificates.k8s.io/v1
kind: CertificateSigningRequest
metadata:
annotations:
kubectl.kubernetes.io/last-applied-configuration: |
{"apiVersion":"certificates.k8s.io/v1","kind":"CertificateSigningRequest","metadata":{"annotations":{},"name":"dev-user1"},"spec":{"expirationSeconds":86400,"groups":["system:authenticated"],"request":"LS0t..(以下省略)","signerName":"kubernetes.io/kube-apiserver-client","usages":["client auth"]}}
creationTimestamp: "2023-09-15T05:53:12Z"
name: dev-user1
resourceVersion: "176619"
uid: a5813153-40de-4725-9237-3bf684fd1db9
spec:
expirationSeconds: 86400
groups:
- system:masters
- system:authenticated
request: LS0tLS...(以下省略)
signerName: kubernetes.io/kube-apiserver-client
usages:
- client auth
username: admin
status:
certificate: LS0tLS...(以下省略)
conditions:
- lastTransitionTime: "2023-09-15T05:53:26Z"
lastUpdateTime: "2023-09-15T05:53:26Z"
reason: KubectlApprove
status: "True"
type: Approved
[注意] この機能はクラスター作成時点が下記の期間に該当する場合にのみ提供されます。
- パンギョリージョン:2020年12月29日以降に作成したクラスター
- 坪村リージョン:2020年12月24日以降に作成したクラスター
承認コントローラー(admission controller)プラグイン
承認コントローラーはKubernetes APIサーバーリクエストを奪ってオブジェクトを変更したり、リクエストを拒否できます。承認コントローラーの詳細は承認コントローラーを参照してください。また承認コントローラーの使用例は承認コントローラーガイドを参照してください。
クラスタバージョンとクラスタ作成時点によって、承認コントローラーに適用されるプラグインの種類が異なります。詳細についてはリージョン別の作成時点によるプラグインリストを参照してください。
v1.19.13以前のバージョン
パンギョリージョン2021年2月22日以前に作成したクラスタおよび坪村リージョン2021年2月17日以前に作成したクラスタは次のように適用されます。
- DefaultStorageClass
- DefaultTolerationSeconds
- LimitRanger
- MutatingAdmissionWebhook
- NamespaceLifecycle
- NodeRestriction
- ResourceQuota
- ServiceAccount
- ValidatingAdmissionWebhook
パンギョリージョン2021年2月23日以降に作成したクラスタおよび坪村リージョン2021年2月18日以降に作成したクラスタは次のように適用されます。
- DefaultStorageClass
- DefaultTolerationSeconds
- LimitRanger
- MutatingAdmissionWebhook
- NamespaceLifecycle
- NodeRestriction
- PodSecurityPolicy(新規追加)
- ResourceQuota
- ServiceAccount
- ValidatingAdmissionWebhook
v1.20.12以降のバージョン
Kubernetesバージョン別の基本アクティブ承認コントローラーはすべて有効になります。基本アクティブ承認コントローラーに以下のコントローラーが有効になります。
- NodeRestriction
- PodSecurityPolicy
クラスタアップグレード
NHN Kubernetes Service(NKS)は動作中のKubernetesクラスタのKubernetesコンポーネントのアップグレードをサポートします。
Kubernetesバージョン違いサポートポリシー
Kubernetesのバージョンはx.y.zで表現されます。 xはメジャーバージョン、yはマイナーバージョン、zはパッチバージョンです。機能が追加される場合、メジャーバージョンまたはマイナーバージョンをアップロードし、バグ修正など以前のバージョンと互換性のある機能を提供する場合はパッチバージョンをアップロードします。詳しい内容はこちらを参照してください。
Kubernetesクラスタは、動作中の状態でKubernetesコンポーネントをアップグレードできます。そのため、KubernetesコンポーネントごとにKubernetesバージョンの違いによる機能をサポートするかどうかを定義しています。マイナーバージョンを基準にした段階のバージョンの違いは相互機能互換をサポートすることで動作中のクラスタのKubernetesコンポーネントアップグレードをサポートします。またコンポーネントの種類ごとにアップグレード順序を定義しています。詳しい内容はこちらを参照してください。
機能動作方式
NHN CloudでサポートするKubernetesクラスタアップグレード機能の動作方式を説明します。
Kubernetesバージョン管理
NHN CloudのKubernetesクラスタはクラスタマスターとワーカーノードグループごとにKubernetesバージョンを管理します。マスターのKubernetesバージョンはクラスタ照会画面で確認することができ、ワーカーノードグループのKubernetesバージョンは各ワーカーノードグループ照会画面で確認できます。
アップグレードルール
NHN CloudのKubernetesクラスタバージョン管理方式とKubernetesバージョン違いサポートポリシーによりコンポーネントごとに順序に合わせてアップグレードする必要があります。NHN CloudのKubernetesクラスタアップグレード機能に適用されるルールは次のとおりです。
- マスターとワーカーノードグループごとにアップグレードコマンドを実行する必要があります。
- マスターのKubernetesバージョンとすべてのワーカーノードグループのKubernetesバージョンが一致している時のみアップグレードが可能です。
- マスターを先にアップグレードした後、ワーカーノードグループをアップグレードできます。
- 現在バージョンの次のバージョン(マーナーバージョン基準 +1)にアップグレード可能です。
- ダウングレードはサポートしません。
- 他の機能の動作によりクラスタがアップデート中の状態ではアップグレードができません。
- クラスタのバージョンをv1.25.4からv1.26.3にアップグレードする際、CNIがFlannelの場合はCalicoに変更する必要があります。
次の例はKubernetesバージョンのアップグレード可否を表にしたものです。例に使用された条件は次のとおりです。
- NHN CloudがサポートするKubernetesバージョンリスト:v1.21.6, v1.22.3, v1.23.3
- クラスタはv1.21.6で作成
| 状態 | マスターバージョン | マスターアップグレード可否 | ワーカーノードグループバージョン | ワーカーノードグループアップグレード可否 |
|---|---|---|---|---|
| 初期状態 | v1.21.6 | 可能 (注1) | v1.21.6 | 不可 (注2) |
| マスターアップグレード後の状態 | v1.22.3 | 不可 (注3) | v1.21.6 | 可能 (注4) |
| ワーカーノードグループアップグレード後の状態 | v1.22.3 | 可能 (注1) | v1.22.3 | 不可 (注2) |
| マスターアップグレード後の状態 | v1.23.3 | 不可 (注3) | v1.22.3 | 可能 (注4) |
| ワーカーノードグループアップグレード後の状態 | v1.23.3 | 不可 (注5) | v1.23.3 | 不可 (注2) |
- (注1)マスターとすべてのワーカーノードグループのバージョンが一致する状態のためアップグレード可能
- (注2)ワーカーノードグループはマスターがアップグレードされた後にアップグレード可能
- (注3)マスターとすべてのワーカーノードグループのバージョンが一致する時のみアップグレード可能
- (注4)マスターがアップグレードされたためアップグレード可能
- (注5) NHN Cloudでサポートする最新バージョンを使用しているためアップグレード不可
マスターコンポーネントアップグレード
NHN CloudのKubernetesクラスタマスターは高可用性を保障するために多数のマスターで構成されています。マスターに対してローリングアップデート方式でアップグレードされるため、クラスタの可用性が保障されます。
この過程で以下のようなことが発生することがあります。
- Kubernetes APIが一時的に失敗することがあります。
ワーカーコンポーネントアップグレード
ワーカーノードグループごとにワーカーコンポーネントをアップグレードできます。ワーカーコンポーネントアップグレードは、次の順序で行われます。
- クラスタオートスケーラ機能を無効化します。(注1)(#footnote_worker_component_upgrade_1)
- 該当ワーカーノードグループにバッファノード(注2)(#footnote_worker_component_upgrade_2)を追加します。(注3)
- ワーカーノードグループ内のすべてのワーカーノードに対して順番に以下の作業を行います。(注4)
- 該当ワーカーノードで動作中のPodを追放して、ノードをスケジュールできない状態に切り替えます。
- ワーカーコンポーネントをアップグレードします。
- ノードをスケジュール可能な状態に切り替えます。
- バッファノードで動作中のPodを追放してバッファノードを削除します。
-
クラスタオートスケーラ機能を再度有効にします。(注1)
-
(注1)この段階はアップグレード機能開始前にクラスタオートスケーラ機能が有効になっている場合にのみ有効です。
- (注2)バッファノードとは、アップグレード中に既存ワーカーノードから追放されたPodがもう一度スケジューリングできるように作成しておく余裕ノードのことです。該当ワーカーノードグループで定義したワーカーノードと同じ規格のノードで作成され、アップグレードが終了する時に自動的に削除されます。このノードはInstance料金ポリシーに基づいて費用が請求されます。
- (注3)アップグレード時のバッファノード数を設定できます。デフォルト値は1で、0に設定するとバッファノードを追加しません。最小値は0で、最大値は(ノードグループ当たりの最大ノード数クォーター - 該当のワーカーノードグループの現在ノード数)です。
- (注4)アップグレード時に設定した最大サービス不可ノード数だけ作業を実行します。デフォルト値は1です。最小値は1で、最大値は該当ワーカーノードグループの現在ノード数です。
この過程で以下のようなことが発生することがあります。
- サービス中のPodが追放されて他のノードにスケジューリングされます(Pod追放の詳細は以下のPod追放関連注意事項を参照してください)。
- オートスケーラ機能が動作しません。
[Pod追放関連注意事項] 1. デーモンセット(daemonset)コントローラーによるPodは追放されません。 デーモンセットコントローラーは、ワーカーノードごとにPodを実行するため、デーモンセットコントローラーにより実行されたPodは追放されても他のノードで実行されません。ワーカーノードグループアップグレード過程でデーモンセットコントローラーにより実行されたPodは追放しません。 2. ローカル記憶領域を使用するPodは追放される時、使用していたデータを失います。
emptyDirを利用してノードのローカル記憶領域を使用するPodは追放される時、使用していたデータを失います。ノードのローカルに保存された記憶領域が他のノードに移動できないためです。 3. 他のノードに複製ができないPodは、他のノードに移動できません。 レプリケーションコントローラー(ReplicationController)、レプリカセット(ReplicaSet)、ジョブ(Job)、デーモンセット(Daemonset)、ステートフル(StatefulSet)などのコントローラーにより実行されたPodが追放されると、コントローラーにより他のノードにスケジューリングされます。しかしこのようなコントローラーを利用していないPodは追放された後、他のノードにスケジューリングされません。 4. PodDisruptionBudgets(PDB)設定により追放に失敗したり、遅くなることがあります。 PodDisruptionBudgets(PDB)設定で維持する必要があるPod数を定義できます。この機能設定によりアップグレード過程でPodの追放ができない場合もあり、Pod追放時間が長くなることがあります。Pod追放に失敗するとアップグレードが失敗します。したがってPDB設定が行われている場合は、適切なPDB設定でPod追放が円滑に動作するように設定する必要があります。 PDB設定の詳細はこちらを参照してください。
安全なPod追放についてはこちらを参照してください。
システムPodアップグレード
マスターとすべてのワーカーノードグループをアップグレードしてバージョンが一致すると、Kubernetesクラスタ構成のために動作するシステムPodがアップグレードされます。
[注意] マスターアップグレード後にワーカーノードグループをアップグレードしなかった場合、一部Podが正常に動作しない可能性があります。
クラスタCNIの変更
NHN Kubernetes Service(NKS)は動作中のKubernetesクラスタのCNI(container network interface)変更をサポートします。 クラスタCNI変更機能を使用するとNHN Kubernetes Service(NKS)のCNIがFlannel CNIからCalico CNIに変更されます。
CNI変更ルール
NHN CloudのKubernetesクラスタCNI変更機能に適用されるルールは次のとおりです。
- CNI変更機能はNHN Kubernetes Service(NKS)バージョン1.24.3以上の場合に使用できます。
- 既存NHN Kubernetes Service(NKS)で使用しているCNIがFlannelの場合にのみCNI変更を使用できます。
- CNI変更開始時、マスターとすべてのワーカーノードグループに対して一括で作業を行います。
- マスターのKubernetesバージョンとすべてのワーカーノードグループのKubernetesバージョンが一致すればCNI変更が可能です。
- CalicoからFlannelへのCNI変更はサポートしません。
- 他の機能の動作により、クラスタがアップデート中の状態ではCNIの変更ができません。
次の例は、Kubernetes CNI変更過程で変更できるかどうかを表で示したものです。例に使用された条件は次のとおりです。
NHN CloudがサポートするKubernetesバージョンリスト:v1.23.3、v1.24.3、v1.25.4 クラスタはv1.23.3で作成
| 状態 | クラスタバージョン | 現在CNI | CNI変更可否 | --- | :-: | :-: | :-: | :-: | | 初期状態| v1.23.3 | Flannel | 不可 (注1)(#footnote_calico_change_rule_1) | | クラスタアップグレード後の状態 | v1.24.3 | Flannel | 可能 (注2)(#footnote_calico_change_rule_2) | | CNI変更後の状態 | v1.24.3 | Calico | 不可 (注3)(#footnote_calico_change_rule_3) |
注釈
FlannelからCalico CNIへの変更進行プロセス
CNIの変更は次の順序で行われます。
- すべてのワーカーノードグループにバッファノード(注1)(#footnote_calico_change_step_1)を追加します。(注2)(#footnote_calico_change_step_2)
- クラスタにCalico CNIが配布されます。(注3)(#footnote_calico_change_step_3)
- クラスタオートスケーラ機能を無効化します。(注4)(#footnote_calico_change_step_4)
- すべてのワーカーノードグループ内のすべてのワーカーノードに対して以下の作業を順次実行します。(注5)(#footnote_calico_change_step_5)
- 該当ワーカーノードで動作中のPodを追放し、ノードをスケジュール不可能な状態に切り替えます。
- ワーカーノードのPod IPをCalico CIDRに再割当てします。該当ノードに配布されているすべてのPodは再配布されます。(注6)(#footnote_calico_change_step_6)
- ノードをスケジュール可能な状態に切り替えます。
- バッファノードで動作中のPodを追放し、バッファノードを削除します。
- クラスタオートスケーラ機能を再度有効にします。(注4)(#footnote_calico_change_step_4)
- Flannel CNIを削除します。
注釈
- (注1)バッファノードとは、CNI変更過程で既存ワーカーノードから追放されたPodが再びスケジューリングできるように作成しておく空きノードを指します。該当ワーカーノードグループで定義したワーカーノードと同じ規格のノードとして作成され、アップグレードプロセスが終了すると自動的に削除されます。このノードはInstance料金ポリシーに基づいて費用が請求されます。
- (注2)CNI変更時にバッファノード数を設定できます。デフォルト値は1で、0に設定するとバッファノードを追加しません。最小値は0で、最大値は(ノードグループあたりの最大ノード数クォーター - 該当ワーカーノードグループの現在ノード数)です。
- (注3)クラスタにCalico CNIが配布されると、FlannelとCalico CNIが共存します。この状態で新しいPodが配布されるとPod IPはFlannel CNIに設定されて配布されます。Flannel CIDR IPを持つPodとCalico CIDR IPを持つPodはお互いに通信できます。
- (注4)このステップはアップグレード機能開始前にクラスタオートスケーラ機能が有効になっている場合にのみ有効です。
- (注5)CNI変更時に設定した最大サービス不可ノードの数だけ作業を実行します。デフォルト値は1です。最小値は1で、最大値は現在クラスタのすべてのノード数です。
- (注6)既に配布されているPodのIPは全てFlannel CIDRに割り当てられています。Calico CNIに変更するためにFlannel CIDRのIPが割り当てられてているPodを全て再配布してCalico CIDR IPを割り当てます。新しいPodが配布されるとPod IPはCalico CNIに設定されて配布されます。
この過程で以下のようなことが発生することがあります。
- サービス中のPodが追放され、他のノードにスケジューリングされます。(Podの追放ついてはクラスタアップグレードを参照してください)
- クラスタに配布されているすべてのPodが再配布されます。(Podの再配布については、以下のPod再配布注意事項を参照してください)
- オートスケーラ機能が動作しません。
[Pod再配布注意事項] 1. Pod追放プロセスによって他のノードに移されなかったPodに対して行われます。 2. CNI変更プロセス中にFlannel CIDRとCalico CIDR間の正常な通信のためにCNI変更Podネットワーク値は既存Flannel CIDR値と同じであってはいけません。 3. 既に配布されていたPodのpauseコンテナは全て停止し、kubeletによって再作成されます。Pod名とローカル記憶領域などの設定はそのまま維持されますが、IPはCalico CIDRのIPに変更されます。
クラスタAPIエンドポイントにIPアクセス制御を適用
クラスタAPIエンドポイントにIPアクセス制御を適用または解除できます。 IPアクセス制御機能の詳細については、IPアクセス制御文書を参照してください。
IPアクセス制御対象ルール
クラスタAPIエンドポイントのIPアクセス制御対象を追加する場合、以下のルールが適用されます。
- IPアクセス制御タイプが許可に設定されている場合、クラスタ基本サブネットCIDRがアクセス制御対象に自動的に追加されます。
- IPアクセス制御タイプが許可に設定されている場合、NKSコンソールのダッシュボード、ネームスペース、ワークロード、サービス&ネットワーク、ストレージ、設定、イベントタブが無効になります。
- IPアクセス制御タイプがブロックに設定されているとき、クラスタ基本サブネットCIDR帯域に重複するIP帯域がアクセス制御対象リストにある場合は要求が拒否されます。
- 最大設定可能なIPアクセス制御対象数は100個です。
- IP アクセス制御対象は1つ以上存在する必要があります。
ワーカーノード管理
コンテナ管理
Kubernetes v1.24.3以前のバージョンのクラスタ
Kubernetes v1.24.3以前のバージョンのクラスタはDockerを利用してコンテナランタイムを構成します。ワーカーノードでdocker CLIを利用してコンテナ状態照会、コンテナイメージ照会などの作業が行えます。docker CLIの詳細な説明と使用方法についてはUse the Docker command lineを参照してください。
Kubernetes v1.24.3以降のバージョンのクラスタ
Kubernetes v1.24.3以降のバージョンのクラスタはcontainerdを利用してコンテナランタイムを構成します。ワーカーノードでdocker CLIの代わりにnerdctlを利用してコンテナ状態照会、コンテナイメージ照会などの作業ができます。Nerdctlの詳細な説明と使用方法についてはnerdctl: Docker-compatible CLI for containerdを参照してください。
ネットワーク管理
基本ネットワークインタフェース
すべてのワーカーノードはクラスタ作成時に入力したVPC/サブネットに接続されるネットワークインタフェースを持っています。この基本ネットワークインタフェースの名前は"eth0"で、ワーカーノードはこのネットワークインタフェースを介してマスターと接続されます。
追加ネットワークインタフェース
クラスタまたはワーカーノードグループ作成時に追加ネットワークを設定すると、該当ワーカーノードグループのワーカーノードに追加ネットワークインタフェースが作成されます。追加ネットワークインタフェースは追加ネットワーク設定に入力した順序通りにインタフェース名が設定されます(eth1, eth2, ...)。
基本パス(default route)設定
ワーカーノードに複数のネットワークインタフェースが存在する場合、ネットワークインタフェースごとに基本パスが設定されます。あるシステムに複数の基本パスが設定されている場合、マトリックス(metric)値が最も低い基本パスがシステム基本パスとして動作します。ネットワークインタフェースごとの基本パスはインタフェース番号が小さいほど小さいマトリックス値が設定されています。このため動作中のネットワークインタフェースのうち最も小さい番号のネットワークインタフェースがシステム基本パスとして動作します。
システム基本パスを追加ネットワークインタフェースとして設定するには、以下のような作業が必要です。
1. ネットワークインタフェース別マトリックス設定の変更
ワーカーノードのすべてのネットワークインタフェースはDHCPサーバーを介してIPアドレスを割り当てられます。DHCPサーバーからIPアドレスを割り当てられる時、ネットワークインタフェースごとに基本パスを設定します。この時、各基本パスのマトリックス値はインタフェースごとにあらかじめ設定されています。各Linuxディストリビューションの保存位置および設定項目は次のとおりです。
- CentOS
- 設定ファイルの位置:/etc/sysconfig/network-scripts/ifcfg-{ネットワークインタフェース名}
- マトリックス値設定項目; METRIC
- Ubuntu
- 設定ファイルの位置:/etc/systemd/network/toastcloud-{ネットワークインタフェース名}.network
- マトリックス値設定項目:DHCPセクションのRouteMetric
[注意] 基本パス別マトリックス値は基本パスが設定される時点で決定されます。 したがって変更された設定は次の基本パス設定時に適用されます。 現在システムに適用されているパス別マトリックス値を変更するには以下の
現在パスのマトリックス値変更を参照してください。
2. 現在パスのマトリックス値の変更
システム基本パスを変更するためにネットワークインタフェース別基本パスのマトリックス値を調整できます。次はrouteコマンドを利用して各基本パスのマトリックス値を調整する例です。
次は作業実行前の状態です。インタフェース番号が小さいほどマトリックス値が小さく設定されていることを確認できます。
# route -n
Kernel IP routing table
Destination Gateway Genmask Flags Metric Ref Use Iface
0.0.0.0 10.0.0.1 0.0.0.0 UG 0 0 0 eth0
0.0.0.0 192.168.0.1 0.0.0.0 UG 100 0 0 eth1
0.0.0.0 172.16.0.1 0.0.0.0 UG 200 0 0 eth2
...
eth1をシステム基本パスに設定するためにeth1のマトリックス値を0に、eth0のマトリックス値を100に変更します。マトリックス値のみ変更することはできないため、パスを削除して再度追加する必要があります。まずeth0のパスを削除し、eth0のマトリックス値を100に設定します。
# route del -net 0.0.0.0/0 dev eth0
# route add -net 0.0.0.0/0 gw 10.0.0.1 dev eth0 metric 100
eth1も先に既存パスを削除し、eth1のマトリックスを0に設定します。
# route del -net 0.0.0.0/0 dev eth1
# route add -net 0.0.0.0/0 gw 192.168.0.1 dev eth1 metric 0
もう一度パスを照会するとマトリックス値が変更されていることを確認できます。
# route -n
Kernel IP routing table
Destination Gateway Genmask Flags Metric Ref Use Iface
0.0.0.0 192.168.0.1 0.0.0.0 UG 0 0 0 eth1
0.0.0.0 10.0.0.1 0.0.0.0 UG 100 0 0 eth0
0.0.0.0 172.16.0.1 0.0.0.0 UG 200 0 0 eth2
...
ユーザースクリプト機能を利用した基本パス設定の変更
ユーザースクリプト機能を利用するとノード増設などでノードが新たに初期化される時も上記のような設定を維持できます。次のユーザースクリプトはCentOSを使用するワーカーノードでeth0のマトリックス値を100に、eth1のマトリックス値を0に設定する例です。このようにすると現在システムに適用されている基本パスごとのマトリックス値も変更され、これはワーカーノードの再起動後にも維持されます。
#!/bin/bash
sed -i -e 's|^METRIC=.*$|METRIC=100|g' /etc/sysconfig/network-scripts/ifcfg-eth0
sed -i -e 's|^METRIC=.*$|METRIC=0|g' /etc/sysconfig/network-scripts/ifcfg-eth1
route del -net 0.0.0.0/0 dev eth0
route add -net 0.0.0.0/0 gw 10.0.0.1 dev eth0 metric 100
route del -net 0.0.0.0/0 dev eth1
route add -net 0.0.0.0/0 gw 192.168.0.1 dev eth1 metric 0
kubeletユーザー定義引数設定機能
kubeletはすべてのワーカーノードで動作するノードエージェントです。kubeletはコマンドラインアギュメントを利用して様々な設定を入力します。NKSが提供するkubeletユーザー定義引数設定機能を利用すると、kubelet起動時に入力される引数を追加できます。kubeletカスタム引数は次のように設定し、システムに適用できます。
- ワーカーノードの
/etc/kubernetes/kubelet-user-argsファイルにKUBELET_USER_ARGS="User Defined Argument"形式でユーザー定義引数を入力します。 systemctl daemon-reloadコマンドを実行します。systemctl restart kubeletコマンドを実行します。systemctl status kubeletコマンドで、kubeletが正常に動作していることを確認します。
[注意] * この機能は、2023年11月28日以降に新規作成されたクラスタでのみ動作します。 * ユーザー定義引数を設定するワーカーノードごとに実行します。 * 正しくない形式のユーザー定義アギュメントを入力すると、kubeletが正常に動作しないことがあります。 * 設定されたユーザー定義引数はシステム再起動時にもそのまま適用されます。
ユーザー定義containerdレジストリ設定機能
v1.24.3以上のNKSクラスタはコンテナランタイムとしてcontainerd v1.6を使用します。NKSではcontainerdの様々な設定のうち、レジストリに関連する項目をユーザーの環境に合わせて設定できる機能を提供します。containerd v1.6のレジストリ設定はConfigure Image Registryを参照してください。
ワーカーノードが初期化される過程で、ユーザー定義のcontainerdレジストリ設定ファイル(/etc/containerd/registry-config.json)が存在する場合、このファイルの内容をcontainerd設定ファイル(/etc/containerd/config.toml)に適用します。ユーザー定義containerdレジストリ設定ファイルが存在しない場合、containerd設定ファイルには基本レジストリ設定が適用されます。基本レジストリ設定の内容は次のとおりです。
[
{
"registry": "docker.io",
"endpoint_list": [
"https://registry-1.docker.io"
]
}
]
1つのレジストリに対して設定できるキー/値の形式は次のとおりです。
{
"registry": "REGISTRY_NAME",
"endpoint_list": [
"ENDPOINT1",
"ENDPOINT2"
],
"tls": {
"ca_file": "CA_FILEPATH",
"cert_file": "CERT_FILEPATH",
"key_file": "KEY_FILEPATH",
"insecure_skip_verify": true_or_false
},
"auth": {
"username": "USERNAME",
"password": "PASSWORD",
"auth": "AUTH",
"identitytoken": "IDENTITYTOKEN"
}
}
例1
docker.io 以外に追加のレジストリを登録する場合は次のように設定できます。
[
{
"registry": "docker.io",
"endpoint_list": [
"https://registry-1.docker.io"
]
},
{
"registry": "additional.registry.io",
"endpoint_list": [
"https://additional.registry.io"
]
}
]
例2
docker.io レジストリを削除してHTTPをサポートするレジストリだけ登録する場合は、次のように設定できます。
[
{
"registry": "user-defined.registry.io",
"endpoint_list": [
"http://user-defined.registry.io"
],
"tls": {
"insecure_skip_verify": true
}
}
]
例3
ノード作成時、ユーザー定義のcontainerdレジストリ設定ファイルを例2の内容で作成するため、ユーザースクリプトを次のように設定できます。
mkdir -p /etc/containerd
echo '[ { "registry": "user-defined.registry.io", "endpoint_list": [ "http://user-defined.registry.io" ], "tls": { "insecure_skip_verify": true } } ]' > /etc/containerd/registry-config.json
[注意] * containerd設定ファイル(
/etc/containerd/config.toml)はNKSによって管理されるファイルです。 このファイルを勝手に修正すると、NKSの機能動作に不具合が発生したり、修正された内容が削除されることがあります。 * ユーザー定義containerdレジストリ設定機能で正しくないレジストリが設定されると、ワーカーノードが異常動作する可能性があります。 * ユーザー定義containerdレジストリ設定機能がcontainerd設定ファイルに適用される時点は、ワーカーノードの初期化過程です。ワーカーノードの初期化過程は、ワーカーノードの作成過程とワーカーノードグループのアップグレード過程に含まれます。 * ワーカーノード作成時、ユーザー定義のcontainerレジストリ設定機能を適用するためには、ユーザースクリプトでこの設定ファイルを作成する必要があります。 * ワーカーノードグループのアップグレード時にユーザー定義のcontainerレジストリ設定機能を適用するためには、すべてのワーカーノードにこのファイルを手動で設定した後、アップグレードを進める必要があります。 * ユーザー定義のcontainerdレジストリ設定ファイルが存在する場合、このファイルに設定された内容がそのままcontainerdに適用されます。 *docker.ioレジストリを使用するには、docker.ioレジストリの設定も含める必要があります。docker.ioレジストリの設定は基本レジストリ設定を参照してください。 *docker.ioレジストリを使用しない場合は、docker.ioレジストリの設定を含まないようにします。ただし、1つ以上のレジストリ設定が存在する必要があります。
LoadBalancerサービス
Kubernetesアプリケーションの基本実行単位Podは、CNI(container network interface)でクラスターネットワークに接続されます。基本的にクラスターの外部からPodにはアクセスできません。Podのサービスをクラスターの外部に公開するにはKubernetesのLoadBalancerサービス(Service)オブジェクト(object)を利用して外部に公開するパスを作成する必要があります。LoadBalancerサービスオブジェクトを作成すると、クラスターの外部にNHN Cloud Load Balancerが作成され、サービスオブジェクトと接続されます。
WebサーバーPod作成
次のように2個のnginx Podを実行するデフォルトデプロイメント(deployment)オブジェクトマニフェストファイルを作成し、オブジェクトを作成します。
# nginx.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-deployment
labels:
app: nginx
spec:
replicas: 2
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx:1.14.2
ports:
- containerPort: 80
デプロイメントオブジェクトを作成すると、マニフェストに定義したPodが自動的に作成されます。
$ kubectl apply -f nginx.yaml
deployment.apps/nginx-deployment created
$ kubectl get pods
NAME READY STATUS RESTARTS AGE
nginx-deployment-7fd6966748-pvrzs 1/1 Running 0 4m13s
nginx-deployment-7fd6966748-wv7rd 1/1 Running 0 4m13s
LoadBalancerサービスの作成
Kubernetesのサービスオブジェクトを定義するには、次の項目で構成されたマニフェストが必要です。
| 項目 | 説明 |
|---|---|
| metadata.name | サービスオブジェクトの名前 |
| spec.selector | サービスオブジェクトと接続するPodの名前 |
| spec.ports | 外部ロードバランサーから流入するトラフィックをPodに伝達するインターフェイス設定 |
| spec.ports.name | インターフェイス名 |
| spec.ports.protocol | インターフェイスで使用するプロトコル(例:TCP) |
| spec.ports.port | サービスオブジェクトの外部に公開するポート番号 |
| spec.ports.targetPort | サービスオブジェクトと接続するPodのポート番号 |
| spec.type | サービスオブジェクトタイプ |
次のようにサービスマニフェストを作成します。このLoadBalancerサービスオブジェクトはspec.selectorに定義された名前に応じてapp: nginxラベルがついたPodと接続されます。そしてspec.portsに定義されたとおりにTCP/8080ポートに流入するトラフィックをPodのTCP/80ポートへ伝達します。
# service.yaml
apiVersion: v1
kind: Service
metadata:
name: nginx-svc
labels:
app: nginx
spec:
ports:
- port: 8080
targetPort: 80
protocol: TCP
selector:
app: nginx
type: LoadBalancer
LoadBalancerサービスオブジェクトを作成すると、クラスターの外部にロードバランサーを作成して接続するまで、若干の時間が必要です。外部ロードバランサーと接続されるまでEXTERNAL-IP項目が<pending>と表示されます。
$ kubectl apply -f service.yaml
service/nginx-svc created
$ kubectl get service
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
nginx-svc LoadBalancer 10.254.134.18 <pending> 8080:30013/TCP 11s
外部ロードバランサーと接続すると、EXTERNAL-IP項目にIPが表示されます。このIPは外部ロードバランサーのFloating IPです。
$ kubectl get service
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
nginx-svc LoadBalancer 10.254.134.18 123.123.123.30 8080:30013/TCP 3m13s
[参考] 作成されたロードバランサーは、Network > Load Balancerページで確認できます。 ロードバランサーのIPは、外部からアクセスできるFloating IPです。Network > Floating IPページで確認できます。
インターネットによるサービステスト
ロードバランサーに接続されたFloating IPにHTTPリクエストを送ってKubernetesクラスターのWebサーバーPodが応答するかを確認します。サービスオブジェクトのTCP/8080ポートをPodのTCP/80ポートと接続するように設定したため、TCP/8080ポートにリクエストを送る必要があります。外部ロードバランサーとサービスオブジェクト、Podが正常に接続されていれば、Webサーバーはnginx基本ページをレスポンスします。
$ curl http://123.123.123.30:8080
<!DOCTYPE html>
<html>
<head>
<title>Welcome to nginx!</title>
<style>
body {
width: 35em;
margin: 0 auto;
font-family: Tahoma, Verdana, Arial, sans-serif;
}
</style>
</head>
<body>
<h1>Welcome to nginx!</h1>
<p>If you see this page, the nginx web server is successfully installed and
working. Further configuration is required.</p>
<p>For online documentation and support please refer to
<a href="http://nginx.org/">nginx.org</a>.<br/>
Commercial support is available at
<a href="http://nginx.com/">nginx.com</a>.</p>
<p><em>Thank you for using nginx.</em></p>
</body>
</html>
ロードバランサー詳細オプション設定
Kubernetesのサービスオブジェクトを定義する時、ロードバランサーの複数のオプションを設定できます。設定可能な項目は次のとおりです。
- グローバル設定とリスナーごとの設定
- リスナー別設定形式
- ロードバランサー名設定
- keep-aliveタイムアウト設定
- ロードバランサータイプ設定
- セッション持続性設定
- ロードバランサー削除時にFloating IPアドレスを保存するかどうかの設定
- ロードバランサーIP設定
- Floating IPを使用するかどうかの設定
- VPC設定
- サブネット設定
- メンバーサブネット設定
- リスナー接続制限設定
- リスナープロトコル設定
- リスナープロキシプロトコル(Proxy Protocol)設定
- ロードバランシング方式設定
- ヘルスチェックプロトコル設定
- ヘルスチェック周期設定
- ヘルスチェック最大レスポンス時間設定
- ヘルスチェック最大再試行回数設定
グローバル設定とリスナー別設定
設定項目ごとにグローバル設定とリスナー別設定が可能です。グローバル設定とリスナー別設定がどちらもない場合、設定別デフォルト値を使用します。 * リスナー別設定:対象リスナーにのみ適用される設定です。 * グローバル設定:対象リスナーにリスナー別設定がない場合にこの設定を適用します。
リスナー別設定形式
リスナー別設定は、グローバル設定キーにリスナーを表すprefixをつけて設定できます。リスナーを表すprefixはサービスオブジェクトのポートプロトコル(spec.ports[].protocol)とポート番号(spec.ports[].port)をダッシュ(-)でつなげたものです。例えばプロトコルがTCPで、ポート番号が80の場合、prefixはTCP-80です。このポートに接続しているリスナーにセッション持続性設定を行いたい場合は.metadata.annotations下のTCP-80.loadbalancer.nhncloud/pool-session-persistenceに設定できます。
以下のマニフェストは、グローバル設定とリスナー別設定を組み合わせた例です。
apiVersion: v1
kind: Service
metadata:
name: echosvr-svc
labels:
app: echosvr
annotations:
# グローバル設定
loadbalancer.nhncloud/pool-lb-method: SOURCE_IP
# リスナー別設定
TCP-80.loadbalancer.nhncloud/pool-session-persistence: "SOURCE_IP"
TCP-80.loadbalancer.nhncloud/listener-protocol: "HTTP"
TCP-443.loadbalancer.nhncloud/pool-lb-method: LEAST_CONNECTIONS
TCP-443.loadbalancer.nhncloud/listener-protocol: "TCP"
spec:
ports:
- name: tcp-80
port: 80
targetPort: 8080
protocol: TCP
- name: tcp-443
port: 443
targetPort: 8443
protocol: TCP
selector:
app: echosvr
type: LoadBalancer
このマニフェストを適用すると、リスナー別設定は次の表のように設定されます。
| 項目 | TCP-80リスナー | TCP-433リスナー| 説明 |
| --- | --- | --- | --- |
| ロードバランシング方式 | SOURCE_IP | LEAST_CONNECTIONS | TCP-80リスナーはグローバル設定に基づいてSOURCE_IPに設定
TCP-443リスナーはリスナー別設定に基づいてLEAST_CONNECTIONSに設定 |
| セッション持続性 | SOURCE_IP | None | TCP-80リスナーはリスナー別設定に基づいてSOURCE_IPに設定
TCP-443リスナーはデフォルト値に基づいてNoneに設定 |
| リスナープロトコル | HTTP | TCP | TCP-80リスナーとTCP-443リスナーはどちらもリスナー別設定に基づいて設定 |
[参考] 別途表示されていない機能はKubernetes v1.19.13以降のバージョンのクラスタにのみ適用可能です。 Kubernetes v1.19.13バージョンのクラスタは2022年1月25日以降に作成されたクラスタにのみリスナー別設定が適用されます。
[注意] 以下の機能の設定値は全て文字列形式で入力する必要があります。YAMLファイル入力形式で入力値の形式に関係なく文字列形式で入力するには入力値を二重引用符(")で囲んでください。 YAMLファイル形式の詳しい内容はYaml Cookbook文書を参照してください。
ロードバランサー名設定
ロードバランサーの名前を設定できます。
- 設定位置は .metadata.annotations下位のloadbalancer.nhncloud/loadbalancer-nameです。
- リスナーごとの設定は適用できません。
- 英字と数字、 '-', '_'のみ入力可能です。
- 有効ではない文字が含まれている場合、基本ロードバランサー名の形式に基づいてロードバランサー名が設定されます。
- 基本ロードバランサー名の形式:"kube_service_{CLUSTER_UUID}_{SERVICE_NAMESPACE}_{SERVICE_NAME}"
- 最大長さは255文字で、最大長さを超えるとロードバランサー名は255文字で切り捨てられます。
[注意] 次の行為を行うと、ロードバランサーの深刻な誤動作を引き起こす可能性があります。 * サービスオブジェクトが作成された後、ロードバランサー名を修正 * プロジェクト内に同じ名前のロードバランサーを作成
ロードバランサータイプ設定
ロードバランサーのタイプを設定できます。ロードバランサーの詳細についてはロードバランサーコンソール使用ガイドを参照してください。
- 設定位置は.metadata.annotations下のloadbalancer.nhncloud/loadbalancer-typeです。
- リスナー別設定を適用できません。
- 次のいずれかに設定できます。
- shared:「一般」タイプのロードバランサーを作成します。未設定時のデフォルト値です。
- dedicated:「専用」タイプのロードバランサーを作成します。
- physical_basic:「物理Basic」タイプのロードバランサーを作成します。
- physical_premium:「物理Premium」タイプのロードバランサーを作成します。
[注意] 物理ロードバランサーは韓国(ピョンチョン)リージョンにのみ提供されます。 物理ロードバランサーはFloating IPを接続できません。その代わり、物理ロードバランサー作成時に自動で割り当てられたパブリックIP1つをバランシング対象トラフィックを受信するIPとして使用します。このパブリックIPはサービスIPという名前でコンソールに表示されます。 このような特性によりKubernetesサービスオブジェクトを通じてロードバランサーの正確な状態(接続されたFloating IPなど)を取得できません。物理ロードバランサーの状態などはコンソールでご確認ください。
セッション持続性設定
ロードバランサーのセッション持続性を設定できます。
- 設定位置は .metadata.annotations下のloadbalancer.nhncloud/pool-session-persistenceです。
- リスナー別設定を適用できます。
- 次の中から1つを設定できます。
- 空の文字列(""):セッション持続性を「なし」に設定します。未設定時のデフォルト値です。
- SOURCE_IP:セッション持続性をSOURCE_IPに設定します。
- ロードバランシング方式がSOURCE_IPの場合、セッション持続性設定は無視され、セッション持続性設定は'なし'に設定されます。
- v1.17.6, v1.18.19クラスタ
- ロードバランサーの作成後は変更できません。
- v1.19.13以降のクラスタ
- ロードバランサーの作成後も変更可能です。
ロードバランサーを削除する時にFloating IPアドレスを保存するかどうかの設定
ロードバランサーにはFloating IPが接続されています。ロードバランサーの削除時にロードバランサーに接続されたFloating IPを削除あるいは保存するかどうかを設定できます。
- 設定位置は.metadata.annotations下のloadbalancer.openstack.org/keep-floatingipです。
- リスナー別設定を適用できません。
- 次の中から1つを設定できます。
- true:Floating IPを保存します。
- false:Floating IPを削除します。未設定時のデフォルト値です。
[注意] 2021年10月26日以前に作成されたv1.18.19クラスタは、ロードバランサーが削除される時、Floating IPが削除されない問題があります。サポートの1:1お問い合わせを通してお問い合わせください。この問題を解決するための手順を詳しくお伝えします。
ロードバランサーIP設定
ロードバランサーを作成するときにロードバランサーのIPを設定できます。
- 設定位置は .spec.loadBalancerIPです。
- リスナー別の設定を適用できません。
- 次のいずれかに設定できます。
- 空の文字列(""):ロードバランサーに自動的に作成されるFloating IPを接続します。未設定時のデフォルト値です。
:ロードバランサーに既存のFloating IPを接続します。すでに割り当てられているが接続されていないFloating IPがある場合に使用できます。
以下はロードバランサーにユーザー指定Floating IPを接続するマニフェストの例です。
# service-fip.yaml
apiVersion: v1
kind: Service
metadata:
name: nginx-svc-floatingIP
labels:
app: nginx
spec:
loadBalancerIP: <Floating_IP>
ports:
- port: 8080
targetPort: 80
protocol: TCP
selector:
app: nginx
type: LoadBalancer
Floating IP使用設定
ロードバランサーを作成するときにFloating IPを使用するかどうかを設定できます。
- 設定位置は .metadata.annotaions下のservice.beta.kubernetes.io/openstack-internal-load-balancerです。
- リスナー別の設定を適用できません。
- 次のいずれかに設定できます。
- true:Floating IPを使用せず、VIP(Virtual IP)を使用します。
- false:Floating IPを使用します。未設定時のデフォルト値です。
- VIPを使用する場合は.spec.loadBalancerIP項目を一緒に設定してロードバランサーに自動的に作成されるVIPを接続する代わりにVIPを指定して接続できます。
以下はロードバランサーにユーザー指定VIPを接続するマニフェストの例です。
# service-vip.yaml
apiVersion: v1
kind: Service
metadata:
name: nginx-svc-fixedIP
labels:
app: nginx
annotations:
service.beta.kubernetes.io/openstack-internal-load-balancer: "true"
spec:
loadBalancerIP: <Virtual_IP>
ports:
- port: 8080
targetPort: 80
protocol: TCP
selector:
app: nginx
type: LoadBalancer
Floating IP使用設定とロードバランサーIP設定の組み合わせによって、次のように動作します。
| Floating IP使用設定 | ロードバランサーIP設定 | 説明 |
|---|---|---|
| false | 未設定 | ロードバランサーにFloating IPを作成して接続します。 |
| false | 設定 | ロードバランサーに指定されたFloating IPを接続します。 |
| true | 未設定 | ロードバランサーに接続されるVIPを自動的に設定します。 |
| true | 設定 | ロードバランサーに指定されたVIPを接続します。 |
VPC設定
ロードバランサー作成時、ロードバランサーが接続されるVPCを設定できます。
- 設定位置は .metadata.annotaions下のloadbalancer.openstack.org/network-idです。
- リスナー別の設定を適用できません。
- 設定しない場合はクラスタ作成時に設定したVPCに設定します。
サブネット設定
ロードバランサー作成時、ロードバランサーが接続されるサブネットを設定できます。設定されたサブネットにロードバランサーのプライベートIPが接続されます。メンバーサブネット設定がない場合、このサブネットに接続されたワーカーノードがロードバランサーメンバーとして追加されます。
- 設定位置は .metadata.annotaions下のloadbalancer.openstack.org/subnet-idです。
- リスナー別の設定を適用できません。
- 設定しない場合はクラスタ作成時に設定したサブネットに設定します。
以下はロードバランサーにVPCとサブネットを設定するマニフェスト例です。
apiVersion: v1
kind: Service
metadata:
name: nginx-svc-vpc-subnet
labels:
app: nginx
annotations:
loadbalancer.openstack.org/network-id: "49a5820b-d941-41e5-bfc3-0fd31f2f6773"
loadbalancer.openstack.org/subnet-id: "38794fd7-fd2e-4f34-9c89-6dd3fd12f548"
spec:
ports:
- port: 8080
targetPort: 80
protocol: TCP
selector:
app: nginx
type: LoadBalancer
メンバーサブネット設定
ロードバランサー作成時、ロードバランサーメンバーが接続されるサブネットを設定できます。このサブネットに接続されたワーカーノードがロードバランサーメンバーとして追加されます。
- 設定場所は.metadata.annotaionsサブのloadbalancer.nhncloud/member-subnet-idです。
- リスナー別の設定を適用できません。
- 設定しない場合、ロードバランサーのサブネット設定値が適用されます。
- メンバーサブネットは**必ずロードバランサーサブネットと同じVPCに含まれている必要があります。
- 2つ以上のメンバーサブネットを設定するためには、コンマで区切られたリストで入力します。
以下はロードバランサーにVPC、サブネット、メンバーサブネットを設定するマニフェストの例です。
apiVersion: v1
kind: Service
metadata:
name: nginx-svc-vpc-subnet
labels:
app: nginx
annotations:
loadbalancer.openstack.org/network-id: "49a5820b-d941-41e5-bfc3-0fd31f2f6773"
loadbalancer.openstack.org/subnet-id: "38794fd7-fd2e-4f34-9c89-6dd3fd12f548"
loadbalancer.nhncloud/member-subnet-id: "c3548a5e-b73c-48ce-9dc4-4d4c484108bf"
spec:
ports:
- port: 8080
targetPort: 80
protocol: TCP
selector:
app: nginx
type: LoadBalancer
[注意] メンバーサブネットは2023年11月28日以降v1.24.3以上のバージョンにアップグレードされたか、新しく作成されたクラスタで設定可能です。
リスナー接続制限設定
リスナーの接続制限を設定できます。
- 設定位置は .metadata.annotations下のloadbalancer.nhncloud/connection-limitです。
- リスナー別設定を適用できます。
- v1.17.6, v1.18.19クラスタ
- 最小値1、最大値60000です。
- 設定しない場合は-1に設定され、実際のロードバランサーに適用される値は2000です。
- v1.19.13以降のクラスタ
- 最小値1、最大値60000です。
- 設定しない場合や範囲外の値を入力した場合はデフォルト値の60000に設定されます。
リスナープロトコル設定
リスナーのプロトコルを設定できます。
- 設定位置は .metadata.annotations下のloadbalancer.nhncloud/listener-protocolです。
- リスナー別設定を適用できます。
- 次のいずれかに設定できます。
- TCP:未設定時のデフォルト値です。
- HTTP
- HTTPS
- TERMINATED_HTTPS: TERMINATED_HTTPSに設定します。 SSLバージョン、証明書、秘密鍵情報を追加設定する必要があります。
[注意] リスナープロトコル設定はサービスオブジェクトを変更してもロードバランサーに適用されません。 リスナープロトコル設定を変更するにはサービスオブジェクトを削除した後、再度作成する必要があります。 この場合、ロードバランサーが削除された後、再び作成されますのでご注意ください。
SSLバージョンは次のように設定できます。
- 設定位置は .metadata.annotations下のloadbalancer.nhncloud/listener-terminated-https-tls-versionです。
- リスナー別設定を適用できます。
- 次のいずれかに設定できます。
- TLSv1.3:未設定時のデフォルト値です。
- TLSv1.2
- TLSv1.1
- TLSv1.0_2016
- TLSv1.0
- SSLv3
[注意] TLSv1.3は2022年3月29日以降に作成されたクラスタで設定可能です。
証明書情報は次のように設定できます。
- 設定位置は .metadata.annotations下のloadbalancer.nhncloud/listener-terminated-https-certです。
- リスナー別設定を適用できます。
- 開始行と終了行を含める必要があります。
秘密鍵情報は次のように設定できます。
- 設定位置は .metadata.annotations下のloadbalancer.nhncloud/listener-terminated-https-keyです。
- リスナー別設定を適用できます。
- 開始行と終了行を含める必要があります。
次はリスナープロトコルをTERMINATED_HTTPSに設定したときのマニフェスト例です。証明書情報と秘密鍵情報は一部省略されています。
metadata:
name: echosvr-svc
labels:
app: echosvr
annotations:
loadbalancer.nhncloud/listener-protocol: TERMINATED_HTTPS
loadbalancer.nhncloud/listener-terminated-https-tls-version: TLSv1.2
loadbalancer.nhncloud/listener-terminated-https-cert: |
-----BEGIN CERTIFICATE-----
MIIDZTCCAk0CCQDVfXIZ2uxcCTANBgkqhkiG9w0BAQUFADBvMQswCQYDVQQGEwJL
...
fnsAY7JvmAUg
-----END CERTIFICATE-----
loadbalancer.nhncloud/listener-terminated-https-key: |
-----BEGIN RSA PRIVATE KEY-----
MIIEowIBAAKCAQEAz+U5VNZ8jTPs2Y4NVAdUWLhsNaNjRWQm4tqVPTxIrnY0SF8U
...
u6X+8zlOYDOoS2BuG8d2brfKBLu3As5VAcAPLcJhE//3IVaZHxod
-----END RSA PRIVATE KEY-----
リスナープロキシプロトコル(Proxy Protocol)設定
リスナープロトコルがTCPまたはHTTPSの場合、リスナーにプロキシプロトコルを設定できます。プロキシプロトコルの詳細についてはロードバランサープロキシモードをご覧ください。
- 設定位置は.metadata.annotations下位のloadbalancer.nhncloud/proxy-protocolです。
- リスナーごとに設定を適用できます。
- 次のいずれかに設定できます。
- true:プロキシプロトコルを有効にします。
- false:プロキシプロトコルを無効にします。未設定時のデフォルト値です。
ロードバランシング方式設定
ロードバランシング方式を設定できます。
- 設定位置は .metadata.annotations下のloadbalancer.nhncloud/pool-lb-methodです。
- リスナー別設定を適用できます。
- 次のいずれかに設定できます。
- ROUND_ROBIN:未設定時のデフォルト値です。
- LEAST_CONNECTIONS
- SOURCE_IP
ヘルスチェックプロトコル設定
ヘルスチェックプロトコルを設定できます。
- 設定位置は .metadata.annotations下のloadbalancer.nhncloud/healthmonitor-typeです。
- リスナー別設定を適用できます。
- 次のいずれかに設定できます。
- HTTP:HTTP URL、HTTPメソッド、 HTTPステータスコードを追加設定する必要があります。
- HTTPS:HTTP URL、HTTPメソッド、 HTTPステータスコードを追加設定する必要があります。
- TCP:未設定時のデフォルト値です。
HTTP URLは次のように設定できます。
- 設定位置は .metadata.annotations下のloadbalancer.nhncloud/healthmonitor-http-urlです。
- リスナー別設定を適用できます。
- 設定値は /で始まる必要があります。
- 設定しない場合やルールに合わない値を入力した場合はデフォルト値である /に設定されます。
HTTPメソッドは次のように設定できます。
- 設定位置は .metadata.annotations下のloadbalancer.nhncloud/healthmonitor-http-methodです。
- リスナー別設定を適用できます。
- 現在GETのみサポートしており、設定していない場合や他の値を入力した場合はデフォルト値であるGETに設定されます。
HTTPステータスコードは次のように設定できます。
- 設定位置は .metadata.annotations下のloadbalancer.nhncloud/healthmonitor-http-expected-codeです。
- リスナー別設定を適用できます。
- 単一値(例:200)、リスト(例:200,202)、範囲(例:200-204)形式で入力できます。
- 設定しない場合やルールに合わない値を入力するとデフォルト値の200に設定されます。
ヘルスチェックサイクルの設定
ヘルスチェック周期を設定できます。
- 設定位置は.metadata.annotations下のloadbalancer.nhncloud/healthmonitor-delayです。
- リスナー別設定を適用できます。
- 秒単位で設定します。
- 最小値1、最大値5000です。
- 設定しない場合や範囲外の値を入力するとデフォルト値の60に設定されます。
ヘルスチェック最大レスポンス時間設定
ヘルスチェック最大レスポンス時間を設定できます。
- 設定位置は .metadata.annotations下のloadbalancer.nhncloud/healthmonitor-timeoutです。
- リスナー別設定を適用できます。
- 秒単位で設定します。
- 最小値1、最大値5000です。
- この設定は必ずヘルスチェックサイクル設定値より小さくする必要があります。
- 設定しない場合や範囲外の値を入力するとデフォルト値の30に設定されます。
- ただし、入力値または設定値がヘルスチェックサイクル設定より大きい場合は、ヘルスチェックサイクル設定の1/2に設定されます。
ヘルスチェック最大再試行回数設定
ヘルスチェック最大再試行回数を設定できます。
- 設定位置は .metadata.annotations下のloadbalancer.nhncloud/healthmonitor-max-retriesです。
- リスナー別設定を適用できます。
- 最小値1、最大値10です。
- 設定しない場合や範囲外の値を入力するとデフォルト値の3に設定されます。
keep-aliveタイムアウト設定
keep-aliveタイムアウト値を設定できます。
- 設定位置は .metadata.annotations下位のloadbalancer.nhncloud/keepalive-timeoutです。
- リスナーごとに設定を適用できます。
- 秒単位で設定します。
- 最小値0、最大値3600です。
- 設定しないか、範囲外の値を入力すると、デフォルト値である300に設定されます。
[注意] keep-alive timeoutは2023年11月28日以降にv1.24.3以上のバージョンにアップグレードされたか、新規に作成されたクラスタで設定可能です。
イングレスコントローラー
イングレスコントローラー(Ingress Controller)は、イングレスオブジェクトに定義されているルールを参照してクラスタ外部から内部サービスにHTTPとHTTPSリクエストをルーティングし、SSL/TSL終了、仮想ホスティングなどを提供します。イングレスコントローラーとイングレスの詳細についてはイングレスコントローラー、イングレス文書を参照してください。
NGINX Ingress Controllerのインストール
NGINX Ingress Controllerは、よく使われるイングレスコントローラーの1つです。詳細についてはNGINX Ingress ControllerとNGINX Ingress Controller for Kubernetes文書を参照してください。 NGINX Ingress ControllerのインストールはInstallation Guide文書を参照してください。
URIベースのサービス分岐
イングレスコントローラーはURIに基づいてサービスを分岐できます。次の図はURIに基づいてサービスを分岐する簡単な例の構造を表しています。
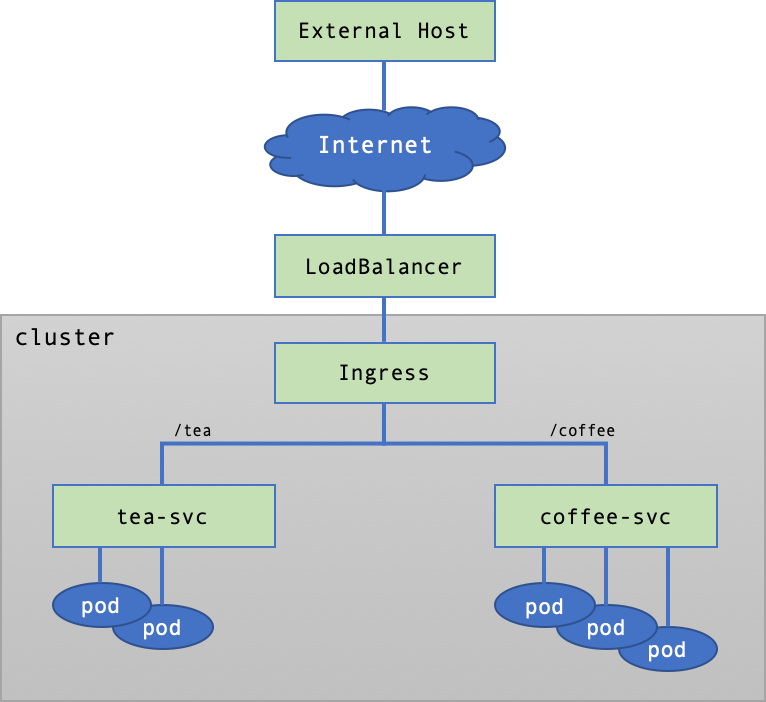
サービスとPod作成
次のようにサービスとPodを作成するためのマニフェストを作成します。 tea-svcサービスにはtea Podを接続し、coffee-svcサービスにはcoffee Podを接続します。
# cafe.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: coffee
spec:
replicas: 3
selector:
matchLabels:
app: coffee
template:
metadata:
labels:
app: coffee
spec:
containers:
- name: coffee
image: nginxdemos/nginx-hello:plain-text
ports:
- containerPort: 8080
---
apiVersion: v1
kind: Service
metadata:
name: coffee-svc
spec:
ports:
- port: 80
targetPort: 8080
protocol: TCP
name: http
selector:
app: coffee
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: tea
spec:
replicas: 2
selector:
matchLabels:
app: tea
template:
metadata:
labels:
app: tea
spec:
containers:
- name: tea
image: nginxdemos/nginx-hello:plain-text
ports:
- containerPort: 8080
---
apiVersion: v1
kind: Service
metadata:
name: tea-svc
labels:
spec:
ports:
- port: 80
targetPort: 8080
protocol: TCP
name: http
selector:
app: tea
マニフェストを適用し、デプロイメント、サービス、 Podが作成されたことを確認します。PodはRunning状態でなければなりません。
$ kubectl apply -f cafe.yaml
deployment.apps/coffee created
service/coffee-svc created
deployment.apps/tea created
service/tea-svc created
# kubectl get deploy,svc,pods
NAME READY UP-TO-DATE AVAILABLE AGE
deployment.apps/coffee 3/3 3 3 27m
deployment.apps/tea 2/2 2 2 27m
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
service/coffee-svc ClusterIP 10.254.171.198 <none> 80/TCP 27m
service/kubernetes ClusterIP 10.254.0.1 <none> 443/TCP 5h51m
service/tea-svc ClusterIP 10.254.184.190 <none> 80/TCP 27m
NAME READY STATUS RESTARTS AGE
pod/coffee-7c86d7d67c-pr6kw 1/1 Running 0 27m
pod/coffee-7c86d7d67c-sgspn 1/1 Running 0 27m
pod/coffee-7c86d7d67c-tqtd6 1/1 Running 0 27m
pod/tea-5c457db9-fdkxl 1/1 Running 0 27m
pod/tea-5c457db9-z6hl5 1/1 Running 0 27m
イングレス(Ingress)作成
リクエストパスに基づいてサービスに接続するイングレスマニフェストを作成します。エンドポイントが/teaのリクエストはtea-svcサービスに接続し、/coffeeのリクエストはcoffee-svcサービスに接続します。
# cafe-ingress-uri.yaml
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: cafe-ingress-uri
spec:
ingressClassName: nginx
rules:
- http:
paths:
- path: /tea
pathType: Prefix
backend:
service:
name: tea-svc
port:
number: 80
- path: /coffee
pathType: Prefix
backend:
service:
name: coffee-svc
port:
number: 80
イングレスを作成し、しばらくしてから確認したときにADDRESSフィールドにIPが設定されている必要があります。
$ kubectl apply -f cafe-ingress-uri.yaml
ingress.networking.k8s.io/cafe-ingress-uri created
$ kubectl get ingress cafe-ingress-uri
NAME CLASS HOSTS ADDRESS PORTS AGE
cafe-ingress-uri nginx * 123.123.123.44 80 23s
HTTPリクエストの送信
外部ホストからingressのADDRESSフィールドに設定されたIPアドレスにHTTPリクエストを送信してイングレスが正しく設定されていることを確認します。
エンドポイント/coffeeに対するリクエストはcoffee-svcサービスに渡され、coffee Podがレスポンスします。レスポンスのServer name項目を見るとcoffee Podがラウンドロビン方式で交互にレスポンスすることを確認できます。
$ curl 123.123.123.44/coffee
Server address: 10.100.24.21:8080
Server name: coffee-7c86d7d67c-sgspn
Date: 11/Mar/2022:06:28:18 +0000
URI: /coffee
Request ID: 3811d20501dbf948259f4b209c00f2f1
$ curl 123.123.123.44/coffee
Server address: 10.100.24.19:8080
Server name: coffee-7c86d7d67c-tqtd6
Date: 11/Mar/2022:06:28:27 +0000
URI: /coffee
Request ID: ec82f6ab31d622895374df972aed1acd
$ curl 123.123.123.44/coffee
Server address: 10.100.24.20:8080
Server name: coffee-7c86d7d67c-pr6kw
Date: 11/Mar/2022:06:28:31 +0000
URI: /coffee
Request ID: fec4a6111bcc27b9cba52629e9420076
同様に、エンドポイント/teaに対するリクエストはtea-svcサービスに渡され、tea Podがレスポンスします。
$ curl 123.123.123.44/tea
Server address: 10.100.24.23:8080
Server name: tea-5c457db9-fdkxl
Date: 11/Mar/2022:06:28:36 +0000
URI: /tea
Request ID: 11be1b7634a371a26e6bf2d3e72ab8aa
$ curl 123.123.123.44/tea
Server address: 10.100.24.22:8080
Server name: tea-5c457db9-z6hl5
Date: 11/Mar/2022:06:28:37 +0000
URI: /tea
Request ID: 21106246517263d726931e0f85ea2887
定義されていないURIにリクエストを送信すると、イングレスコントローラーが404 Not Foundをレスポンスします。
$ curl 123.123.123.44/unknown
<html>
<head><title>404 Not Found</title></head>
<body>
<center><h1>404 Not Found</h1></center>
<hr><center>nginx</center>
</body>
</html>
リソース削除
テストに使用したリソースは作成するときに使用したマニフェストを利用して削除できます。
$ kubectl delete -f cafe-ingress-uri.yaml
ingress.networking.k8s.io "cafe-ingress-uri" deleted
$ kubectl delete -f cafe.yaml
deployment.apps "coffee" deleted
service "coffee-svc" deleted
deployment.apps "tea" deleted
service "tea-svc" deleted
ホストベースのサービス分岐
イングレスコントローラーはホスト名に基づいてサービスを分岐できます。次の図はホスト名に基づいてサービスを分岐する簡単な例の構造を表しています。
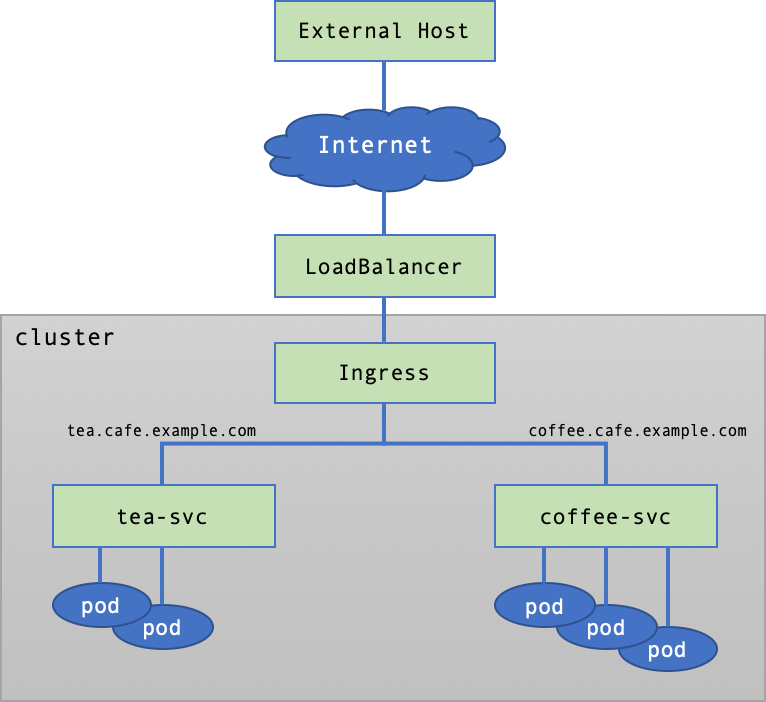
サービスとPod作成
URIベースのサービス分岐と同じマニフェストを利用してサービスとPodを作成します。
イングレス作成
ホスト名に基づいてサービスに接続するイングレスマニフェストを作成します。 tea.cafe.example.comホストに入ったリクエストはtea-svcサービスに接続し、coffee.cafe.example.comホストに入ったリクエストはcoffee-svcサービスに接続します。
# cafe-ingress-host.yaml
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: cafe-ingress-host
spec:
ingressClassName: nginx
rules:
- host: tea.cafe.example.com
http:
paths:
- path: /
pathType: Prefix
backend:
service:
name: tea-svc
port:
number: 80
- host: coffee.cafe.example.com
http:
paths:
- path: /
pathType: Prefix
backend:
service:
name: coffee-svc
port:
number: 80
イングレスを作成し、しばらくしてから確認したときにADDRESSフィールドにIPが設定されている必要があります。
$ kubectl apply -f cafe-ingress-host.yaml
ingress.networking.k8s.io/cafe-ingress-host created
$ kubectl get ingress
NAME CLASS HOSTS ADDRESS PORTS AGE
cafe-ingress-host nginx tea.cafe.example.com,coffee.cafe.example.com 123.123.123.44 80 36s
HTTP Request送信
外部ホストからイングレスのADDRESSに設定されたIPにHTTPリクエストを送信します。ただしホスト名を利用してサービスを分岐するようにイングレスを構成したため、ホスト名を利用してリクエストを送信する必要があります。
[参考] 任意のホスト名を使用してテストするにはcurlの --resolveオプションを使用します。 --resolveオプションは
{ホスト名}:{ポート番号}:{IP}の形式で入力します。これは{ホスト名}に送る{ポート番号}のリクエストを{IP}で解析(resolve)しろという意味です。/etc/hostファイルを開き{IP} {ホスト名}形式で追加することもできます。
ホストcoffee.cafe.example.comにリクエストを送信するとcoffee-svcサービスに渡されてcoffee Podがレスポンスします。
$ curl --resolve coffee.cafe.example.com:80:123.123.123.44 http://coffee.cafe.example.com/
Server address: 10.100.24.27:8080
Server name: coffee-7c86d7d67c-fqn6n
Date: 11/Mar/2022:06:40:59 +0000
URI: /
Request ID: 1efb60d29891d6d48b5dcd9f5e1ba66d
ホストtea.cafe.example.comにリクエストを送信するとtea-svcサービスに渡されてtea Podがレスポンスします。
$ curl --resolve tea.cafe.example.com:80:123.123.123.44 http://tea.cafe.example.com/
Server address: 10.100.24.28:8080
Server name: tea-5c457db9-ngrxq
Date: 11/Mar/2022:06:41:39 +0000
URI: /
Request ID: 5a6cc490893636029766b02d2aab9e39
不明なホストにリクエストを送るとイングレスコントローラーが404 Not Foundを返します。
$ curl 123.123.123.44/unknown
<html>
<head><title>404 Not Found</title></head>
<body>
<center><h1>404 Not Found</h1></center>
<hr><center>nginx</center>
</body>
</html>
Kubernetesダッシュボード
NHN Kubernetes Service(NKS)は基本Web UIダッシュボード(dashboard)を提供します。 Kubernetesダッシュボードの詳細についてはWeb UI (ダッシュボード)文書を参照してください。
[注意] * KubernetesダッシュボードはNKS v1.25.4までのみ基本提供します。 * NKSクラスタバージョンをv1.25.4からv1.26.3にアップグレードしても、動作中のKubernetesダッシュボードPodと関連リソースはそのまま維持されます。 * NHN CloudコンソールでKubernetesリソースを照会できます。
ダッシュボードサービス公開
ユーザーKubernetesにはダッシュボードを公開するためのkubernetes-dashboardサービスオブジェクトがあらかじめ作成されています。
$ kubectl get svc kubernetes-dashboard -n kube-system
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
kubernetes-dashboard ClusterIP 10.254.85.2 <none> 443/TCP 6h
$ kubectl describe svc kubernetes-dashboard -n kube-system
Name: kubernetes-dashboard
Namespace: kube-system
Labels: k8s-app=kubernetes-dashboard
Annotations: <none>
Selector: k8s-app=kubernetes-dashboard
Type: ClusterIP
IP Family Policy: SingleStack
IP Families: IPv4
IP: 10.254.85.2
IPs: 10.254.85.2
Port: <unset> 443/TCP
TargetPort: 8443/TCP
Endpoints: 10.100.24.7:8443
Session Affinity: None
Events: <none>
しかしkubernetes-dashboardサービスオブジェクトはClusterIPタイプのため、まだクラスタ外部に公開されていません。ダッシュボードを外部公開するにはサービスオブジェクトをLoadBalancerタイプに変更するか、イングレスコントローラーとイングレスオブジェクトを作成する必要があります。
LoadBalancerサービスオブジェクトに変更
LoadBalancerタイプにサービスオブジェクトを変更すると、クラスタ外部にNHN Cloud Load Balancerが作成され、ロードバランサーとサービスオブジェクトに接続されます。ロードバランサーに接続したサービスオブジェクトを照会するとEXTERNAL-IPフィールドにロードバランサーのIPが表示されます。 LoadBalancerタイプのサービスオブジェクトについてはLoadBalancerサービスを参照してください。次の図はLoadBalancerタイプのサービスを利用してダッシュボードを外部に公開する構造を表しています。
次のようにkubernetes-dashboardサービスオブジェクトのタイプをLoadBalancerに変更します。
$ kubectl -n kube-system patch svc/kubernetes-dashboard -p '{"spec":{"type":"LoadBalancer"}}'
service/kubernetes-dashboard patched
kubernetes-dashboardサービスオブジェクトがLoadBalancerタイプに変更されると、しばらくした後EXTERNAL-IPフィールドでロードバランサーIPを確認できます。
$ kubectl get svc -n kube-system
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
...
kubernetes-dashboard LoadBalancer 10.254.95.176 123.123.123.81 443:30963/TCP 2d23h
[参考] 作成されたロードバランサーは Network > Load Balancerページで確認できます。 ロードバランサーのIPは外部からアクセスできるFloating IPです。 Network > Floating IPページで確認できます。
Webブラウザでhttps://{EXTERNAL-IP}に接続するとKubernetesダッシュボードページがローディングされます。ログインのために必要なトークンはダッシュボードアクセストークンを参照してください。
[参考] Kubernetesダッシュボードは自動作成されるプライベート証明書を使用するため、Webブラウザの種類とセキュリティ設定によっては安全ではないページと表示されることがあります。
イングレス(Ingress)を利用したサービス公開
イングレスは、クラスタ内部の複数のサービスにアクセスするためのルーティングを提供するネットワークオブジェクトです。イングレスオブジェクトの設定は、イングレスコントローラーで動作します。 kubernetes-dashboardサービスオブジェクトをイングレスを介して公開できます。イングレスとイングレスコントローラーの詳細についてはイングレスコントローラーを参照してください。次の図はイングレスを介してダッシュボードを外部に公開する構造を表しています。
NGINX Ingress Controllerインストールを参照してNGINX Ingress Controllerをインストールして次のようにイングレスオブジェクトを作成するためのマニフェストを作成します。
# kubernetes-dashboard-ingress-tls-passthrough.yaml
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: k8s-dashboard-ingress
namespace: kube-system
annotations:
ingress.kubernetes.io/ssl-passthrough: "true"
kubernetes.io/ingress.allow-http: "false"
nginx.ingress.kubernetes.io/backend-protocol: HTTPS
nginx.ingress.kubernetes.io/proxy-body-size: 100M
nginx.ingress.kubernetes.io/rewrite-target: /
nginx.org/ssl-backend: kubernetes-dashboard
spec:
ingressClassName: nginx
rules:
- http:
paths:
- path: /
pathType: Prefix
backend:
service:
name: kubernetes-dashboard
port:
number: 443
tls:
- secretName: kubernetes-dashboard-certs
マニフェストを適用してイングレスを作成し、イングレスオブジェクトのADDRESSフィールドを確認します。
$ kubectl apply -f kubernetes-dashboard-ingress-tls-passthrough.yaml
ingress.networking.k8s.io/k8s-dashboard-ingress created
$ kubectl get ingress -n kube-system
NAME CLASS HOSTS ADDRESS PORTS AGE
k8s-dashboard-ingress nginx * 123.123.123.44 80, 443 34s
Webブラウザでhttps://{ADDRESS}に接続するとKubernetesダッシュボードページがローディングされます。ログインのために必要なトークンはダッシュボードアクセストークンを参照してください。
ダッシュボードアクセストークン
Kubernetesダッシュボードにログインするにはトークンが必要です。トークンは次のコマンドで取得できます。
# SECRET_NAME=$(kubectl -n kube-system get secrets | grep "kubernetes-dashboard-token" | cut -f1 -d ' ')
$ kubectl describe secret $SECRET_NAME -n kube-system | grep -E '^token' | cut -f2 -d':' | tr -d " "
eyJhbGc...-QmXA
出力されたトークンをブラウザのトークン入力ウィンドウに入力すると、クラスタ管理者権限を付与されたユーザーとしてログインできます。
パシステントボリューム
パシステントボリューム(Persistent Volume, PV)は物理記憶装置(volume)を表すKubernetesのリソースです。1つのPVは1つのNHN Cloud Block Storageに接続されます。詳細についてはパシステントボリューム文書を参照してください。
PVをPodに接続して使用するにはパシステントボリュームクレーム(Persistent Volume Claims, PVC)オブジェクトが必要です。 PVCは容量、読み取り/書き込みモードなど必要なボリュームの要求事項を定義します。
PVとPVCでユーザーは使用したいボリュームのプロパティを定義し、システムはユーザーの要求事項に合ったボリュームリソースを割り当てる方式でリソースの使用と管理を分離します。
PV/PVCのライフサイクル
PVとPVCは4段階のライフサイクル(life cycle)に従います。
-
プロビジョニング(provisioning) ストレージクラスを使用してユーザーが直接ボリュームを確保し、PVを作成(static provisioning)したり、動的に作成(dynamic provisioning)できます。
-
バインディング(binding) PVとPVCを1:1でバインディングします。動的プロビジョニングでPVを作成した場合はバインディングも自動的に行われます。
-
使用(using) PVをPodにマウントして使用します。
-
変換(reclaiming) 使用を終えたボリュームを回収します。回収方法は削除(Delete)、保存(Retain)、再使用(Recycle)があります。
| 方法 | 説明 |
|---|---|
| 削除(Delete) | PVを削除するとき、接続しているボリュームを一緒に削除します。 |
| 保存(Retain) | PVを削除するとき、接続しているボリュームを削除しません。ボリュームはユーザーが直接削除するか再利用できます。 |
| 再利用(Recycle) | PVを削除するとき、接続しているボリュームを削除せず、再利用できる状態にします。この方法は停止(deprecated)しています。 |
ストレージクラス(StorageClass)
プロビジョニングを行うには、まずストレージクラスが定義されている必要があります。ストレージクラスは特定の特性でストレージを分類できる方法を提供します。ストレージ提供者(provisioner)の情報を含め、メディアの種類やアベイラビリティゾーンなどを設定できます。
ストレージ提供者(provisioner)
ストレージの提供者情報を設定します。Kubernetesバージョンに応じてサポートされているストレージプロバイダー情報は次のとおりです。
- v1.19.13以前のバージョン:provisionerフィールドを必ず
kubernetes.io/cinderに設定する必要があります。 - v1.20.12以降のバージョン:provisionerフィールドを
cinder.csi.openstack.orgに設定して使用できます。
パラメータ(parameter)
ストレージクラスを介して次のパラメータを設定できます。
- ストレージ種類(type):ストレージの種類を入力します。(未入力の場合はGeneral HDDが設定されます)
- General HDD:ストレージ種類がHDDに設定されます。
- General SSD:ストレージ種類がSSDに設定されます。
- アベイラビリティゾーン(availability):アベイラビリティゾーンを設定します。(未入力の場合はランダムに設定されます)
- パンギョリージョン:kr-pub-aまたはkr-pub-b
- 坪村リージョン:kr2-pub-aまたはkr2-pub-b
ボリュームバインディングモード(VolumeBindingMode)
ボリュームバインディングモードは、ボリュームバインディングと動的プロビジョニングの開始時点を制御します。この設定はストレージ提供者がcinder.csi.openstack.orgの場合にのみ設定できます。
- Immediate:パシステントボリュームクレームが作成されるとすぐにボリュームバインディングと動的プロビジョニングが始まります。パシステントボリュームクレームが作成される時点ではボリュームを接続するPodの事前知識がない状態です。そのためボリュームのアベイラビリティゾーンとPodがスケジューリングされるノードのアベイラビリティゾーンが異なる場合はPodが正常に動作しません。
- WaitForFirstConsumer:パシステントボリュームクレームが作成されるときはボリュームバインディングと動的プロビジョニングを行いません。このパシステントボリュームクレームが初めてPodに接続すると、 Podがスケジューリングされたノードのアベイラビリティゾーン情報をもとにボリュームバインディングと動的プロビジョニングを行います。したがってImmediateモードなど、ボリュームのアベイラビリティゾーンとインスタンスのアベイラビリティゾーンが異なりPodが正常に動作しない場合が発生しません。
ボリューム拡張許可(allowVolumeExpansion)
作成されたボリュームの拡張を許可するかどうかを設定します(未入力の場合はfalseが設定されます)。
- True:ボリューム拡張を許可します。
- False:ボリューム拡張を許可しません。
例1
以下のストレージクラスマニフェストはv1.19.13以前のバージョンを使用するKubernetesクラスタで使用できます。パラメータを介してアベイラビリティゾーンとボリュームタイプを指定できます。
# storage_class.yaml
apiVersion: storage.k8s.io/v1
kind: StorageClass
metadata:
name: sc-ssd
provisioner: kubernetes.io/cinder
parameters:
type: General SSD
availability: kr-pub-a
ストレージクラスを作成して確認します。
$ kubectl apply -f storage_class.yaml
storageclass.storage.k8s.io/sc-ssd created
$ kubectl get sc
NAME PROVISIONER RECLAIMPOLICY VOLUMEBINDINGMODE ALLOWVOLUMEEXPANSION AGE
sc-ssd kubernetes.io/cinder Delete Immediate false 3s
例2
次のストレージクラスマニフェストは、v1.20.12以降のバージョンを使用するKubernetesクラスタで使用できます。ボリュームバインディングモードをWaitForFirstConsumerに設定してパシステントボリュームクレームがPodに接続されるときにボリュームバインディングと動的プロビジョニングを開始します。
# storage_class_csi.yaml
apiVersion: storage.k8s.io/v1
kind: StorageClass
metadata:
name: csi-storageclass
provisioner: cinder.csi.openstack.org
volumeBindingMode: WaitForFirstConsumer
ストレージクラスを作成して確認します。
$ kubectl apply -f storage_class_csi.yaml
storageclass.storage.k8s.io/csi-storageclass created
$ kubectl get sc
NAME PROVISIONER RECLAIMPOLICY VOLUMEBINDINGMODE ALLOWVOLUMEEXPANSION AGE
csi-storageclass cinder.csi.openstack.org Delete WaitForFirstConsumer false 7s
静的プロビジョニング
静的プロビジョニング(static provisioning)は、ユーザーが直接ブロックストレージを準備する必要があります。 NHN Cloud WebコンソールのStorage > Block Storageサービスページでブロックストレージ作成ボタンをクリックしてPVに接続するブロックストレージを作成します。ブロックストレージガイドのブロックストレージ作成を参照してください。
PVを作成するにはブロックストレージのIDが必要です。Storage > Block Storageサービスページのブロックストレージリストから使用するブロックストレージを選択します。下の情報タブのブロックストレージ名項目でIDを確認できます。
ブロックストレージと接続するPVマニフェストを作成します。spec.storageClassNameにはストレージクラス名を入力します。 NHN Cloud Block Storageを使用するにはspec.accessModesは必ずReadWriteOnceに設定する必要があります。spec.presistentVolumeReclaimPolicyはDeleteまたはRetainに設定できます。
v1.20.12以降のバージョンのクラスタはcinder.csi.openstack.orgストレージプロバイダを使用する必要があります。ストレージプロバイダを定義するには、spec.annotationsの下にpv.kubernetes.io/provisioned-by: cinder.csi.openstack.orgを指定し、csiの下にdriver: cinder.csi.openstack.orgを指定します。
[注意] Kubernetesバージョンに合ったストレージ提供者が定義されているストレージクラスを設定する必要があります。
# pv-static.yaml
apiVersion: v1
kind: PersistentVolume
metadata:
annotations:
pv.kubernetes.io/provisioned-by: cinder.csi.openstack.org
name: pv-static-001
spec:
capacity:
storage: 10Gi
volumeMode: Filesystem
accessModes:
- ReadWriteOnce
persistentVolumeReclaimPolicy: Delete
storageClassName: sc-default
csi:
driver: cinder.csi.openstack.org
fsType: "ext3"
volumeHandle: "e6f95191-d58b-40c3-a191-9984ce7532e5"
PVを作成して確認します。
$ kubectl apply -f pv-static.yaml
persistentvolume/pv-static-001 created
$ kubectl get pv -o wide
NAME CAPACITY ACCESS MODES RECLAIM POLICY STATUS CLAIM STORAGECLASS REASON AGE VOLUMEMODE
pv-static-001 10Gi RWO Delete Available sc-default 7s Filesystem
作成したPVを使用するためのPVCマニフェストを作成します。spec.volumeNameにはPVの名前を指定する必要があります。他の項目はPVマニフェストの内容と同じように設定します。
# pvc-static.yaml
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: pvc-static
namespace: default
spec:
volumeName: pv-static-001
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 10Gi
storageClassName: sc-default
PVCを作成して確認します。
$ kubectl apply -f pvc-static.yaml
persistentvolumeclaim/pvc-static created
$ kubectl get pvc -o wide
NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS AGE VOLUMEMODE
pvc-static Bound pv-static-001 10Gi RWO sc-default 7s Filesystem
PVCを作成した後、PVの状態を照会してみるとCLAIM項目にPVC名が指定され、STATUS項目がBoundに変更されていることを確認できます。
$ kubectl get pv -o wide
NAME CAPACITY ACCESS MODES RECLAIM POLICY STATUS CLAIM STORAGECLASS REASON AGE VOLUMEMODE
pv-static-001 10Gi RWO Delete Bound default/pvc-static sc-default 79s Filesystem
動的プロビジョニング
動的プロビジョニング(dynamic provisioning)はストレージクラスに定義されているプロパティを参照して自動的にブロックストレージを作成します。動的プロビジョニングを使用するには、ストレージクラスのボリュームバインディングモード設定を行わないか、Immediateに設定する必要があります。
# storage_class_csi_dynamic.yaml
apiVersion: storage.k8s.io/v1
kind: StorageClass
metadata:
name: csi-storageclass-dynamic
provisioner: cinder.csi.openstack.org
volumeBindingMode: Immediate
動的プロビジョニングはPVを作成する必要がありません。したがってPVCマニフェストにはspec.volumeNameを設定しません。
# pvc-dynamic.yaml
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: pvc-dynamic
namespace: default
spec:
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 10Gi
storageClassName: csi-storageclass-dynamic
ボリュームバインディングモードを設定しない場合やImmediateに設定してPVCを作成する場合はPVが自動的に作成されます。 PVに接続されたブロックストレージも自動的に作成され、NHN Cloud WebコンソールStorage > Block Storageサービスページのブロックストレージリストで確認できます。
$ kubectl apply -f pvc-dynamic.yaml
persistentvolumeclaim/pvc-dynamic created
$ kubectl get sc,pv,pvc
NAME PROVISIONER RECLAIMPOLICY VOLUMEBINDINGMODE ALLOWVOLUMEEXPANSION AGE
storageclass.storage.k8s.io/csi-storageclass-dynamic cinder.csi.openstack.org Delete Immediate false 50s
NAME CAPACITY ACCESS MODES RECLAIM POLICY STATUS CLAIM STORAGECLASS REASON AGE
persistentvolume/pvc-1056949c-bc67-45cc-abaa-1d1bd9e51467 10Gi RWO Delete Bound default/pvc-dynamic csi-storageclass-dynamic 5s
NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS AGE
persistentvolumeclaim/pvc-dynamic Bound pvc-1056949c-bc67-45cc-abaa-1d1bd9e51467 10Gi RWO csi-storageclass-dynamic 9s
[注意] 動的プロビジョニングで作成されたブロックストレージはWebコンソールから削除できません。またクラスタを削除するとき、自動的に削除されません。したがってクラスタを削除する前にPVCをすべて削除する必要があります。PVCを削除せずにクラスタを削除すると課金されることがあります。動的プロビジョニングを作成されたPVCのreclaimPolicyは基本的に
Deleteに設定されるため、PVを削除するだけでPVとブロックストレージが削除されます。
PodにPVCマウント
PodにPVCをマウントするにはPodマニフェストにマウント情報を定義する必要があります。 spec.volumes.persistenVolumeClaim.claimNameに使用するPVC名を入力します。そしてspec.containers.volumeMounts.mountPathにマウントするパスを入力します。
次の例は静的プロビジョニングで作成したPVCをPodの/usr/share/nginx/htmlにマウントします。
# pod-pvc.yaml
apiVersion: v1
kind: Pod
metadata:
name: nginx-with-static-pv
spec:
containers:
- name: web
image: nginx
ports:
- name: web
containerPort: 80
hostPort: 8082
protocol: TCP
volumeMounts:
- name: html-volume
mountPath: "/usr/share/nginx/html"
volumes:
- name: html-volume
persistentVolumeClaim:
claimName: pvc-static
Podを作成し、ブロックストレージがマウントされていることを確認します。
$ kubectl apply -f pod-static-pvc.yaml
pod/nginx-with-static-pv created
$ kubectl get pods
NAME READY STATUS RESTARTS AGE
nginx-with-static-pv 1/1 Running 0 50s
$ kubectl exec -ti nginx-with-static-pv -- df -h
Filesystem Size Used Avail Use% Mounted on
...
/dev/vdc 9.8G 23M 9.7G 1% /usr/share/nginx/html
...
NHN Cloud WebコンソールStorage > Block Storageサービスページでもブロックストレージの接続情報を確認できます。
ボリューム拡張の許可(allowVolumeExpansion)
作成されたボリュームの拡張を許可するかどうかを設定します(未入力の場合はfalseが設定されます)。
- True:ボリュームの拡張を許可します。
- False:ボリュームの拡張を許可しません。
例1
以下のストレージクラスマニフェストはv1.19.13以前のバージョンを使用するKubernetesクラスタで使用できます。パラメータを利用してアベイラビリティゾーンとボリュームタイプを指定できます。
# storage_class.yaml
apiVersion: storage.k8s.io/v1
kind: StorageClass
metadata:
name: sc-ssd
provisioner: kubernetes.io/cinder
parameters:
type: General SSD
availability: kr-pub-a
ストレージクラスを作成し、確認します。
$ kubectl apply -f storage_class.yaml
storageclass.storage.k8s.io/sc-ssd created
$ kubectl get sc
NAME PROVISIONER RECLAIMPOLICY VOLUMEBINDINGMODE ALLOWVOLUMEEXPANSION AGE
sc-ssd kubernetes.io/cinder Delete Immediate false 3s
例2
以下のストレージクラスマニフェストはv1.20.12以降のバージョンを使用するKubernetesクラスタで使用できます。ボリュームバインディングモードをWaitForFirstConsumerに設定してパシステントボリュームクレームがPodに接続される時にボリュームバインディングと動的プロビジョニングを開始します。
# storage_class_csi.yaml
apiVersion: storage.k8s.io/v1
kind: StorageClass
metadata:
name: csi-storageclass
provisioner: cinder.csi.openstack.org
volumeBindingMode: WaitForFirstConsumer
ストレージクラスを作成し、確認します。
$ kubectl apply -f storage_class_csi.yaml
storageclass.storage.k8s.io/csi-storageclass created
$ kubectl get sc
NAME PROVISIONER RECLAIMPOLICY VOLUMEBINDINGMODE ALLOWVOLUMEEXPANSION AGE
csi-storageclass cinder.csi.openstack.org Delete WaitForFirstConsumer false 7s
静的プロビジョニング
静的プロビジョニング(static provisioning)はユーザーが直接ブロックストレージを準備する必要があります。NHN Cloud WebコンソールのStorage > Block Storageサービスページでブロックストレージ作成ボタンをクリックしてPVと接続するブロックストレージを作成します。ブロックストレージガイドのブロックストレージ作成を参照してください。
PVを作成するにはブロックストレージのIDが必要です。Storage > Block Storageサービスページのブロックストレージリストから使用するブロックストレージを選択します。下部の情報タブのブロックストレージ名項目でIDを確認できます。
ブロックストレージと接続するPVマニフェストを作成します。spec.storageClassNameにはストレージクラス名を入力します。NHN Cloud Block Storageを使用するにはspec.accessModesは必ずReadWriteOnceに設定する必要があります。spec.presistentVolumeReclaimPolicyはDeleteまたはRetainに設定できます。
[注意] Kubernetesバージョンに合ったストレージプロバイダーが定義されたストレージクラスを設定する必要があります。
# pv-static.yaml
apiVersion: v1
kind: PersistentVolume
metadata:
name: pv-static-001
spec:
capacity:
storage: 10Gi
volumeMode: Filesystem
accessModes:
- ReadWriteOnce
persistentVolumeReclaimPolicy: Delete
storageClassName: sc-default
cinder:
fsType: "ext3"
volumeID: "e6f95191-d58b-40c3-a191-9984ce7532e5"
PVを作成し、確認します。
$ kubectl apply -f pv-static.yaml
persistentvolume/pv-static-001 created
$ kubectl get pv -o wide
NAME CAPACITY ACCESS MODES RECLAIM POLICY STATUS CLAIM STORAGECLASS REASON AGE VOLUMEMODE
pv-static-001 10Gi RWO Delete Available sc-default 7s Filesystem
作成したPVを使用するためのPVCマニフェストを作成します。spec.volumeNameにはPVの名前を指定する必要があります。他の項目はPVマニフェストの内容と同じように設定します。
# pvc-static.yaml
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: pvc-static
namespace: default
spec:
volumeName: pv-static-001
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 10Gi
storageClassName: sc-default
PVCを作成し、確認します。
$ kubectl apply -f pvc-static.yaml
persistentvolumeclaim/pvc-static created
$ kubectl get pvc -o wide
NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS AGE VOLUMEMODE
pvc-static Bound pv-static-001 10Gi RWO sc-default 7s Filesystem
PVCを作成した後、PVの状態を照会してみると、CLAIM項目にPVC名が指定され、STATUS項目がBoundに変更されていることを確認できます。
$ kubectl get pv -o wide
NAME CAPACITY ACCESS MODES RECLAIM POLICY STATUS CLAIM STORAGECLASS REASON AGE VOLUMEMODE
pv-static-001 10Gi RWO Delete Bound default/pvc-static sc-default 79s Filesystem
動的プロビジョニング
動的プロビジョニング(dynamic provisioning)はストレージクラスに定義されたプロパティを参照して自動的にブロックストレージを作成します。動的プロビジョニングを使用するにはストレージクラスのボリュームバインディングモードを設定しないか、Immediateに設定する必要があります。
# storage_class_csi_dynamic.yaml
apiVersion: storage.k8s.io/v1
kind: StorageClass
metadata:
name: csi-storageclass-dynamic
provisioner: cinder.csi.openstack.org
volumeBindingMode: Immediate
動的プロビジョニングはPVを作成する必要がありません。したがってPVCマニフェストにはspec.volumeNameを設定しません。
# pvc-dynamic.yaml
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: pvc-dynamic
namespace: default
spec:
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 10Gi
storageClassName: csi-storageclass-dynamic
ボリュームバインディングモードを設定しないか、Immediateに設定してPVCを作成すると、PVが自動的に作成されます。PVに接続されたブロックストレージも自動的に作成され、NHN Cloud WebコンソールStorage > Block Storageサービスページのブロックストレージリストで確認できます。
$ kubectl apply -f pvc-dynamic.yaml
persistentvolumeclaim/pvc-dynamic created
$ kubectl get sc,pv,pvc
NAME PROVISIONER RECLAIMPOLICY VOLUMEBINDINGMODE ALLOWVOLUMEEXPANSION AGE
storageclass.storage.k8s.io/csi-storageclass-dynamic cinder.csi.openstack.org Delete Immediate false 50s
NAME CAPACITY ACCESS MODES RECLAIM POLICY STATUS CLAIM STORAGECLASS REASON AGE
persistentvolume/pvc-1056949c-bc67-45cc-abaa-1d1bd9e51467 10Gi RWO Delete Bound default/pvc-dynamic csi-storageclass-dynamic 5s
NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS AGE
persistentvolumeclaim/pvc-dynamic Bound pvc-1056949c-bc67-45cc-abaa-1d1bd9e51467 10Gi RWO csi-storageclass-dynamic 9s
[注意] 動的プロビジョニングによって作成されたブロックストレージはWebコンソールから削除できません。またクラスタを削除する時に自動的に削除されません。したがってクラスタを削除する前にPVCを全て削除する必要があります。PVCを削除せずにクラスタを削除すると課金される可能性があります。動的プロビジョニングを作成されたPVのreclaimPolicyは基本的に
Deleteに設定されるため、PVCのみ削除してもPVとブロックストレージが削除されます。
PodにPVCマウント
PodにPVCをマウントするにはPodマニフェストにマウント情報を定義する必要があります。spec.volumes.persistenVolumeClaim.claimNameに使用するPVC名を入力します。そしてspec.containers.volumeMounts.mountPathにマウントするパスを入力します。
以下の例は静的プロビジョニングで作成したPVCをPodの/usr/share/nginx/htmlにマウントします。
# pod-pvc.yaml
apiVersion: v1
kind: Pod
metadata:
name: nginx-with-static-pv
spec:
containers:
- name: web
image: nginx
ports:
- name: web
containerPort: 80
hostPort: 8082
protocol: TCP
volumeMounts:
- name: html-volume
mountPath: "/usr/share/nginx/html"
volumes:
- name: html-volume
persistentVolumeClaim:
claimName: pvc-static
Podを作成し、ブロックストレージがマウントされていることを確認します。
$ kubectl apply -f pod-static-pvc.yaml
pod/nginx-with-static-pv created
$ kubectl get pods
NAME READY STATUS RESTARTS AGE
nginx-with-static-pv 1/1 Running 0 50s
$ kubectl exec -ti nginx-with-static-pv -- df -h
Filesystem Size Used Avail Use% Mounted on
...
/dev/vdc 9.8G 23M 9.7G 1% /usr/share/nginx/html
...
NHN Cloud WebコンソールStorage > Block Storageサービスページでもブロックストレージの接続情報を確認できます。
ボリューム拡張
PersistentVolumeClaim (PVC)オブジェクトを編集して既存ボリュームのサイズを調整できます。PVCオブジェクトのspec.resources.requests.storage項目を修正することでボリュームサイズを変更できます。ボリューム縮小はサポートされません。ボリューム拡張機能を使用するにはStorageClassのallowVolumeExpansionプロパティがTrueである必要があります。
v1.19.13以前のバージョンのボリューム拡張
v1.19.13以前のバージョンのストレージプロバイダーkubernetes.io/cinderは使用中のボリュームの拡張機能を提供しません。使用中のボリュームの拡張機能を使用するにはv1.20.12以降のバージョンのcinder.csi.openstack.orgストレージプロバイダーを使用する必要があります。クラスタアップグレード機能を利用してv1.20.12以降のバージョンにアップグレードしてcinder.csi.openstack.orgストレージプロバイダーを使用できます。
v1.19.13以前のバージョンのkubernetes.io/cinderストレージプロバイダーの代わりにv1.20.12以降のバージョンのcinder.csi.openstack.orgストレージプロバイダーを使用するためにPVCのアノテーションを以下のように修正する必要があります。
- pv.kubernetes.io/bind-completed: "yes" > 削除
- pv.kubernetes.io/bound-by-controller: "yes" > 削除
- volume.beta.kubernetes.io/storage-provisioner: kubernetes.io/cinder > volume.beta.kubernetes.io/storage-provisioner:cinder.csi.openstack.org
- volume.kubernetes.io/storage-resizer: kubernetes.io/cinder > volume.kubernetes.io/storage-resizer: cinder.csi.openstack.org
- pv.kubernetes.io/provisioned-by:cinder.csi.openstack.org > 追加
以下は修正されたPVCの例です。
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
annotations:
pv.kubernetes.io/provisioned-by: cinder.csi.openstack.org
volume.beta.kubernetes.io/storage-provisioner: cinder.csi.openstack.org
volume.kubernetes.io/storage-resizer: cinder.csi.openstack.org
creationTimestamp: "2022-07-18T06:13:01Z"
finalizers:
- kubernetes.io/pvc-protection
labels:
app: nginx
name: www-web-0
namespace: default
spec:
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 310Gi
storageClassName: sc-ssd
volumeMode: Filesystem
volumeName: pvc-0da7cd55-bf29-4597-ab84-2f3d46391e5b
status:
accessModes:
- ReadWriteOnce
capacity:
storage: 300Gi
phase: Bound
v1.20.12以降のバージョンのボリューム拡張
v1.20.12以降のバージョンのストレージプロバイダーcinder.csi.openstack.orgは基本的に使用中のボリュームの拡張機能をサポートします。PVCオブジェクトのspec.resources.requests.storage項目の値を修正してボリュームサイズを変更できます。
NHN Cloudサービス連動
NHN Cloud Container Registry(NCR)サービス連動
NHN Cloud Container Registryに保存したイメージを使うことができます。レジストリに保存したイメージを使うためには、ユーザーレジストリにログインするためのシークレット(secret)を作成する必要があります。
NHN Cloud (Old) Container Registryを使用するには次のようにシークレットを作成する必要があります。
$ kubectl create secret docker-registry registry-credential --docker-server={ユーザーレジストリアドレス} --docker-username={NHN Cloudアカウントemailアドレス} --docker-password={サービスAppkeyまたは統合Appkey}
secret/registry-credential created
$ kubectl get secrets
NAME TYPE DATA AGE
registry-credential kubernetes.io/dockerconfigjson 1 30m
NHN Cloud Container Registryを使用するには次のようにシークレットを作成する必要があります。
$ kubectl create secret docker-registry registry-credential --docker-server={ユーザーレジストリアドレス} --docker-username={User Access Key ID} --docker-password={Secret Access Key}
secret/registry-credential created
$ kubectl get secrets
NAME TYPE DATA AGE
registry-credential kubernetes.io/dockerconfigjson 1 30m
デプロイメントマニフェストファイルにシークレット情報を追加し、イメージ名を変更すると、ユーザーレジストリに保存されたイメージを利用してPodを作成できます。
# nginx.yaml
...
spec:
...
template:
...
spec:
containers:
- name: nginx
image: {ユーザーレジストリアドレス}/nginx:1.14.2
...
imagePullSecrets:
- name: registry-credential
[参考] NHN Cloud Container Registryの使い方はNHN Cloud Container Registry(NCR)ユーザーガイド文書を参照してください。
NHN Cloud NASサービス連動
NHN Cloudで提供するNASストレージをPVとして活用できます。NASサービスを使用するにはv1.20以降のバージョンのクラスタを使用する必要があります。NHN Cloud NASの詳細についてはNASコンソール使用ガイドを参照してください。
[参考] NHN Cloud NASサービスは現在(2024年02月基準)、一部リージョンでのみ提供されています。NHN Cloud NASサービスのサポートリージョンの詳細についてはNASサービス概要を参照してください。
すべてのワーカーノードでrpcbindサービスを実行
NASストレージを使用するにはすべてのワーカーノードでrpcbindサービスを実行する必要があります。すべてのワーカーノードに接続した後、下記のコマンドでrpcbindサービスを実行します。
rpcbindサービス実行コマンドはイメージの種類に関係なく同じです。
$ systemctl start rpcbind
強化されたセキュリティルールを使用しているクラスタの場合、セキュリティルールを追加する必要があります。
| 方向 | IPプロトコル | ポート範囲 | Ether | 遠隔 | 説明 |
|---|---|---|---|---|---|
| egress | TCP | 2049 | IPv4 | NAS IPアドレス | rpcのNFSポート、方向: csi-nfs-node(worker node) -> NAS |
| egress | TCP | 111 | IPv4 | NAS IPアドレス | rpcのportmapperポート、方向: csi-nfs-node(worker node) -> NAS |
| egress | TCP | 635 | IPv4 | NAS IPアドレス | rpcのmountdポート、方向: csi-nfs-node(worker node) -> NAS |
csi-driver-nfsのインストール
NHN Cloud NASサービスを使用するにはクラスタにcsi-driver-nfsコンポーネントを配布する必要があります。
csi-driver-nfsはNFSストレージに新たなサブディレクトリを作成する方式で動作するNFSストレージプロビジョニングをサポートするドライバーです。 csi-driver-nfsはストレージクラスにNFSストレージ情報を提供する方式で動作してユーザーが管理しなければならない対象を減らします。
csi-driver-nfsを使用して複数のPVを構成する場合、csi-driver-nfsがNFSストレージ情報をStorageClassに登録してNFS-Provisoner podを構成する必要がありません。
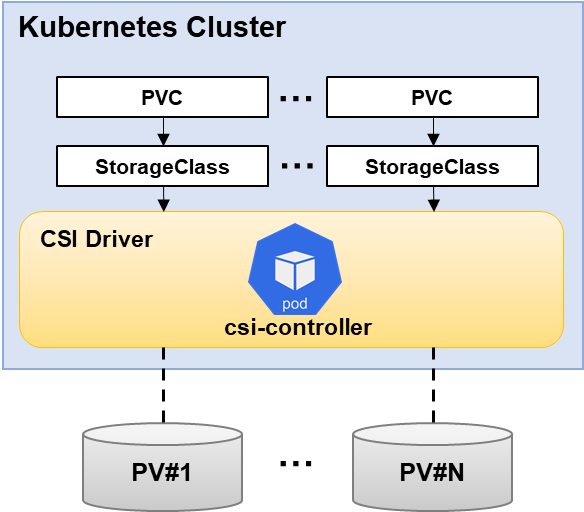
[参考] csi-driver-nfsインストールスクリプトの内部実行プロセスでkubectl applyコマンドが実行されます。したがって
kubectlコマンドが正常に動作する状態でインストールを進める必要があります。 csi-driver-nfsインストール手順はLinux環境を基準に作成されました。
1. クラスタ設定ファイルの絶対パスを環境変数に保存します。
$ export KUBECONFIG={クラスタ設定ファイルの絶対パス}
2. ORASコマンドラインツールを使用してcsi-driver-nfsインストールパッケージをダウンロードします。
ORAS(OCI Registry As Storage)はOCIレジストリからOCIアーティファクトをpushおよびpullする方法を提供するツールです。 ORAS installationを参考してORASコマンドラインツールをインストールします。 ORASコマンドラインツールの詳しい使用方法はORAS docsを参照してください。
| リージョン | インターネット接続 | ダウンロードコマンド |
|---|---|---|
| 韓国(パンギョ)リージョン | O | oras pull dfe965c3-kr1-registry.container.nhncloud.com/container_service/oci/nfs-deploy-tool:v1 |
| X | oras pull private-dfe965c3-kr1-registry.container.nhncloud.com/container_service/oci/nfs-deploy-tool:v1 | |
| 韓国(ピョンチョン)リージョン | O | oras pull 6e7f43c6-kr2-registry.container.cloud.toast.com/container_service/oci/nfs-deploy-tool:v1 |
| X | oras pull private-6e7f43c6-kr2-registry.container.cloud.toast.com/container_service/oci/nfs-deploy-tool:v1 |
3. インストールパッケージを解凍した後、install-driver.sh {mode}コマンドを使用してcsi-driver-nfsコンポーネントをインストールします。
install-driver.shコマンド実行時、インターネット接続が可能なクラスタはpublic、そうでないクラスタはprivateを入力する必要があります。
[参考] csi-driver-nfsコンテナイメージはNHN Cloud NCRで管理されています。クローズドネットワーク環境で構成されたクラスタはインターネットに接続されていないため、イメージを正常に受け取るためにはPrivate URIを使用するための環境設定が必要です。Private URIの使い方については、NHN Cloud Container Registry(NCR)ユーザーガイドを参照してください。
以下はインターネットネットワーク環境に構成されたクラスタにインストールパッケージを利用してcsi-driver-nfsをインストールする例です。
$ tar -xvf nfs-deploy-tool.tar
$ ./install-driver.sh public
Installing NFS CSI driver, mode: public ...
serviceaccount/csi-nfs-controller-sa created
serviceaccount/csi-nfs-node-sa created
clusterrole.rbac.authorization.k8s.io/nfs-external-provisioner-role created
clusterrolebinding.rbac.authorization.k8s.io/nfs-csi-provisioner-binding created
csidriver.storage.k8s.io/nfs.csi.k8s.io created
deployment.apps/csi-nfs-controller created
daemonset.apps/csi-nfs-node created
NFS CSI driver installed successfully.
4. コンポーネントが正常にインストールされていることを確認します。
$ kubectl get pods -n kube-system
NAMESPACE NAME READY STATUS RESTARTS AGE
kube-system csi-nfs-controller-844d5989dc-scphc 3/3 Running 0 53s
kube-system csi-nfs-node-hmps6 3/3 Running 0 52s
$ kubectl get clusterrolebinding
NAME ROLE AGE
clusterrolebinding.rbac.authorization.k8s.io/nfs-csi-provisioner-binding ClusterRole/nfs-external-provisioner-role 52s
$ kubectl get clusterrole
NAME CREATED AT
clusterrole.rbac.authorization.k8s.io/nfs-external-provisioner-role 2022-08-09T06:21:20Z
$ kubectl get csidriver
NAME ATTACHREQUIRED PODINFOONMOUNT MODES AGE
csidriver.storage.k8s.io/nfs.csi.k8s.io false false Persistent,Ephemeral 47s
$ kubectl get deployment -n kube-system
NAMESPACE NAME READY UP-TO-DATE AVAILABLE AGE
kube-system coredns 2/2 2 2 22d
kube-system csi-nfs-controller 1/1 1 1 4m32s
$ kubectl get daemonset -n kube-system
NAMESPACE NAME DESIRED CURRENT READY UP-TO-DATE AVAILABLE NODE SELECTOR AGE
kube-system csi-nfs-node 1 1 1 1 1 kubernetes.io/os=linux 4m23s
プロビジョニング時に既存のNHN Cloud NASストレージを利用する方法
PVマニフェストの作成時にNAS情報を入力するか、StorageClassマニフェストにNAS情報を入力して、既存のNASストレージをPVとして使用できます。
方法1. PVマニフェスト作成時にNASストレージ情報を定義
PVマニフェスト作成時にNHN Cloud NASストレージ情報を定義します。設定位置は.specサブのcsiです。
- driver:nfs.csi.k8s.ioを入力します。
- readOnly:falseを入力します。
- volumeHandle:クラスタ内で重複していない固有のidを入力します。
- volumeAttributes:NASストレージの接続情報を入力します。
- server:NASストレージの接続情報のip部分の値を入力します。
- share:NASストレージの接続情報のボリューム名部分の値を入力します。
以下はマニフェストの例です。
# pv.yaml
apiVersion: v1
kind: PersistentVolume
metadata:
name: pv-onas
spec:
capacity:
storage: 300Gi
accessModes:
- ReadWriteMany
persistentVolumeReclaimPolicy: Retain
csi:
driver: nfs.csi.k8s.io
readOnly: false
volumeHandle: unique-volumeid
volumeAttributes:
server: 192.168.0.98
share: /onas_300gb
PVを作成し、確認します。
$ kubectl apply -f pv.yaml
persistentvolume/pv-onas created
$ kubectl get pv -o wide
NAME CAPACITY ACCESS MODES RECLAIM POLICY STATUS CLAIM STORAGECLASS REASON AGE VOLUMEMODE
pv-onas 300Gi RWX Retain Available 101s Filesystem
作成したPVを使用するためのPVCマニフェストを作成します。spec.volumeNameにはPVの名前を指定する必要があります。他の項目はPVマニフェストの内容と同じに設定します。
# pvc.yaml
kind: PersistentVolumeClaim
apiVersion: v1
metadata:
name: pvc-onas
spec:
accessModes:
- ReadWriteMany
resources:
requests:
storage: 300Gi
volumeName: pv-onas
PVCを作成して確認します。
$ kubectl apply -f pvc.yaml
persistentvolumeclaim/pvc-onas created
$ kubectl get pvc -o wide
NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS AGE VOLUMEMODE
pvc-onas Bound pv-onas 300Gi RWX 2m8s Filesystem
PVCを作成した後、PVの状態を照会するとCLAIM項目にPVC名が指定され、STATUS項目がBoundに変更されていることを確認できます。
$ kubectl get pv -o wide
NAME CAPACITY ACCESS MODES RECLAIM POLICY STATUS CLAIM STORAGECLASS REASON AGE VOLUMEMODE
pv-onas 300Gi RWX Retain Bound default/pvc-onas 3m20s Filesystem
方法2.StorageClassマニフェスト作成時にNAS情報を定義
StorageClassマニフェスト作成時、ストレージプロバイダー情報およびNHN Cloud NASストレージ情報を定義します。
- provisioner:nfs.csi.k8s.ioを入力します。
- parameters:NASストレージの接続情報を入力します。
- server:NASストレージの接続情報のip部分の値を入力します。
- share:NASストレージの接続情報のボリューム名部分の値を入力します。
以下はマニフェストの例です。
# storageclass.yaml
apiVersion: storage.k8s.io/v1
kind: StorageClass
metadata:
name: onas-sc
provisioner: nfs.csi.k8s.io
parameters:
server: 192.168.0.81
share: /onas_300gb
reclaimPolicy: Retain
volumeBindingMode: Immediate
StorageClassを作成し、確認します。
$ kubectl apply -f storageclass.yaml
storageclass.storage.k8s.io/onas-sc created
$ kubectl get sc
NAME PROVISIONER RECLAIMPOLICY VOLUMEBINDINGMODE ALLOWVOLUMEEXPANSION AGE
onas-sc nfs.csi.k8s.io Retain Immediate false 3s
PVを別途作成する必要がないので、PVCマニフェストだけを作成します。PVCマニフェストにはspec.volumeNameを設定しません。
# pvc.yaml
kind: PersistentVolumeClaim
apiVersion: v1
metadata:
name: pvc-onas-dynamic
spec:
accessModes:
- ReadWriteMany
resources:
requests:
storage: 300Gi
storageClassName: onas-sc
ボリュームバインディングモードを設定しない場合、またはImmediateに設定してPVCを作成した場合はPVが自動的に作成されます。
$ kubectl apply -f pvc.yaml
persistentvolumeclaim/pvc-onas created
$ kubectl get sc,pv,pvc
NAME PROVISIONER RECLAIMPOLICY VOLUMEBINDINGMODE ALLOWVOLUMEEXPANSION AGE
storageclass.storage.k8s.io/onas-sc nfs.csi.k8s.io Retain Immediate false 25s
NAME CAPACITY ACCESS MODES RECLAIM POLICY STATUS CLAIM STORAGECLASS REASON AGE
persistentvolume/pvc-71392e58-5d8e-43b2-9798-5b59de34b203 300Gi RWX Retain Bound default/pvc-onas onas-sc 3s
NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS AGE
persistentvolumeclaim/pvc-onas Bound pvc-71392e58-5d8e-43b2-9798-5b59de34b203 300Gi RWX onas-sc 4s
PodにPVCをマウントするにはPodマニフェストにマウント情報を定義する必要があります。 spec.volumes.persistenVolumeClaim.claimNameに使用するPVC名を入力します。そしてspec.containers.volumeMounts.mountPathにマウントするパスを入力します。
以下は作成したPVCをPodの/tmp/nfsにマウントするマニフェスト例です。
# deployment.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
labels:
app: nginx
name: nginx
namespace: default
spec:
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- image: nginx
imagePullPolicy: Always
name: nginx
volumeMounts:
- name: onas-dynamic
mountPath: "/tmp/nfs"
volumes:
- name: onas-dynamic
persistentVolumeClaim:
claimName: pvc-onas-dynamic
Podを作成し、NASストレージがマウントされていることを確認します。
$ kubectl apply -f deployment.yaml
deployment.apps/nginx created
$ kubectl get pods
NAME READY STATUS RESTARTS AGE
nginx-5fbc846574-q28cf 1/1 Running 0 26s
$ kubectl exec -it nginx-5fbc846574-q28cf -- df -h
Filesystem Size Used Avail Use% Mounted on
...
192.168.0.45:/onas_300gb/pvc-71392e58-5d8e-43b2-9798-5b59de34b203 270G 256K 270G 1% /tmp/nfs
...
プロビジョニング時に新しいNHN Cloud NASストレージを作成する方法
StorageClassおよびPVCマニフェスト作成時にNAS情報を入力すると、自動的に作成されたNASストレージをPVとして使用できます。
StorageClassマニフェストにストレージプロバイダー情報と作成するNASストレージのスナップショットポリシー、アクセス制御リスト(ACL)、サブネット情報を定義します。 * provisioner:nfs.csi.k8s.ioを入力します。 * parameters:入力項目は下表を参照してください。パラメータ値に複数の値を定義する場合、,を使用して値を区切ります。
| 項目 | 説明 | 例 | 複数値 | 必須 | デフォルト値 |
|---|---|---|---|---|---|
| maxscheduledcount | 保存可能な最大スナップショット数です。最大保存数に達すると、自動的に作成されたスナップショットのうち、最初に作成されたスナップショットが削除されます。1~20の数字のみ入力可能です。 | "7" | X | X | |
| reservepercent | 最大保存可能なスナップショット保存容量です。スナップショット容量の合計が設定したサイズを超える場合、すべてのスナップショットのうち最初に作成されたスナップショットが削除されます。0~80の間の数字のみ入力可能です。 | "80" | X | X | |
| scheduletime | スナップショットが作成される時刻です。 | "09:00" | X | X | |
| scheduletimeoffset | スナップショット作成時刻に対するオフセットです。 UTC基準で、KSTで使用する時は+09:00値を指定します。 | "+09:00" | X | X | |
| scheduleweekdays | スナップショット作成周期です。日曜日から土曜日までそれぞれ0~6の数字で表現されます。 | "6" | O | X | |
| subnet | ストレージにアクセスするサブネットです。選択されたVPCのサブネットのみ選択できます。 | "59526f1c-c089-4517-86fd-2d3dac369210" | X | O | |
| acl | 読み取り、書き込み権限を許可するIPまたはIP帯域のリストです。 | "0.0.0.0/0" | O | X | 0.0.0.0/0 |
| onDelete | PVC削除時にNASボリュームを削除するかどうかです。 | "delete" / "retain" | X | X | delete |
[参考] スナップショットパラメータを使用する場合、関連するすべてのパラメータ値を定義する必要があります。スナップショット関連パラメータは次のとおりです。 + maxscheduledcount + reservepercent + scheduletime + scheduletimeoffset + scheduleweekdays
[注意]マルチサブネット環境での制約事項
NASストレージはストレージクラスに定義されたサブネットに接続されます。 PodがNASストレージと連動するためには、すべてのワーカーノードグループがこのサブネットに接続されている必要があります。
以下はマニフェストの例です。
# storage_class.yaml
apiVersion: storage.k8s.io/v1
kind: StorageClass
metadata:
name: sc-nfs
provisioner: nfs.csi.k8s.io
reclaimPolicy: Delete
volumeBindingMode: Immediate
parameters:
maxscheduledcount : "7"
reservepercent : "80"
scheduletime : "09:00"
scheduletimeoffset : "+09:00"
scheduleweekdays : "6"
subnet : "59526f1c-c089-4517-86fd-2d3dac369210"
acl : ""
PVCマニフェストのAnnotationに作成するNASストレージの名前、説明、サイズを定義します。入力項目は下表を参照してください。
| 項目 | 説明 | 例 | 必須 |
|---|---|---|---|
| nfs-volume-name | 作成されるストレージの名前です。ストレージ名を通じてNFSアクセスパスを作成します。名前は100文字以内の英字と数字、一部記号('-', '_')のみ入力できます。 | "nas_sample_volume_300gb" | O |
| nfs-volume-description | 作成するNASストレージの説明です。 | "nas sample volume" | X |
| nfs-volume-sizegb | 作成するNASストレージのサイズです。GB単位で設定されます。 最小300から最大10,000まで入力できます。 | "300" | O |
以下はマニフェストの例です。
# pvc.yaml
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: pvc-nfs
annotations:
nfs-volume-name: "nas_sample_volume_300gb"
nfs-volume-description: "nas sample volume"
nfs-volume-sizegb: "300"
spec:
accessModes:
- ReadWriteMany
resources:
requests:
storage: 50Gi
storageClassName: sc-nfs
StorageClassおよびPVCを作成し、確認します。
$ kubectl apply -f storage_class.yaml
storageclass.storage.k8s.io/sc-nfs created
$ kubectl get sc
NAME PROVISIONER RECLAIMPOLICY VOLUMEBINDINGMODE ALLOWVOLUMEEXPANSION AGE
sc-nfs nfs.csi.k8s.io Delete Immediate false 50s
PVを別途作成する必要がないので、PVCマニフェストだけを作成します。PVCマニフェストにはspec.volumeNameを設定しません。 ボリュームバインディングモードを設定しないか、Immediateに設定してPVCを作成すると、PVが自動的に作成されます。NASストレージが作成された後、Boundされるまで約1分程度かかります。 NHN CloudコンソールStorage > NASサービスページでも作成されたNASストレージの情報を確認できます。
$ kubectl apply -f pvc.yaml
persistentvolumeclaim/pvc-nfs created
$ kubectl get pv,pvc
NAME CAPACITY ACCESS MODES RECLAIM POLICY STATUS CLAIM STORAGECLASS REASON AGE
persistentvolume/pvc-a8ea2054-0849-4fe8-8207-ee0e43b8a103 50Gi RWX Delete Bound default/pvc-nfs sc-nfs 2s
NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS AGE
persistentvolumeclaim/pvc-nfs Bound pvc-a8ea2054-0849-4fe8-8207-ee0e43b8a103 50Gi RWX sc-nfs 75s
PVCをPodにマウントするには、Podマニフェストにマウント情報を定義する必要があります。spec.volumes.persistenVolumeClaim.claimNameに使うPVCの名前を入力します。そして、spec.containers.volumeMounts.mountPathにマウントするパスを入力します。
以下は作成したPVCをパッドの/tmp/nfsにマウントするマニフェストの例です。
# deployment.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
labels:
app: nginx
name: nginx
namespace: default
spec:
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- image: nginx
imagePullPolicy: Always
name: nginx
volumeMounts:
- name: nas
mountPath: "/tmp/nfs"
volumes:
- name: nas
persistentVolumeClaim:
claimName: pvc-nfs
Podを作成し、NASストレージがマウントされていることを確認します。
$ kubectl apply -f deployment.yaml
deployment.apps/nginx created
$ kubectl get pods
NAME READY STATUS RESTARTS AGE
nginx-9f448b9f7-xw92w 1/1 Running 0 12s
$ kubectl exec -it nginx-9f448b9f7-xw92w -- df -h
Filesystem Size Used Avail Use% Mounted on
overlay 20G 16G 4.2G 80% /
tmpfs 64M 0 64M 0% /dev
tmpfs 1.9G 0 1.9G 0% /sys/fs/cgroup
192.168.0.57:nas_sample_volume_100gb/pvc-a8ea2054-0849-4fe8-8207-ee0e43b8a103 20G 256K 20G 1% /tmp/nfs
...
[参考] csi-driver-nfsはプロビジョニング時にNFSストレージ内部にsubdirectoryを作成する方式で動作します。 podにPVをマウントするプロセスでsubdirectoryのみマウントされるのではなく、nfsストレージ全体がマウントされるため、アプリケーションがプロビジョニングされたサイズだけボリュームを使用するように強制できません。
NHN Cloud暗号化ブロックストレージ連動
NHN Cloudが提供する暗号化ブロックストレージをPVとして活用できます。NHN Cloudの暗号化ブロックストレージの詳細については、暗号化ブロックストレージを参照してください。
[参考] 暗号化ブロックストレージサービス連動機能はv1.24.3以上のバージョンのクラスタで使用可能です。 2023年11月28日以降に新規作成されたクラスタは、基本的に暗号化ブロックストレージ連動機能が内蔵されています。 2023年11月28日以前に生成されたクラスタは、v1.24.3以上のバージョンにアップグレードするか、csi-cinder-cinder-controllerpluginステートフルセットとcsi-cinder-nodepluginデーモンセットのcinder-csi-pluginイメージを最新バージョンに置き換えることで暗号化ブロックストレージ連動機能を使用できます。
[注意] v1.24.3以前のバージョンのクラスタをアップグレードせずにcinder-csi-pluginコンテナイメージだけを交換して使用する場合、誤動作を引き起こす可能性があります。
暗号化ブロックストレージ連動のためのcinder-csi-pluginイメージアップデート
下記のコマンドを実行して、現在のクラスタに配布されたcinder-csi-pluginイメージのタグを確認できます。
$ kubectl -n kube-system get statefulset csi-cinder-controllerplugin -o=jsonpath="{$.spec.template.spec.containers[?(@.name=='cinder-csi-plugin')].image}"
> registry.k8s.io/provider-os/cinder-csi-plugin:v1.27.101
cinder-csi-pluginイメージのタグがv1.27.101以上の場合、何もしなくても暗号化ブロックストレージを連動できます。 cinder-csi-pluginイメージのタグがv1.27.101未満の場合、下記の手順でcinder-csi-pluginのイメージをアップデートした後、暗号化ブロックストレージを連動できます。
| リージョン | インターネット接続 | cinder-csi-pluginイメージ |
|---|---|---|
| 韓国(パンギョ)リージョン | O | dfe965c3-kr1-registry.container.nhncloud.com/container_service/cinder-csi-plugin:v1.27.101 |
| X | private-dfe965c3-kr1-registry.container.nhncloud.com/container_service/cinder-csi-plugin:v1.27.101 | |
| 韓国(ピョンチョン)リージョン | O | 6e7f43c6-kr2-registry.container.cloud.toast.com/container_service/cinder-csi-plugin:v1.27.101 |
| X | private-6e7f43c6-kr2-registry.container.cloud.toast.com/container_service/cinder-csi-plugin:v1.27.101 |
1. container_imageに正しいcinder-csi-pluginイメージ値を入力します。
$ container_image={cinder-csi-pluginイメージ}
2. コンテナイメージを置き換えます。
$ kubectl -n kube-system patch statefulset csi-cinder-controllerplugin -p "{\"spec\": {\"template\": {\"spec\": {\"containers\": [{\"name\": \"cinder-csi-plugin\", \"image\": \"${container_image}\"}]}}}}"
$ kubectl -n kube-system patch daemonset csi-cinder-nodeplugin -p "{\"spec\": {\"template\": {\"spec\": {\"containers\": [{\"name\": \"cinder-csi-plugin\", \"image\": \"${container_image}\"}]}}}}"
[参考] cinder-csi-pluginコンテナイメージは NHN Cloud NCR で管理されています。クローズドネットワーク環境で構成されたクラスタはインターネットに接続されていないため、イメージを正常に受け取るためにはPrivate URIを使うための環境設定が必要です。Private URIの使い方についての詳細はNHN Cloud Container Registry(NCR) ユーザーガイドを参照してください。
静的プロビジョニング
PVを生成するには、暗号ブロックストレージのIDが必要です。Storage > Block Storageサービスページのブロックストレージ一覧から使用するブロックストレージを選択します。下部の情報タブのブロックストレージ名項目でIDを確認できます。
PVマニフェスト作成時に暗号化ブロックストレージの情報を入力します。設定場所は.spec.csiの下にあります。
* driver: cinder.csi.openstack.orgを入力します。
* fsType: ext3を入力します。
* volumeHandle:作成した暗号化ブロックストレージのIDを入力します。
以下はマニフェストの例です。
# pv-static.yaml
apiVersion: v1
kind: PersistentVolume
metadata:
annotations:
pv.kubernetes.io/provisioned-by: cinder.csi.openstack.org
name: pv-static-encrypted-hdd
spec:
capacity:
storage: 10Gi
volumeMode: Filesystem
accessModes:
- ReadWriteOnce
persistentVolumeReclaimPolicy: Delete
csi:
driver: cinder.csi.openstack.org
fsType: ext3
volumeHandle: 9f606b78-256b-4f74-8988-1331cd6d398b
PVCマニフェスト作成およびPodのマウントのプロセスは、一般的なブロックストレージの静的プロビジョニングと同じです。詳細は静的プロビジョニングを参照してください。
動的プロビジョニング
ストレージクラスマニフェスト作成時に暗号化ブロックストレージの作成に必要な情報を入力して、自動的に作成された暗号化ブロックストレージをPVとして使用することができます。
ストレージクラスマニフェストに暗号化ブロックストレージの作成に必要な情報を入力します。設定位置は.parametersの下にあります。 * ストレージの種類(type):ストレージの種類を入力します。 * Encrypted HDD:ストレージの種類が暗号化されたHDDに設定されます。 * Encrypted SSD:ストレージの種類が暗号化されたSSDに設定されます。 * 暗号化キーID(volume_key_id): Secure Key Manager(SKM)サービスで作成した対称鍵のIDを入力します。 * 暗号化アプリケーションキー(volume_appkey): Secure Key Manager(SKM)サービスで確認したAppkeyを入力します。
以下はマニフェストの例です。
# storage_class.yaml
apiVersion: storage.k8s.io/v1
kind: StorageClass
metadata:
name: csi-storageclass-encrypted-hdd
provisioner: cinder.csi.openstack.org
volumeBindingMode: Immediate
allowVolumeExpansion: true
parameters:
type: Encrypted HDD
volume_key_id: "5530..."
volume_appkey: "uaUW..."
PVCマニフェストの作成およびPodにマウントするプロセスは一般的なブロックストレージの動的プロビジョニングと同じです。詳細は動的プロビジョニングを参照してください。
目次
- Container > NHN Kubernetes Service(NKS) > 使用ガイド
- クラスター
- Kubernetesバージョンサポートポリシー
- クラスター作成
- クラスター照会
- クラスター削除
- クラスタOWNER変更
- ノードグループ
- ノードグループ照会
- ノードグループ作成
- ノードグループ削除
- ノードグループにノード追加
- ノードグループからノード削除
- ノードの停止と起動
- GPUノードグループ使用
- オートスケーラー
- ユーザースクリプト(old)
- ユーザースクリプト
- インスタンスタイプの変更
- カスタムイメージをワーカーイメージとして活用
- クラスター管理
- kubectlインストール
- 設定
- 接続確認
- CSR(CertificateSigningRequest)
- 承認コントローラー(admission controller)プラグイン
- クラスタアップグレード
- クラスタCNIの変更
- クラスタAPIエンドポイントにIPアクセス制御を適用
- ワーカーノード管理
- コンテナ管理
- ネットワーク管理
- kubeletユーザー定義引数設定機能
- ユーザー定義containerdレジストリ設定機能
- LoadBalancerサービス
- WebサーバーPod作成
- LoadBalancerサービスの作成
- インターネットによるサービステスト
- ロードバランサー詳細オプション設定
- イングレスコントローラー
- NGINX Ingress Controllerのインストール
- URIベースのサービス分岐
- ホストベースのサービス分岐
- Kubernetesダッシュボード
- ダッシュボードサービス公開
- ダッシュボードアクセストークン
- パシステントボリューム
- PV/PVCのライフサイクル
- ストレージクラス(StorageClass)
- 静的プロビジョニング
- 動的プロビジョニング
- PodにPVCマウント
- 静的プロビジョニング
- 動的プロビジョニング
- PodにPVCマウント
- ボリューム拡張
- NHN Cloudサービス連動
- NHN Cloud Container Registry(NCR)サービス連動
- NHN Cloud NASサービス連動
- NHN Cloud暗号化ブロックストレージ連動