Database > EasyCache > コンソール使用ガイド
始める
- 最初にやるべきことは、レプリケーショングループを作成することです。
レプリケーショングループ
レプリケーショングループ作成
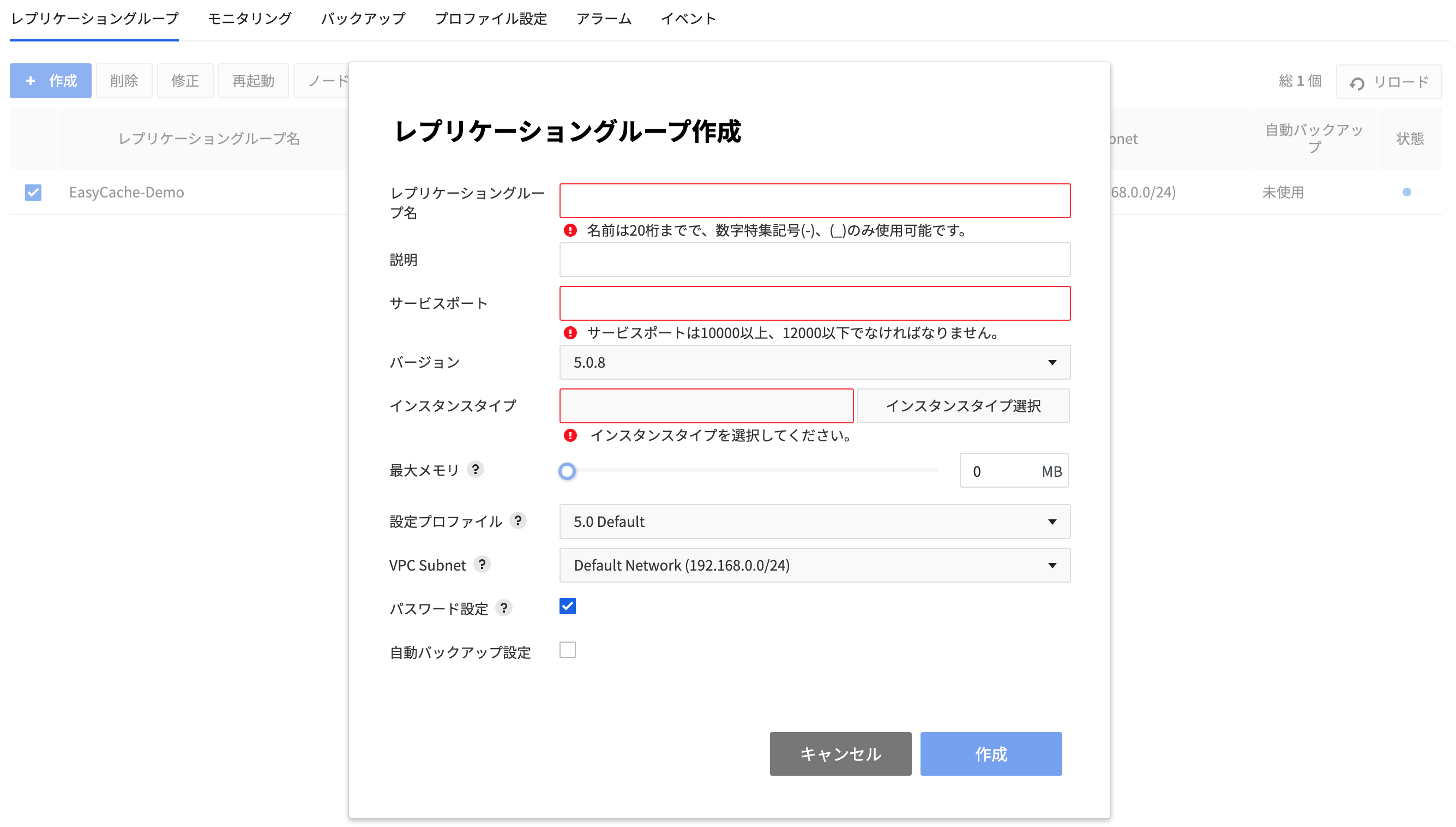
- Console > Database > EasyCacheの レプリケーショングループ タブで作成ボタンを押すと、レプリケーショングループ作成ウィンドウが表示されます。
-
設定ウィンドウに表示された必須項目を全て入力し、下部の作成ボタンを押してください。
- レプリケーショングループ名:レプリケーショングループの名前を入力します。
- 説明:レプリケーショングループの説明を入力します。
- サービスポート:Redisのポート番号を入力します。
- 10000~12000の間で設定できます。
- バージョン:作成するRedisのバージョンを選択します。
- インスタンスタイプ:レプリケーショングループの仕様を選択します。
- 最大メモリ:最大メモリを調整して、同期化やバックアップ実行時のメモリ不足を防止できます。
- Redisサーバーに使用する最大のメモリ容量を変更できます。
- 最大メモリ容量を柔軟に変更できるようにすることで、必要に応じて管理用メモリの容量も柔軟に確保できます。
- アベイラビリティゾーン:レプリケーショングループが作成される領域を選択します。
- 設定プロファイル:Redisの設定ファイルを選択します。
- Defaultプロファイルを提供します。
- 設定プロファイルを追加して選択できます。
- VPCサブネット:プライベートネットワーク通信を行いたいComputeおよびNetworkサービスのサブネットを選択します。選択しない場合はDefaultネットワークが設定されます。
- パスワード設定:パスワードを設定するかどうかを選択します。デフォルト値は「パスワード設定」です。
- 自動バックアップ設定:自動バックアップを行うかどうかを選択します。
- バックアップ保存期間:1日から最大30日まで保存できます。
- バックアップ開始時間:バックアップ開始時刻を指定します。30分単位で指定できます。
- バックアップウィンドウ:バックアップ開始時間からバックアップウィンドウの間の任意の時点で開始します。1時間~最大3時間まで指定できます。
- TLS証明書設定:Certificate Managerに保存された証明書のいずれかを選択して、TLS証明書で通信できます。複製グループ作成時にTLS証明書の使用有無を決定すると、その後使用有無を変更することはできません。
- TLSサービスポート: TLS証明書を使用した接続用ポートです。10000以上、12000以下の数字でサービスポートと異なる設定にする必要があります。
- TLSサービスポートのみ使用: TLSサービスポートのみを使用して接続するように設定できます。この機能を有効にすると、一般サービスポートを使用して接続できません。
- 証明書選択: Certificate Managerに保存されたTLS証明書のいずれかを選択できます。Certificate Manager商品のAppkeyを入力する必要があります。
- redisは公開鍵、秘密鍵、CA公開鍵をすべて必要とします。したがって、使用する証明書には、その鍵がすべて含まれている必要があり、その鍵を作成する方法は、Certificate Manager > トラブルシューティングガイドを参照してください。
-
作成をクリックします。
4.確認画面で入力した内容を確認し、作成をクリックします。 * 最後に作成ボタンを押します。 * レプリケーショングループが作成されると、Masterノードが作成されます。 * 作成されるまで数分かかります。
制約事項
- サービスに致命的な影響を与える可能性があるコマンドに対して使用が制限されます。
- 該当するコマンドは開発者ガイドをご参考ください。
レプリケーション(ノード追加)
- 可用性を高めるために、RedisがサポートするReplicaノードを作成できます。
- Replicaノードを作成するには、コピー元のレプリケーショングループを選択した後、ノード追加ボタンを押します。
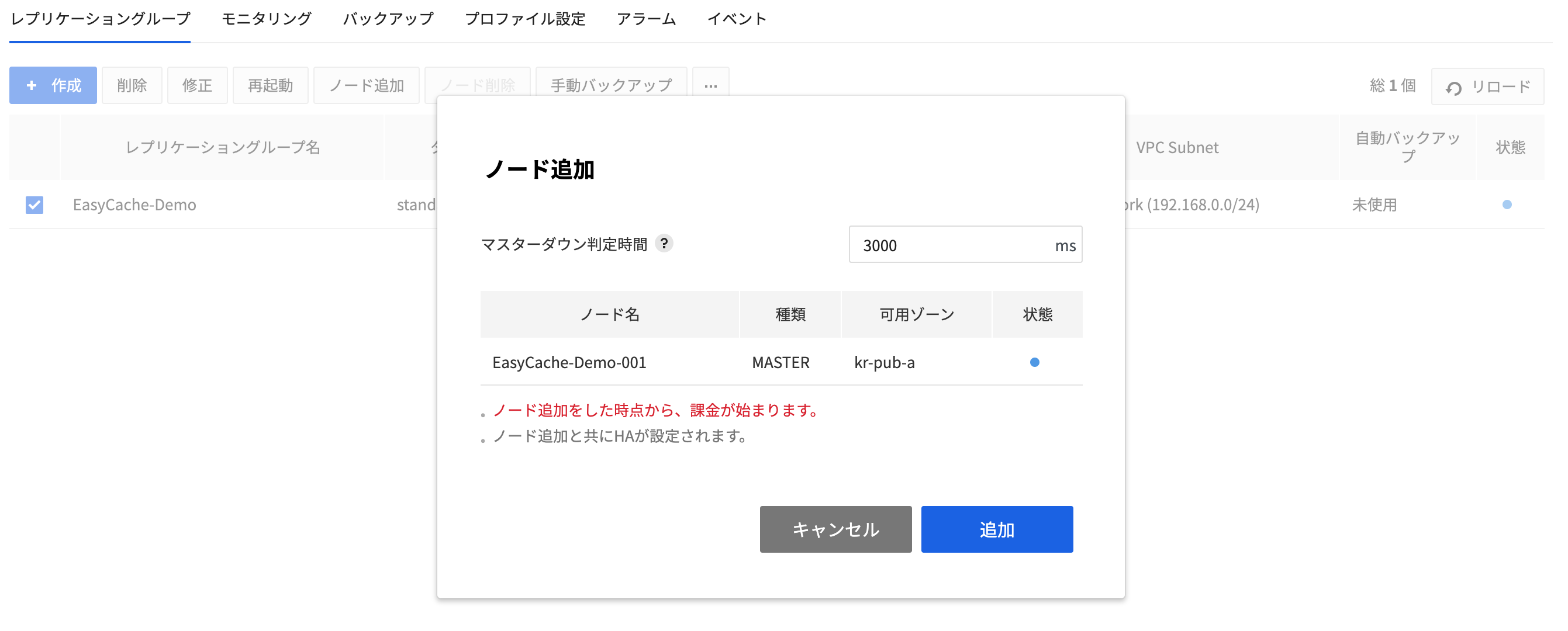
- Masterノードがダウンしているかを判断するために、ヘルスチェック応答待機時間を設定できます。デフォルトで値は3000msです。
-
Masterノードの情報を確認できます。
-
OKボタンを押すとReplicaノードが作成されます。
- 作成されたノードの情報は、レプリケーショングループ> [ノード情報]で確認できます。
- 作成時、自動的に複製関係が設定されます。
- Replicaノードは原本Masterノードと同じサーバー仕様です。
- コピー元のMasterノードのサイズに比例して、Replicaノードの作成時間が長くなる場合があります。
制約事項
- コピー元のMasterノードに最大2個までReplicaノードを作成できます。
- 正常な状態ではないReplicaノードが存在する場合、先に削除した後、新しいReplicaノードを追加できます。
- ReplicaノードのReplicaノードは作成できません。
高可用性(HA)
- standaloneのMasterノードにReplicaノードを追加すると、自動的に高可用性の機能が設定されます。
- Masterノードを監視して障害が発生した時、自動的にフェイルオーバーを行うことにより、downtimeを最小限にできます。
- フェイルオーバーとは、障害が発生したMasterノードを検知して、自動的にReplicaノードをMasterノードに昇格(failover)させる処理のことです。
- Master、Replicaノードの障害および状態に関するイベントを確認できます。
制約事項
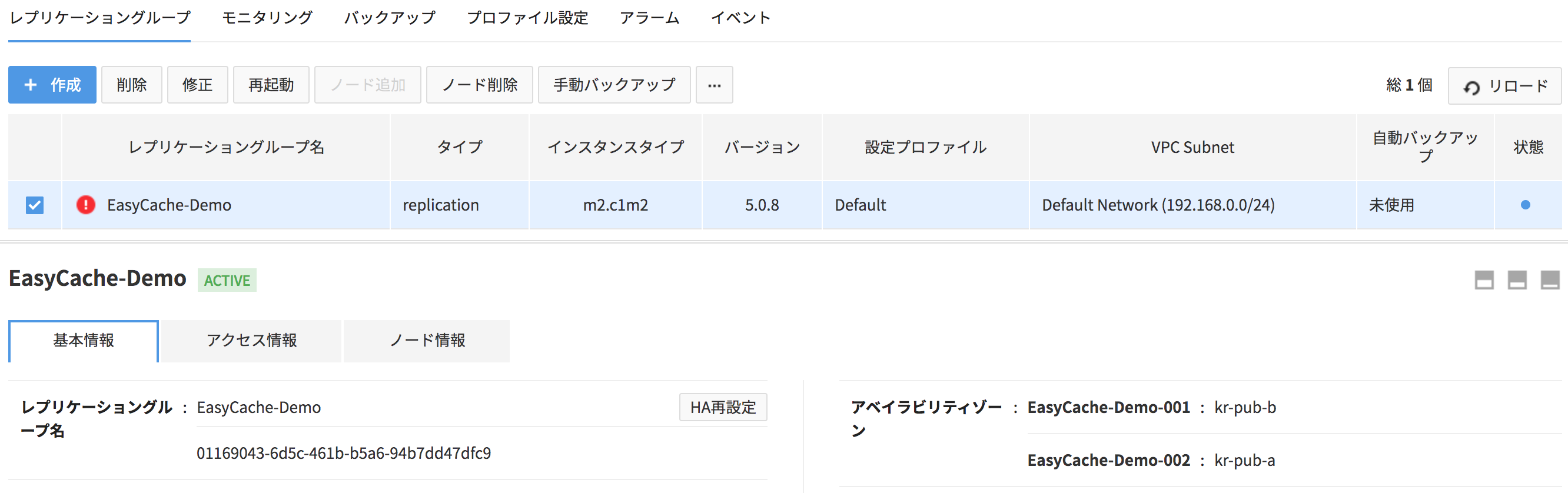
- Replicaノードを1つ追加する時、HA設定が失敗するとレプリケーショングループ> [基本情報]でHA再設定ボタンを押してHAを再設定できます。
-
Replicaノードを2つ追加する時、HA設定の更新に失敗した場合は、レプリケーショングループ > 基本情報でHA設定更新ボタンをクリックしてHA設定の更新をもう一度行うことができます。
-
障害が発生してフェイルオーバーを行った場合は、障害が発生した既存Masterノードは停止します。障害が発生したノードを削除すると、高可用性機能を使用しない一般standaloneのMasterノードに変更されます。
- またstandaloneになったMasterノードにReplicaノードを追加すると、高可用性機能を再度新たに指定して使用できます。
- 変更された新Masterノードは、既存Masterノードの接続に使用されるドメインを継承します。
- フェイルオーバーを実行した既存のMasterノードは「利用不可」状態になり、利用不可状態では新Masterノードにのみ高可用性機能が提供されません。
レプリケーショングループの修正
-
コピー元のレプリケーショングループを選択し、修正 ボタンを押します。
- レプリケーショングループ名:レプリケーショングループ名を変更できます。
- 説明:レプリケーショングループの説明を変更できます。
- 設定プロファイル:Redis設定を変更できます。
-
最大メモリ:使用する最大メモリ容量を変更できます。
-
自動バックアップ設定:自動バックアップを使用するかどうかを選択します。
- バックアップ保存期間:1日から最大30日まで保存可能です。
- バックアップ開始時間:バックアップ開始時刻を指定します。30分単位で指定可能です。
- バックアップウィンドウ:バックアップ開始時刻からバックアップウィンドウの間の任意の時点で開始します。1時間~最大3時間まで指定できます。
-
Replicaノードがある時、確認できる項目は下記のとおりです。
- マスターダウン判定時間:Masterノードがダウンしているかを判断するためにヘルスチェックレスポンス待機時間を設定できます。デフォルト値は3000msです。
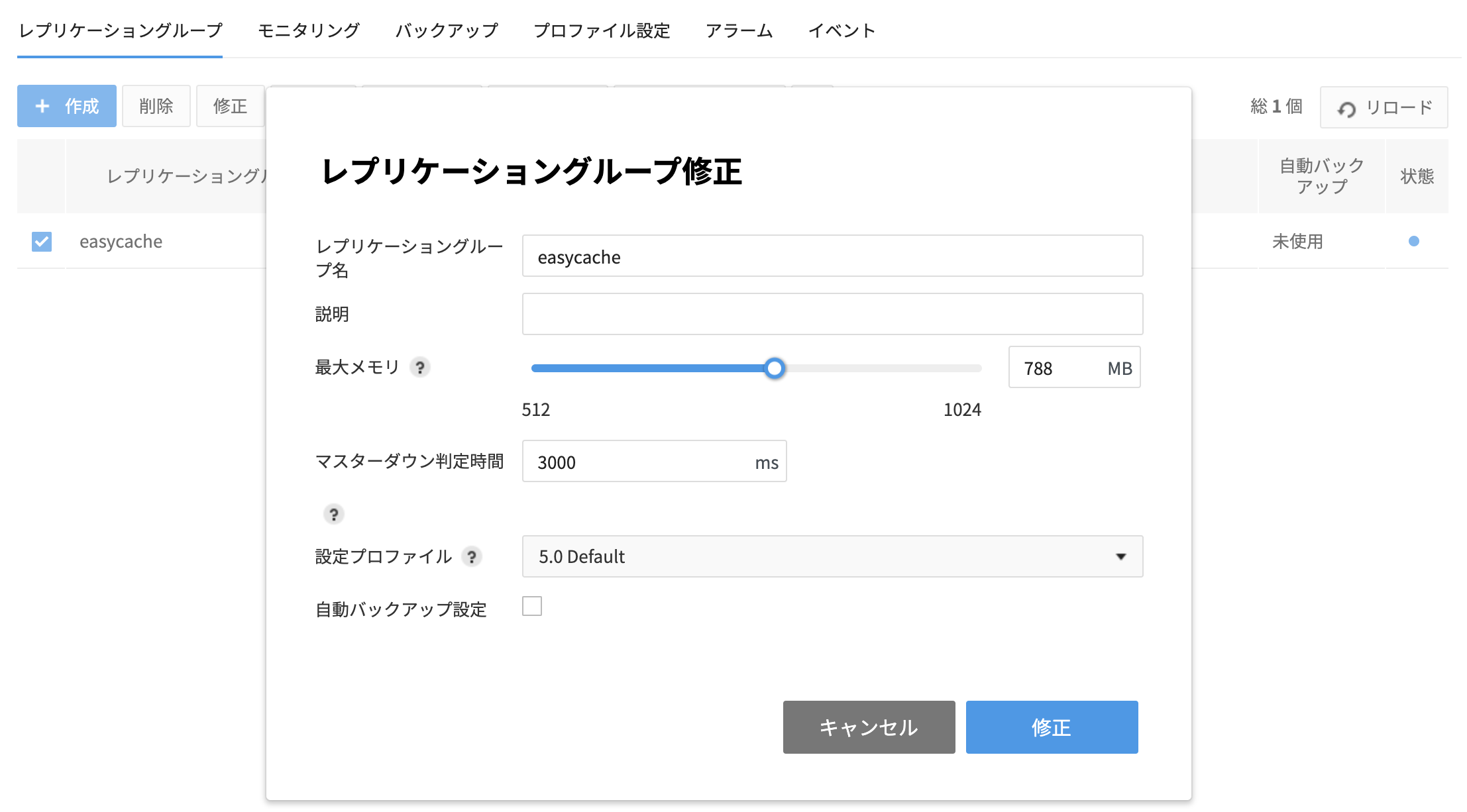
- 変更内容を確認し、変更 ボタンを押します。
- 一度設定したサービスポート、Redisバージョン、インスタンスタイプ、アベイラビリティゾーンは変更できません。
自動バックアップ
- 毎日1回、指定された時間に自動的にメモリデータ(RDBファイル)をバックアップします。
- 作成された自動バックアップはバックアップタブで管理できます。
- バックアップ対象になったレプリケーショングループが削除されると、バックアップファイルも削除されます。
- 指定されたバックアップ保存期間が過ぎると、バックアップファイルは自動的に削除されます。
- 自動バックアップは、バックアップ開始時刻からバックアップウィンドウ内の任意の時点でバックアップを開始します。
手動バックアップ作成
- レプリケーショングループのバックアップを、必要な時にすぐに作成できます。
- バックアップ対象になったレプリケーショングループを削除しても、手動バックアップファイルは削除されません。
- 作成された手動バックアップは、バックアップタブで管理できます。
- バックアップの実行中は、バックアップによる性能の低下が発生する場合があります。
- 定められたバックアップ保存期間が過ぎると、バックアップファイルは自動的に削除されます。
- バックアップ対象のレプリケーショングループが削除されると、基本情報にレプリケーショングループの詳細内容は表示されません。
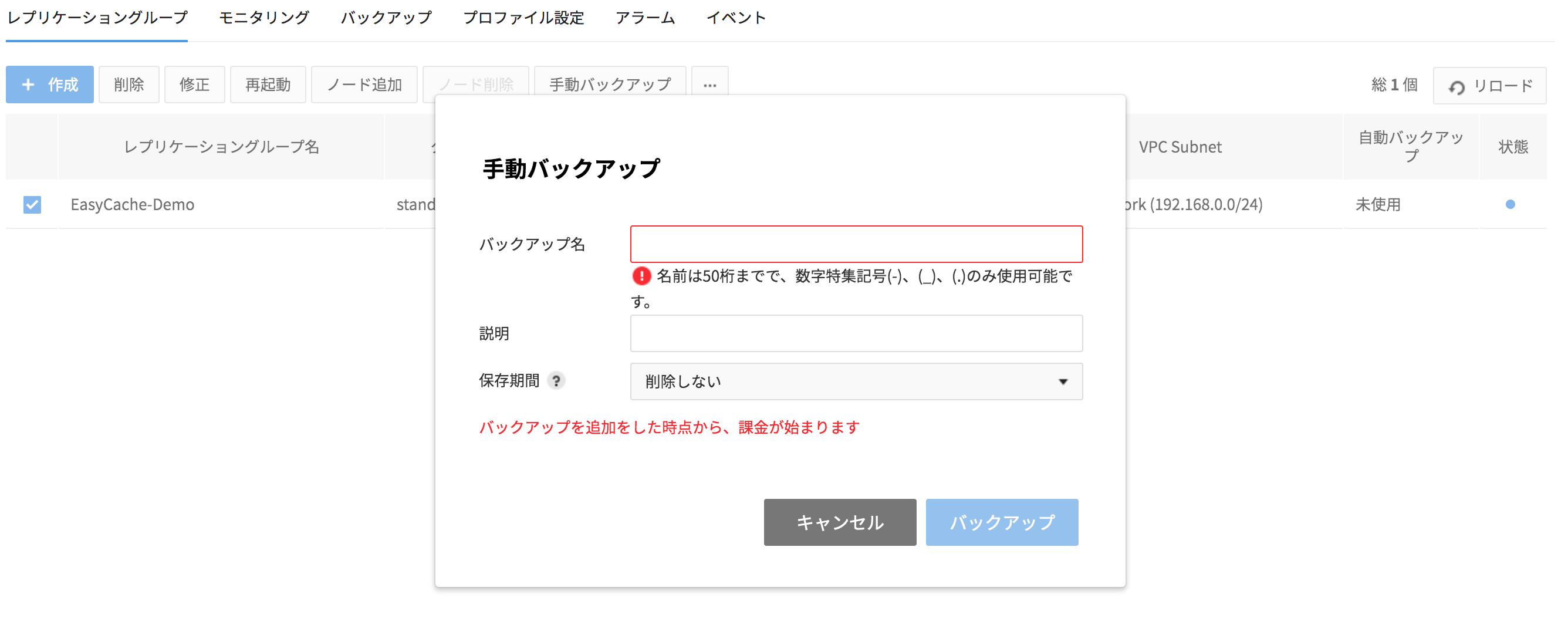
- 手動バックアップファイルを作成するために、対象レプリケーショングループを選択した後、 手動バックアップ ボタンを押します。
- バックアップ名:バックアップの名前を入力します。
- 説明:バックアップの説明を入力します。
- バックアップ保存期間:削除しない限り、1日~最大30日まで保管可能です。
- OKボタンを押すと、手動バックアップが作成されます。
- データサイズに比例してバックアップの作成時間が長くなる場合があります。
[注意] EasyCacheはRedisをベースにしたキャッシュサービスで、Webコンソールページで提供する自動および手動バックアップ機能以外のデータ永続性のための機能は提供しません。したがって再起動や予期できない障害などによるデータの消失時に自動および手動バックアップを行ったバックアップデータがない場合は復旧できません。
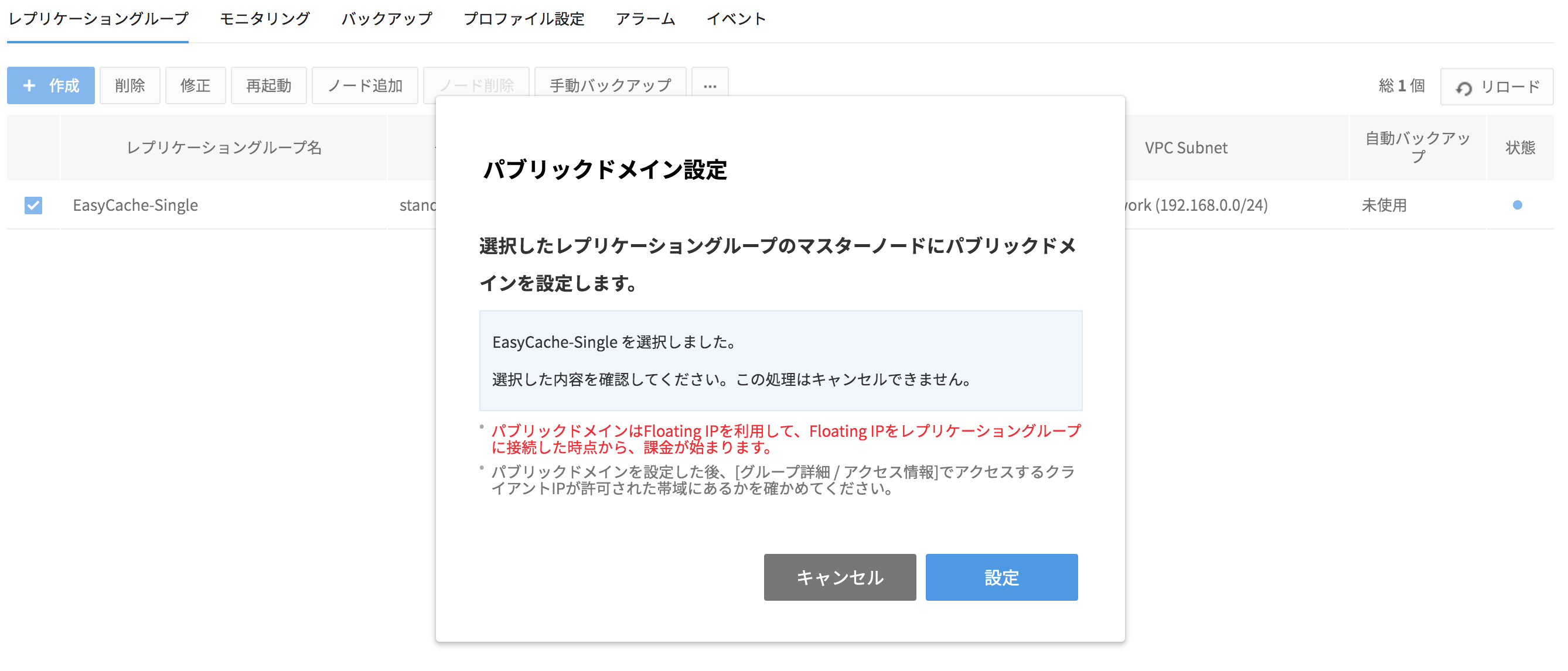
公認ドメイン設定
- レプリケーショングループは同じサーブネットを利用するインスタンスからのみアクセスでますが、外部からアクセスしたい場合はパブリクドメインを設定できます。
読み取り専用ドメイン設定
- Replicaノードが追加されている対象レプリケーショングループを選択した後、その他アクションボタン(⋯)をクリックして読み取り専用ドメイン設定をクリックし、読み取り専用ドメインを設定できます。
- 設定された読み取り専用ドメインは、レプリケーショングループを作成する時に選択したVPCサブネットで接続可能なプライベートドメインで、ReplicaノードのIPがバインディングされます。
- 設定された読み取り専用ドメインはレプリケーショングループ > 接続情報で確認できます。
-
Masterノードの障害によりフェイルオーバーが発生した場合
- Replicaノードが1つの場合
- Replicaノードに変更された旧Masterノードを復旧するか手動で削除した後、新しいReplicaノードを追加する前まで、読み取り専用ドメインはフェイルオーバーでMasterノードに昇格した旧ReplicaノードのIPが付与された状態が維持されます。
- Replicaノードに変更された旧Masterノードを復旧するか手動で削除した後、新しいReplicaノードを追加する場合、読み取り専用ドメインは新しいReplicaノードのIPにバインディングが変更されます。 * バインディングの変更に失敗した場合は、レプリケーショングループ > 接続情報より、手動で再試行できます。
- Replicaノードが2つの場合
- 新しいMasterノードに昇格した旧ReplicaノードのIPはバインディングから除外されます
- Replicaノードに変更された旧Masterノードを復旧するか手動で削除した後、新しいReplicaノードを追加する場合、読み取り専用ドメインに新しいReplicaノードのIPが追加されます。
-
Replicaノードに障害が発生したり、Replicaノードを削除する場合
- Replicaノードが1つの場合
- 読み取り専用ドメインはMasterノードのIPにバインディングが変更されます。
- Replicaノードを復旧するか、手動で削除した後、新しいReplicaノードを追加する場合、読み取り専用ドメインは新しいReplicaノードのIPにバインディングが変更されます。 * バインディングの変更に失敗すると、レプリケーショングループ > 接続情報より、手動で再試行できます。
- Replicaノードが2つの場合
- 読み取り専用ドメインから該当ReplicaノードのIPは除外されます。
- Replicaノードを復旧するか手動で削除した後、新しいReplicaノードを追加する場合、そのReplicaノードのIPが読み取り専用ドメインのバインディングに追加されます。
-
読み取り専用ドメインを設定した状態でレプリケーショングループの削除やサービスを無効化する場合、読み取り専用ドメインは解除されます。
制約事項
- 読み取り専用ドメインのバインディングが変更される場合
- Masterノードに障害が発生してフェイルオーバーした後、新しいReplicaノードを追加する場合など、接続を中断せずにバインディングが変更される場合
- 読み取り専用ドメインに接続したクライアントからドメインのバインディング変更を検知する機能をサポートしているか、該当ロジックが実装されている場合は変更されたバインディングIPで再接続するか、既存の接続を中断して再度接続する必要があります。
- Replicaノードに障害が発生したり、Replicaノードが削除される場合など、バインディング変更時に接続中断が伴う場合
- クライアントで自動再接続機能をサポートしているか、該当ロジックが実装されている場合は、変更されたバインディングIPで再接続しますが、そうでない場合は再度接続する必要があります。
- Masterノードに障害が発生してフェイルオーバーした後、新しいReplicaノードを追加する場合など、接続を中断せずにバインディングが変更される場合
データのインポート
- レプリケーショングループを選択した後、その他アクションボタン(⋯)をクリックしてデータのインポートをクリックしてデータをインポートできます。
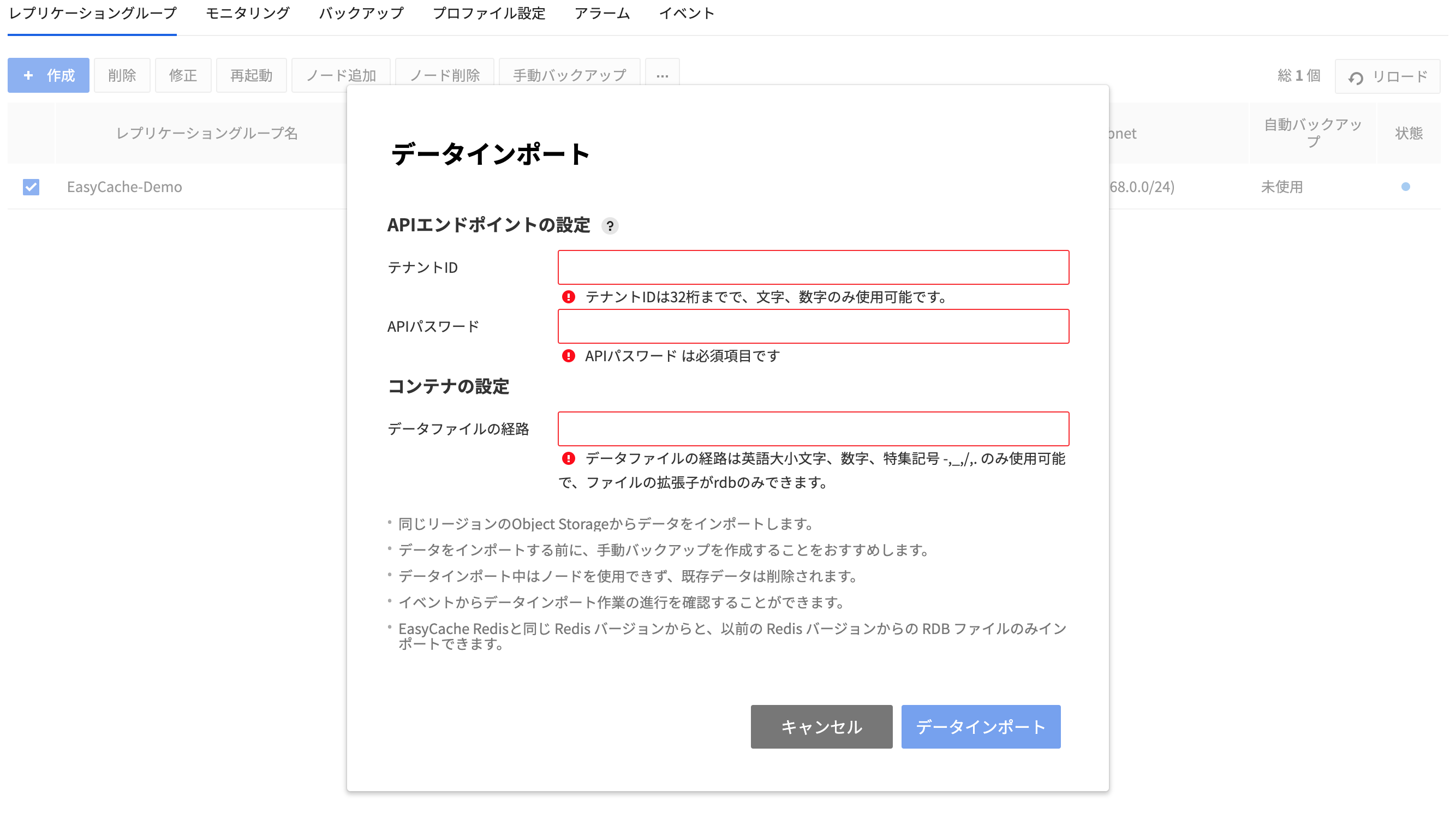
- ユーザーのオブジェクトストレージにあるRDBファイルを使用中のノードにインポートできます。この時、オブジェクトストレージとEasyCacheのリージョンは同じである必要があります。
- データをインポートする時、オブジェクトストレージのAPIエンドポイント設定、コンテナとRDBファイルパスが必要です。
- コンテナとRDBファイルパスは、英字大文字/小文字、数字、特殊記号 (-)(_)(/)(.)のみ入力できます。
- データのインポート後、ノードの以前のデータは削除されるため、インポート実行前にバックアップすることを推奨します。
- データのインポート進行中にはノードを利用できません。進行状況はイベントで確認できます。
- EasyCache Redisと同じバージョンか、前のバージョンで作られたRDBファイルのみインポートできます。EasyCache Redisより新しいバージョンで作られたRDBファイルはインポートできません。
データエクスポート
- レプリケーショングループを選択した後、その他アクションボタン(…)をクリックしてデータエクスポートをクリックするとデータをエクスポートできます。
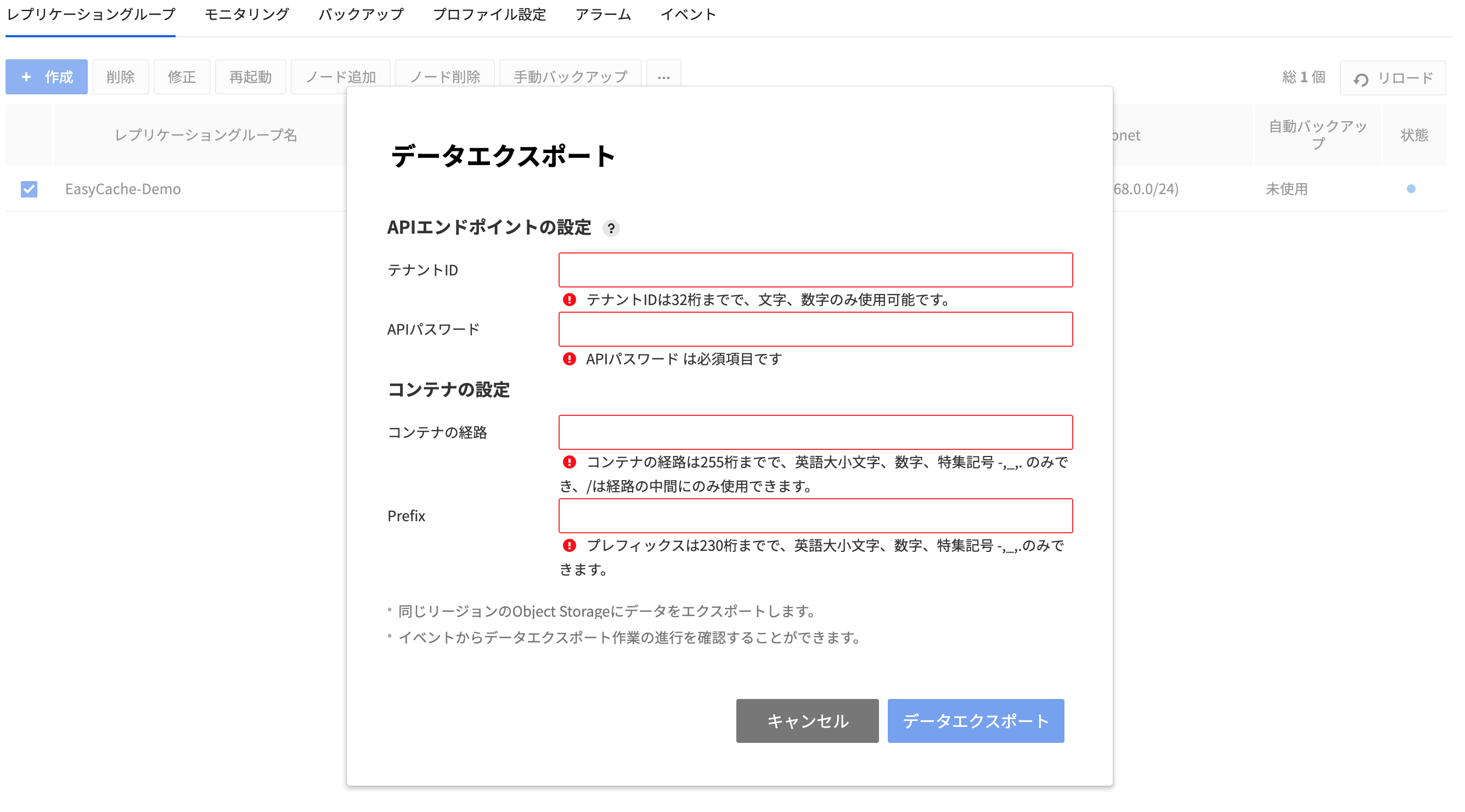
- EasyCacheレプリケーショングループのデータをユーザーのオブジェクトストレージにエクスポートできます。この時、オブジェクトストレージとEasyCacheのリージョンは同じでなければいけません。
- データをエクスポートする時、オブジェクトストレージのAPIエンドポイント設定、データをエクスポートするコンテナパス、ファイル名の作成に必要なPrefixを入力します。
- コンテナパスとPrefixは、英字大文字/小文字、数字、特殊記号 (-)(_)(/)(.)のみ入力できます。
- EasyCacheレプリケーショングループのデータが1ギガ以上の場合、オブジェクトストレージにエクスポートする時、セグメントオブジェクトが自動的に作成されます。
インスタンスタイプ変更
- 使用中のノードのインスタンスタイプを変更できます。
- インスタンスタイプは現在のノードより仕様が高いインスタンスへのみ変更できます。
- インスタンスタイプの変更中、ノードは一時的に停止します。
- レプリケーショングループがStandaloneの場合、インスタンスタイプを変更するとバックアップ時点のデータに戻り、バックアップを行っていない場合、データが初期化されます。
- Replicaノードがある場合、Masterノードのインスタンスタイプを変更するためにフェイルオーバー(failover)が発生します。
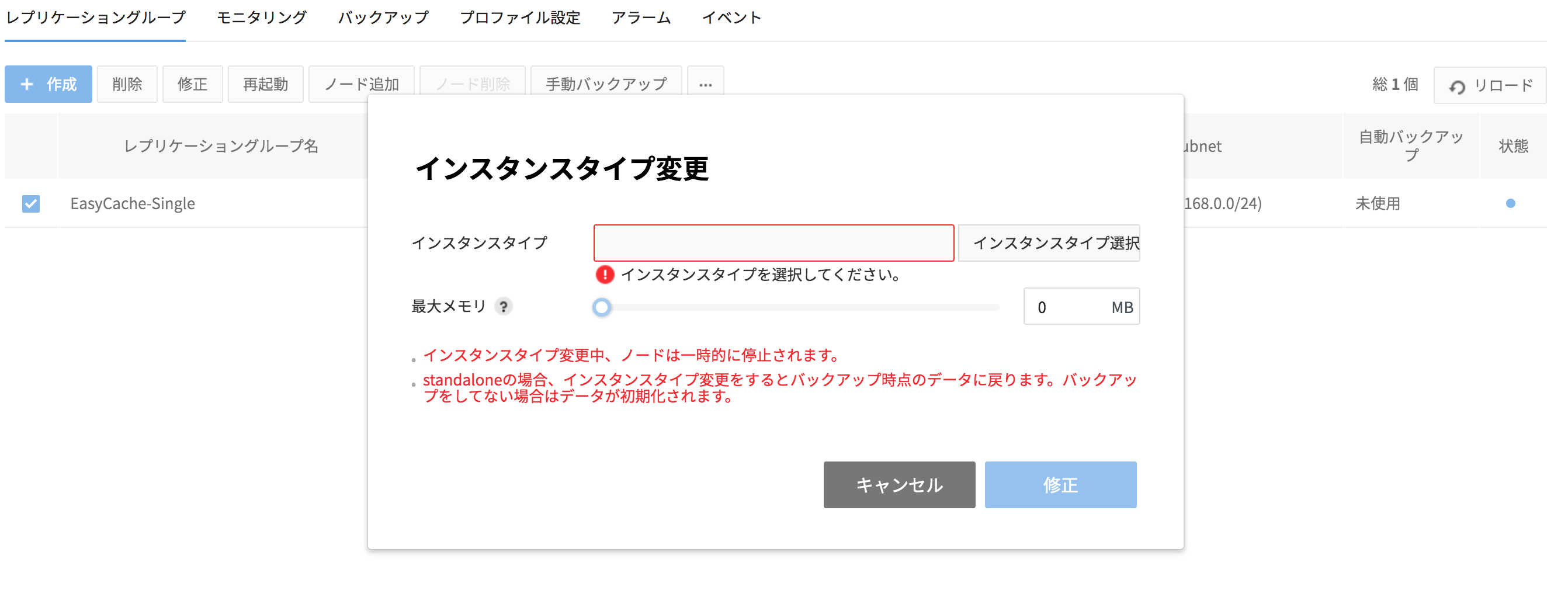
制約事項
- 手動バックアップの実行中は、手動バックアップを行えません。進行中の手動バックアップが完了してから再度お試しください。
- 自動バックアップ時間に手動バックアップを行う場合、手動バックアップがすぐに作成されず、遅延する場合があります。
バージョンアップグレード
- Redisバージョン5の既存レプリケーショングループをRedisバージョン6にアップグレードできます。
- バージョンアップグレードを実行するにはRedisバージョン5の対象レプリケーショングループを選択した後、その他アクションボタン(⋯)をクリックし、バージョンアップグレードをクリックします。
- バージョンアップグレードダイアログボックスでバージョンアップグレード時に適用される設定プロフィールを選択できます。
- バージョンアップグレードを実行する前にデータバックアップを行うと、データの消失など、万一の状況に備えることができます。
- レプリケーショングループのネットワークトラフィックが少ない時にバージョンアップグレードを実行すると、アップグレード速度および安定性を高めることができます。
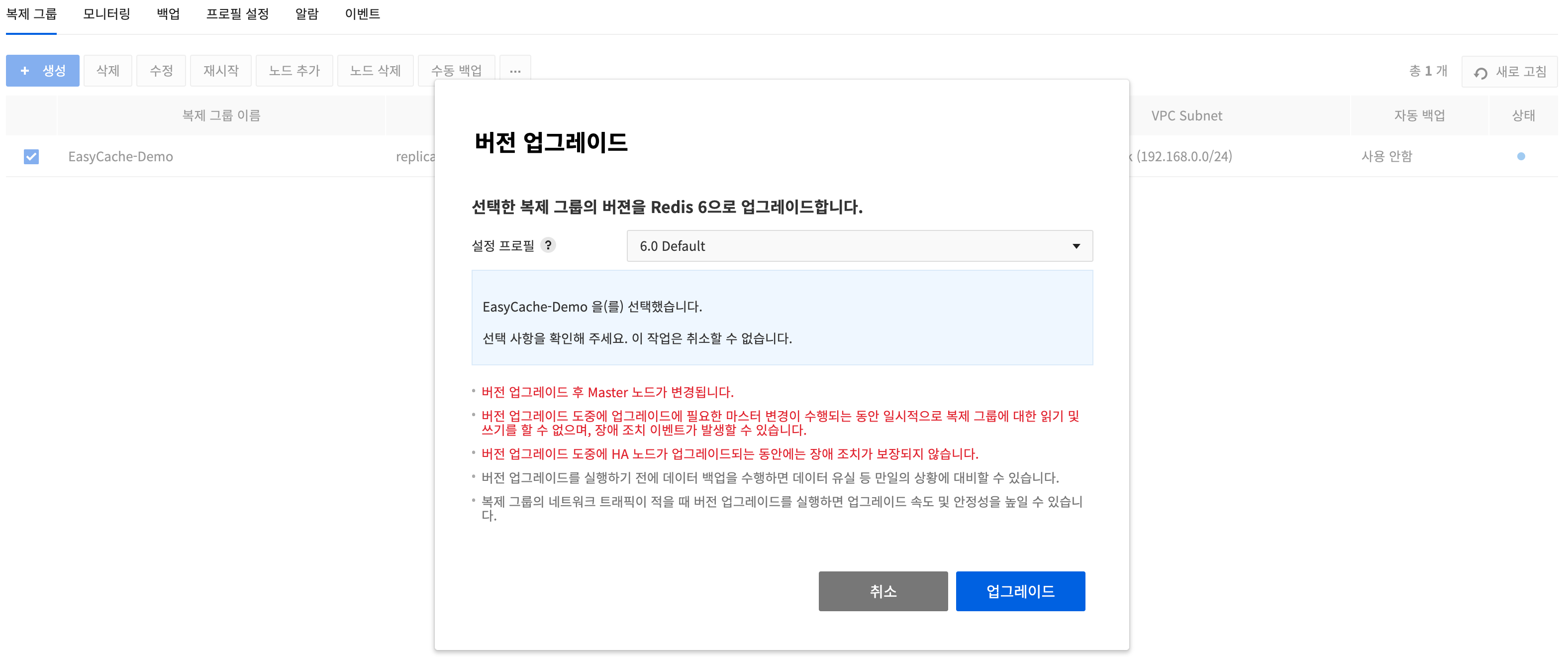
制約事項
- Redis 7.0.7未満のバージョンは、7.0.7バージョンに一度アップグレードした後、次のバージョンへのアップグレードが可能です。
- Redisバージョンをアップグレードしようとしている既存レプリケーショングループに基本設定プロフィール以外のユーザー設定プロフィールが適用されている場合、アップグレード時に同じ設定プロフィールを適用するにはプロフィール設定でRedisバージョン6のユーザー設定プロフィールをあらかじめ作成した後、バージョンアップグレード時に該当設定プロフィールを選択する必要があります。
- 読み取り専用ドメインが設定されている場合は、読み取り専用ドメイン設定を解除した後にバージョンをアップグレードできます。
- standaloneタイプのレプリケーショングループの場合
- バージョンアップグレード中に発生するレプリケーショングループの書き込みは、アップグレード以降のデータ復元対象から除外されます。
- バージョンアップグレード中にRedisサーバーが再起動すると、一時的にレプリケーショングループの読み取りおよび書き込みができません。
- replication タイプのレプリケーショングループの場合
- バージョンアップグレード後にMasterノードが変更されます。
- バージョンアップグレード中にアップグレードに必要なマスター変更が行われる間、一時的にレプリケーショングループの読み取りおよび書き込みを行うことができず、フェイルオーバー(failover)イベントが発生することがあります。
- バージョンアップグレード中にHAノードがアップグレードする間は、フェイルオーバーが保障されません。
- バージョンアップグレードに失敗した場合、レプリケーショングループ > ⋯ > バージョンアップグレードをクリックしてバージョンアップグレードを再度実行できます。
マスター変更
- Replicaノードが追加されている対象レプリケーショングループを選択した後、その他アクションボタン(…)をクリックしてマスター変更をクリックしてレプリケーショングループのMasterノードを変更できます。
- ReplicaノードはMasterノードに変更され、既存のMasterノードはReplicaノードに変更されます。
- Replicaノードが2つの場合、システムで適切なReplicaノードをMasterノードに変更します。
レプリケーショングループの詳細
- レプリケーショングループの詳細情報を確認できます。
- 基本情報
- 接続情報
- ノード情報
- モニタリング
基本情報
- 作成されたレプリケーショングループを選択し、基本情報 タブを押します。
- レプリケーショングループの詳細情報を確認できます。
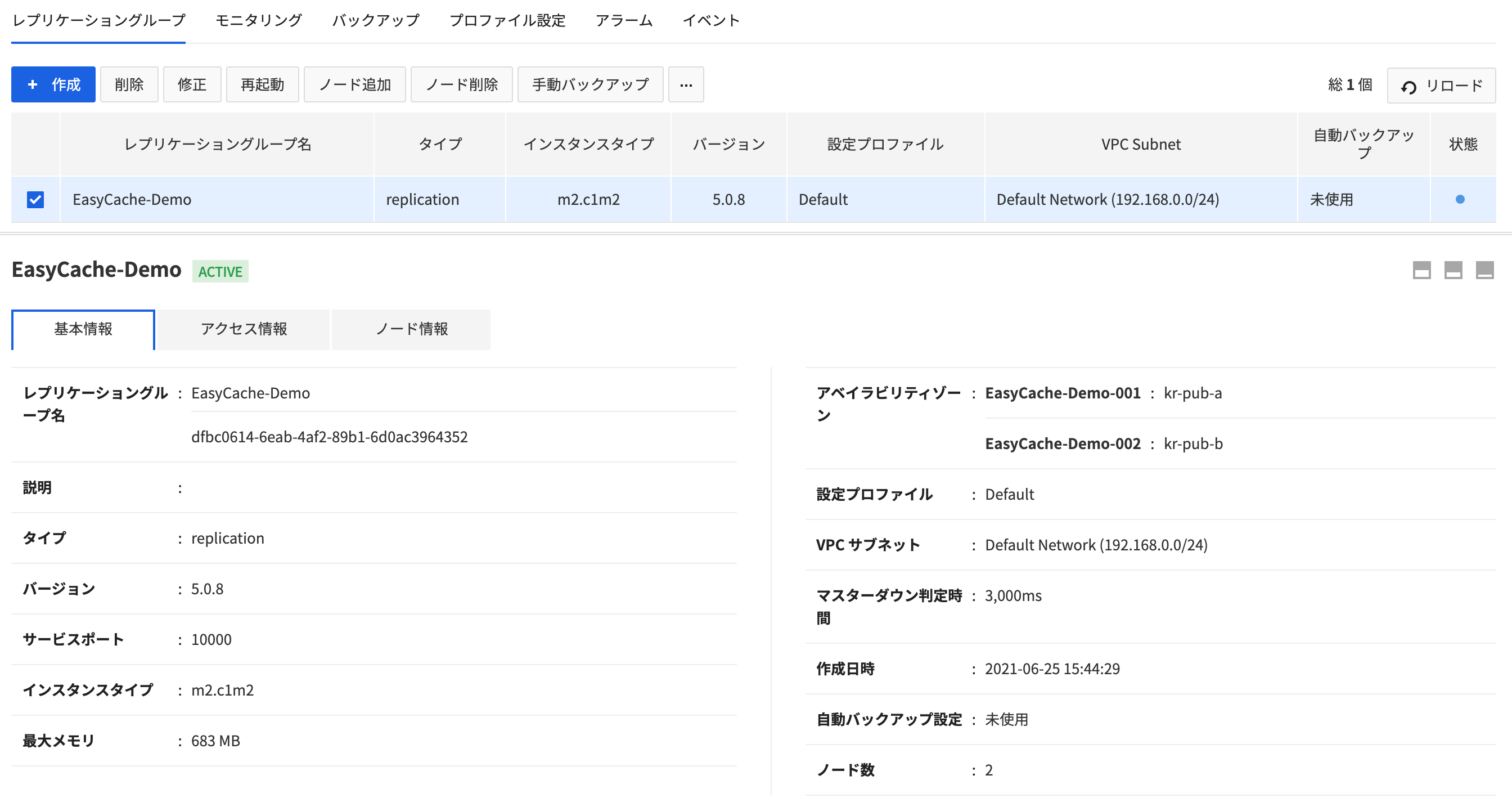
- 確認可能な項目は下記のとおりです。
- レプリケーショングループ名
- 説明
- タイプ
- バージョン
- サービスポート
- インスタンスタイプ
- 最大メモリ
- アベイラビリティゾーン
- 設定プロファイル
- VPC Subnet
- 作成日
- 自動バックアップ設定
- ノード数
Replicaノードがある場合、確認可能な項目は下記のとおりです。
- マスターダウン判定時間
レプリケーショングループ接続
- 作成されたレプリケーショングループを選択し、接続情報タブを押します。
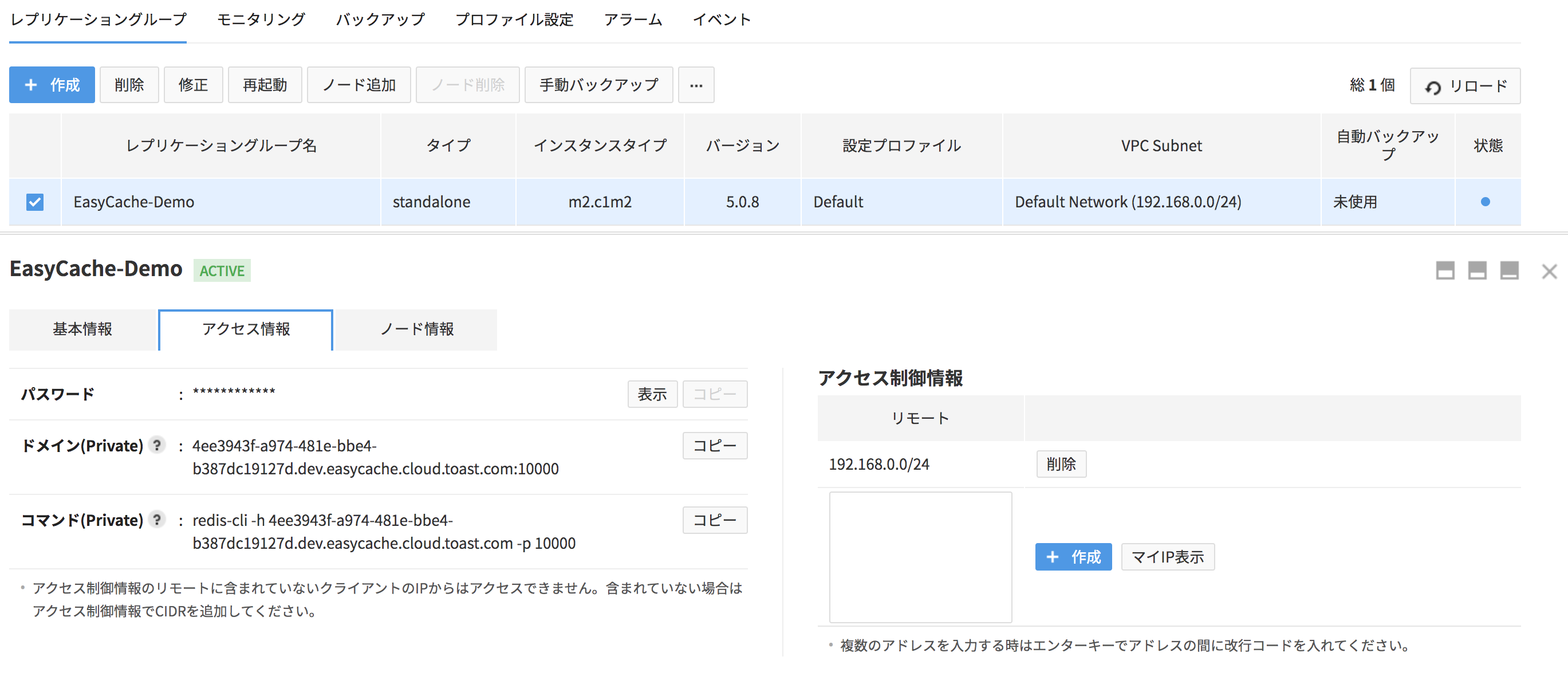
- 暗号化されたパスワードは表示ボタンを押すと確認できます。
- コピーボタンを押すと、パスワードをコピーできます。
- 接続可能なドメイン情報を確認できます。
- パブリックドメインを設定していないRedisノードは、外部からアクセスできません。
- コピーボタンを押すとドメインをコピーできます。
- TLS証明書を使用した複製グループの場合、下記のオプションを追加する必要があります。
- --tls: TLSを使用するかどうかを決定します。
- --cert {公開鍵パス}:接続に使用する証明書から抽出した公開鍵を入力します。
- --key {秘密鍵パス}:接続に使用する証明書から抽出した秘密鍵を入力します。
- --cacert {CAキーパス}:接続に使用する証明書から抽出したCAキーを入力します。
- **redisは公開鍵、秘密鍵、CA公開鍵の両方を必要とします。したがって、使用する証明書には当該鍵がすべて含まれている必要があり、当該鍵の作成方法はCertificate Manager > トラブルシューティングガイドを参照してください。
ex) redis-cli -h {IP orドメイン} -p {TLSサービスポート} --tls --cert {公開鍵パス} --key {秘密鍵パス} --cacert {CAキーパス}
- 接続情報は、同じVPCサブネットに接続されたノードのアプリケーションで使用できます。
- コマンドは、同じVPCサブネットに接続されたノードで実行可能です。
- 自分のIP表示:ローカルIPがCIDR形式で表示されます。
- 作成ボタンを押すと登録されます。
- 接続制御情報に登録されていないIPは接続できません。
ノード情報
- 作成されたレプリケーショングループを選択し、ノード情報タブを押すとレプリケーショングループのノードの詳細情報とログを確認できます。
- ノードのログを確認するにはログ表示ボタンを押します。
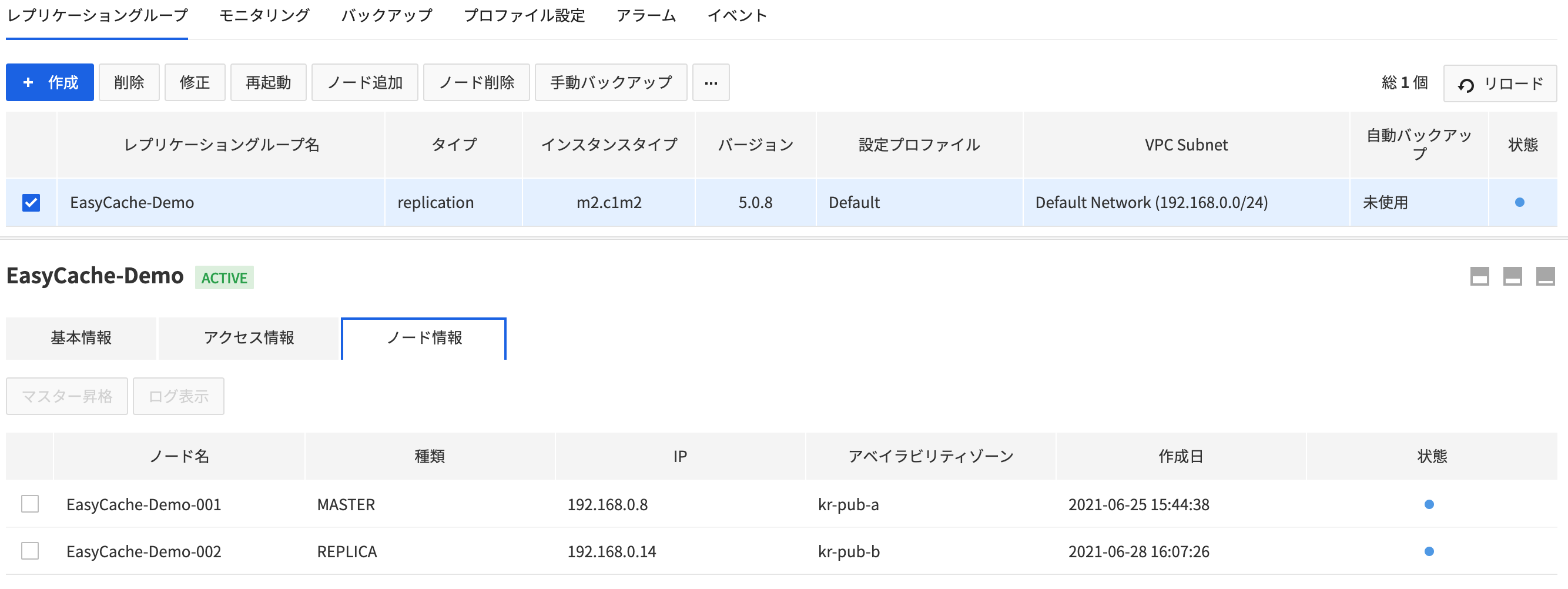
- 確認可能な項目は下記のとおりです。
- ノード名
- 種類
- IP
- アベイラビリティゾーン
- 作成日
- 状態
ログ表示
各ノードで最大1か月間のログを検索できます。
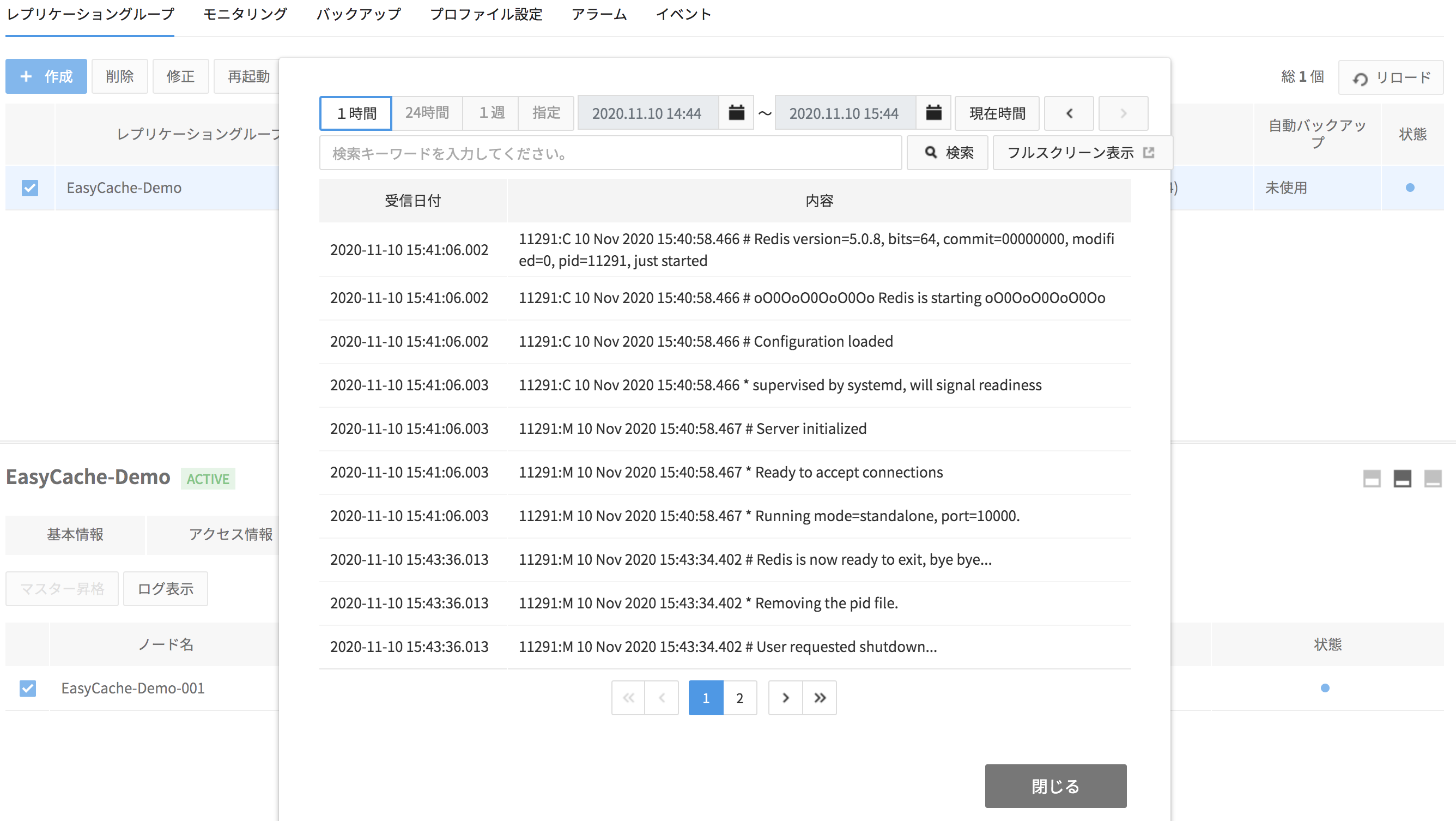
- 1時間、24時間、1週、指定 ボタンを押して検索期間を変更できます。
- 指定ボタンをクリックすると表示されるカレンダーで検索期間を自由に指定できます。
- 現在時間ボタンを押すと、現在時間を基準に選択した検索期間を再検索します。
- 現在時間ボタンの右にある矢印ボタンを押すと、検索期間の以前の時間、以降の時間を検索できます。
- 全体画面表示ボタンを押すと、新しいウィンドウで1か月間のすべてのログを確認できます。
モニタリング
EasyCacheはRedis運営に必要なモニタリング項目を1分毎に収集していて、収集したデータをチャートで表示します。
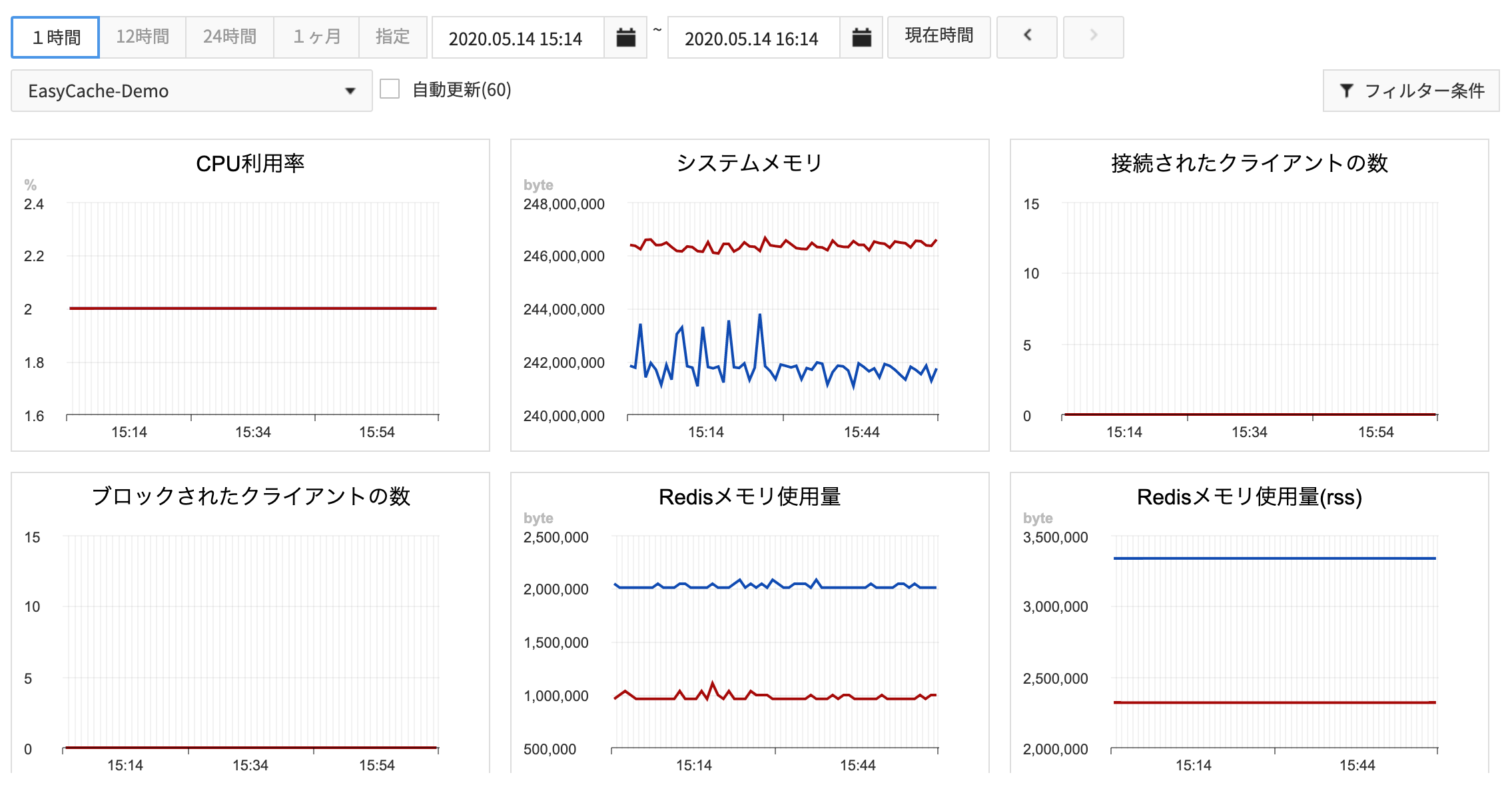
- 1時間、24時間などのボタンをクリックする度に現在時間を基準でチャートを更新します。
- 1時間 ボタンは1分毎に収集したデータをチャートで表示します。
- 12時間 ボタンは収集したデータの10分間の平均値をチャートで表示します。
- 24時間 ボタンは収集したデータの10分間の平均値をチャートで表示します。
- 1ヶ月 ボタンは収集したデータの6時間の平均値をチャートで表示します。
- 指定 ボタンをクリックして検索期間を自由に指定できます。
- カレンダーをクリックして検索基準の日時を指定できます。
- カレンダーで日付や時間を選択しても選択した期間は維持します。
- 現在時間 ボタンをクリックすると現在時間を基準で選択した検索期間を再検索します。
- 現在時間 ボタンのみぎにある矢印ボタンを利用して検索期間だけの移動ができます。
- レプリケーショングループドロップダウンからチャートを表示するレプリケーショングループを選択できます。
- 自動更新をチェックすると60秒毎にチャートのデータを更新します。
- チャートをクリックするとチャートを拡大して表示することができます。
- 拡大したチャートでは統計と集計期間を変更して表示することができます。
- 統計は集計データを表示する場合に利用されて、集計期間が1分になる場合はローデータを使用するので統計を変更しても同じ値を表示することになります。
- モニタリングデータの保存期間は40日です。
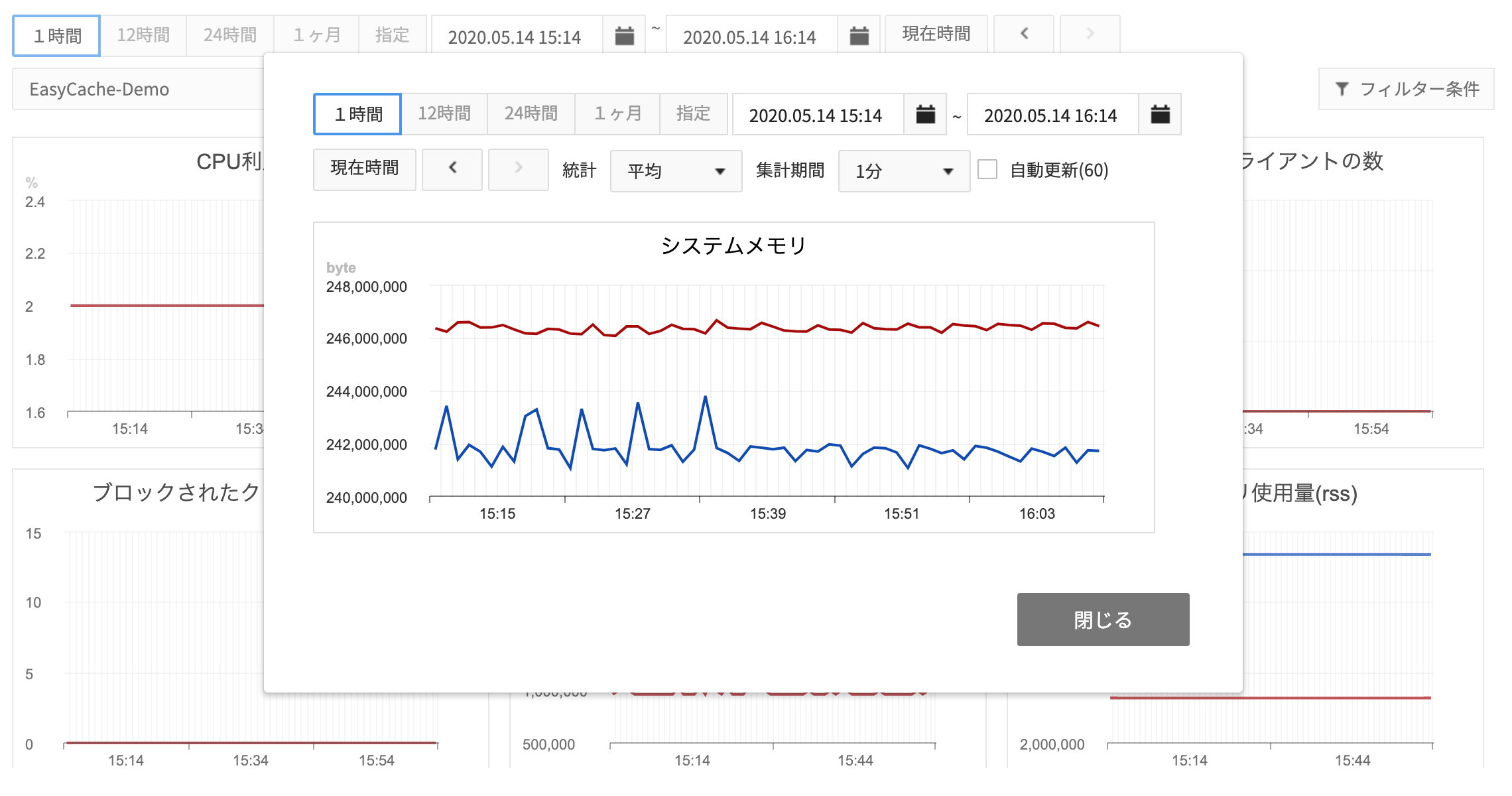
- モニタリング項目は フィルター条件で表示したい項目だけを選択できます。
- モニタリング項目
- CPU利用率
- システムメモリ
- 接続したクライアント
- ブロックしたクライアント
- Redisメモリ使用量(rss)
- メモリ断片化比率
- 秒に処理したコマンド数
- 入力バイト
- 出力バイト
- 削除されたキー数(expired)
- 削除されたキー数(evicted)
- 照会成功数
- 照会失敗数
- 照会成功率
- キーの個数
- get実行回数
- get usec/get calls
- set実行回数
- set usec/get calls
バックアップ
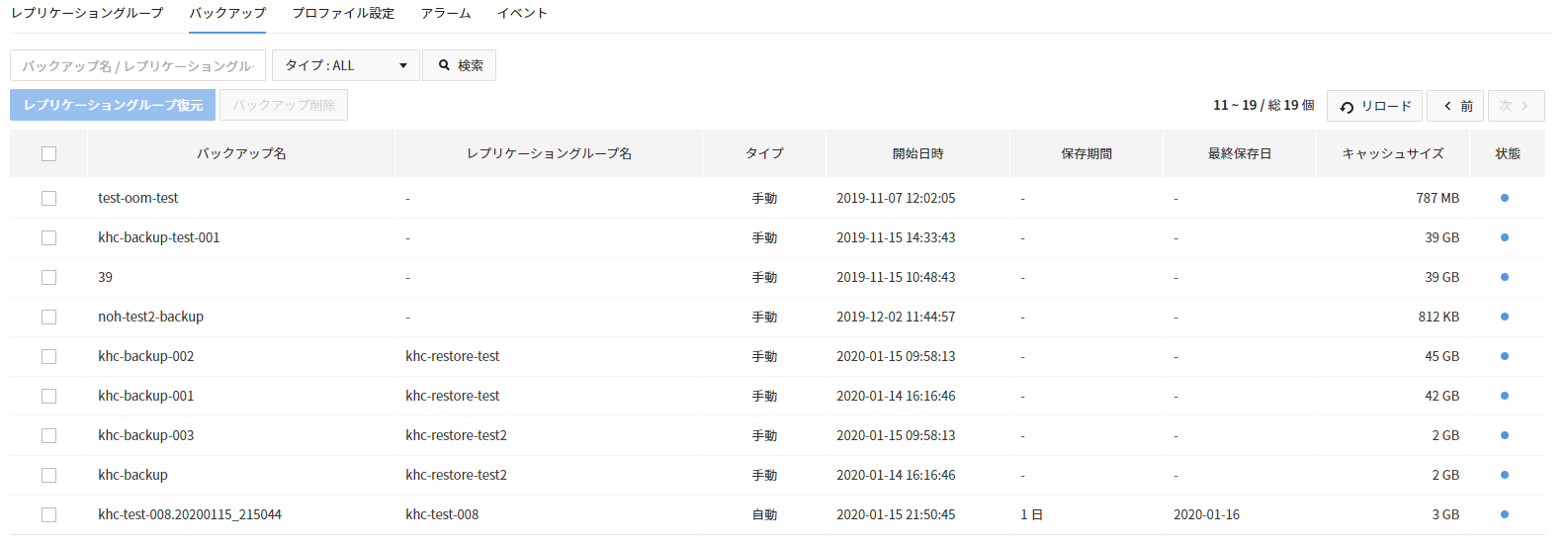
- EasyCache > バックアップタブを選択します。
- バックアップファイルを1つまたは複数選択して削除できます。
- バックアップの実行中は、バックアップによる性能低下が発生する場合があります。
- サービスに影響を与えないように、サービスの負荷が少ない時間にバックアップを行うことを推奨します。
- 検索ワード欄にバックアップ名またはレプリケーショングループ名の単語を入力して検索すると、検索結果が表示されます。
- 更新を利用し、バックアップファイルリストを更新して情報を確認できます。
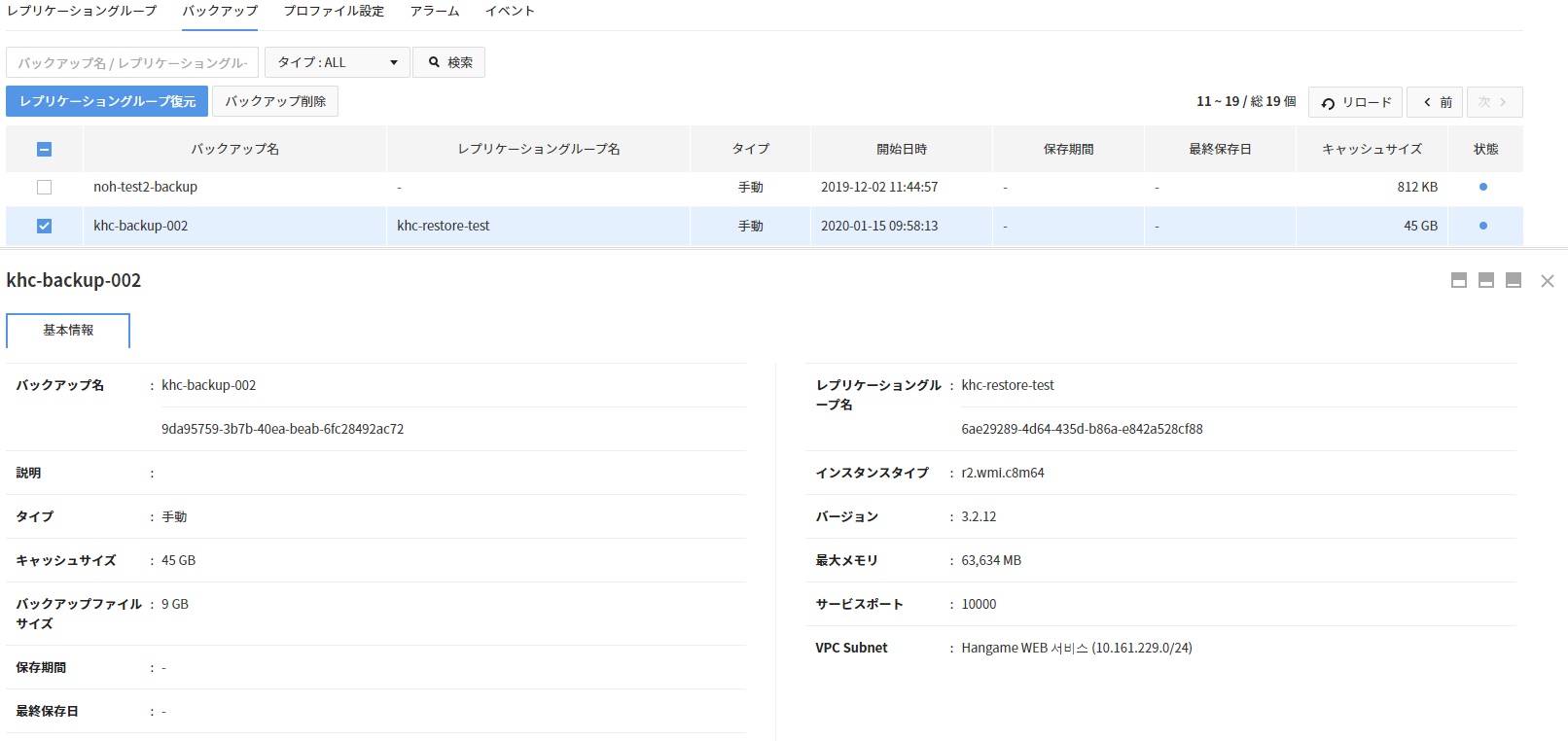
- 基本情報でバックアップファイルの詳細内容とレプリケーショングループの詳細内容を確認できます。
- バックアップ
- バックアップ名
- 説明
- バックアップタイプ
- キャッシュサイズ
- バックアップファイルサイズ
- バックアップ保存期間
- バックアップ最終保存日
- 状態
- バックアップ開始日時
- レプリケーショングループ
- レプリケーショングループ名
- インスタンスタイプ
- バージョン
- Max Memory
- サービスポート
- VPC Subnet
復元
- バックアップファイルを選択し、[レプリケーショングループ復元]を押します。
- 保存されたバックアップファイルを利用して、メモリデータを復元できます。
- 復元時に原本ノードを変更しないで、同じ仕様のノードを新たに作成します。
- 復元時に原本ノードを変更しないで、異なる仕様のノードを新たに作成します。
新規レプリケーショングループ復元
-
復元するにはバックアップファイルを選択し、新規レプリケーショングループ復元をクリックします。復元時に原本ノードを変更せず、同じ仕様または異なる仕様の新しいノードを作成できます。
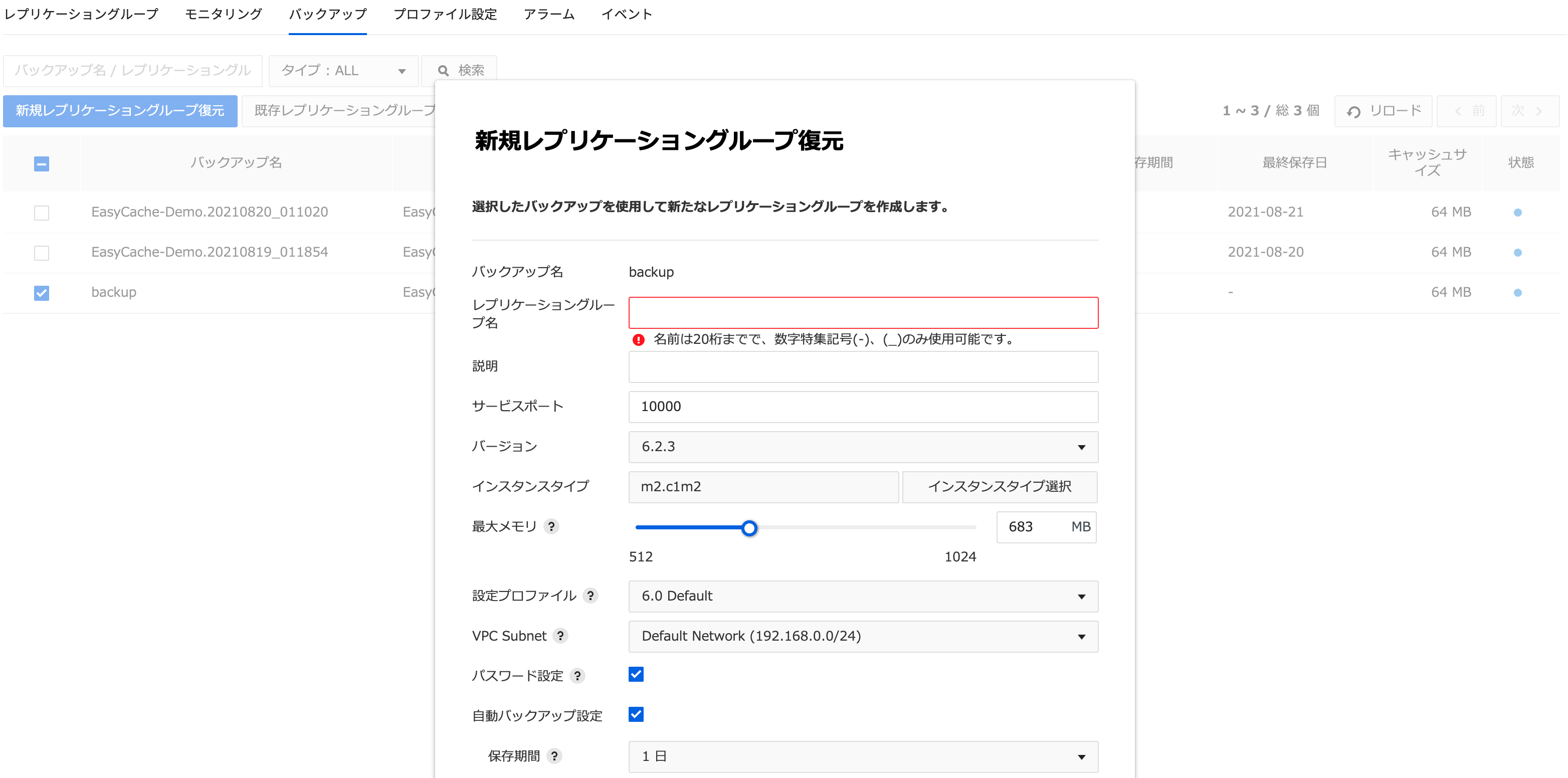
-
新規レプリケーショングループ復元ダイアログボックスで次の項目を入力し、作成ボタンをクリックします。作成されたレプリケーショングループはレプリケーショングループタブで確認できます。
- バックアップ名:復元するバックアップファイル名
- レプリケーショングループ名:レプリケーショングループの名前を入力します。
- 説明:レプリケーショングループの説明を入力します。
- サービスポート:バックアップ対象になったレプリケーショングループのポートが表示されます。
- Redisのポート番号を変更できます。
- 10000~12000の間で設定できます。
- バージョン:バックアップ対象になったレプリケーショングループのRedisバージョンが表示されます。
- インスタンスタイプ:バックアップ対象になったレプリケーショングループの仕様が表示されます。
- バックアップのキャッシュサイズより大きいインスタントタイプのみ表示されます。
- インスタントタイプを変更できます。
- Max Memory:Max Memoryを調整して、同期化やバックアップ実行時のメモリ不足を防止できます。
- Redisサーバーに使用する最大メモリ容量を変更できます。
- 最大メモリ容量を柔軟に変更できるようにすることで、必要に応じて管理用メモリの容量も柔軟に確保できます。
- 設定プロファイル:バックアップ対象になったレプリケーショングループのRedisの設定ファイルが表示されます。
- 設定プロファイルを追加して変更できます。
- VPC Subnet:バックアップ対象になったレプリケーショングループのVPC Subnetが表示されます。
- プライベートネットワーク通信を行いたいCompute & Networkサービスのsubnetを選択できます。
- 自動バックアップ設定:自動バックアップを行うかどうかを選択します。
- バックアップ保存期間:1日から最大30日まで保存可能です。
- バックアップ開始時間:バックアップ開始時刻を指定します。30分単位で指定可能です。
- バックアップ遅延時間:バックアップ開始時刻から指定した時間の間の任意の時点に開始します。 3時間まで指定可能です。
- 入力し、作成ボタンを押します。
- 作成されたレプリケーショングループは、レプリケーショングループタブで確認できます。
既存レプリケーショングループ復元
-
復元するにはバックアップファイルを選択し、既存レプリケーショングループ復元をクリックします。選択したレプリケーショングループのデータをバックアップデータに変更します。
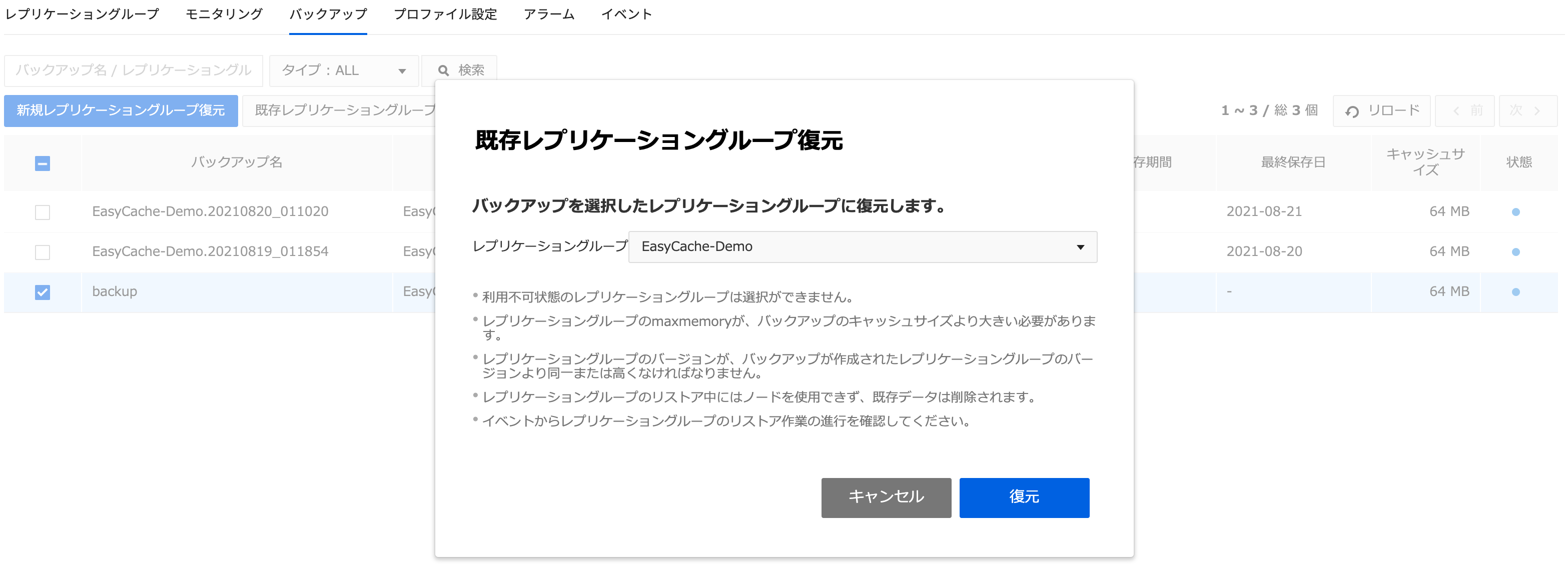
-
レプリケーショングループの復元中にはノードを使用することができず、既存のデータは削除されます。進行状況はイベントで確認できます。
- 利用不可状態のレプリケーショングループは選択することができず、レプリケーショングループのmaxmemoryがバックアップのキャッシュサイズより大きくなければいけません。
- バックアップが作られたレプリケーショングループのバージョンと同じか、それより高いバージョンのレプリケーショングループにのみ復元できます。
設定プロファイル
設定プロファイル作成
- EasyCacheは変更が可能なRedisの設定をプロファイル形式で登録して管理できます。
- 変更が可能なRedisの設定をプロファイルに登録するために、プロファイル設定タブを選択した後、作成ボタンを押します。
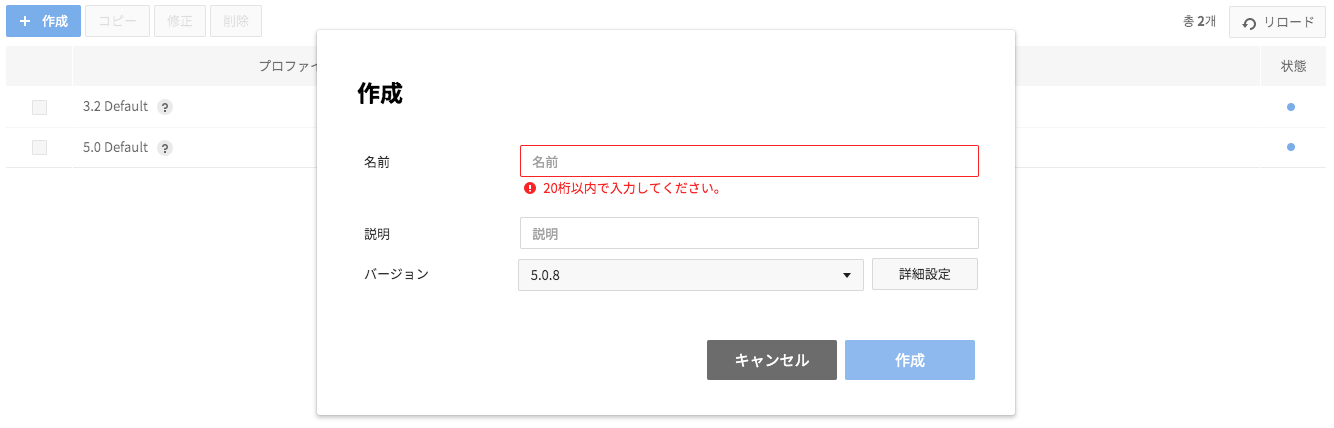
* プロファイル名:プロファイル名を入力します。
* 説明:プロファイルの説明を入力します。
* バージョン:プロファイルのバージョンを選択します。
- 詳細設定 を押して項目値を入力し、OKボタンを押します。
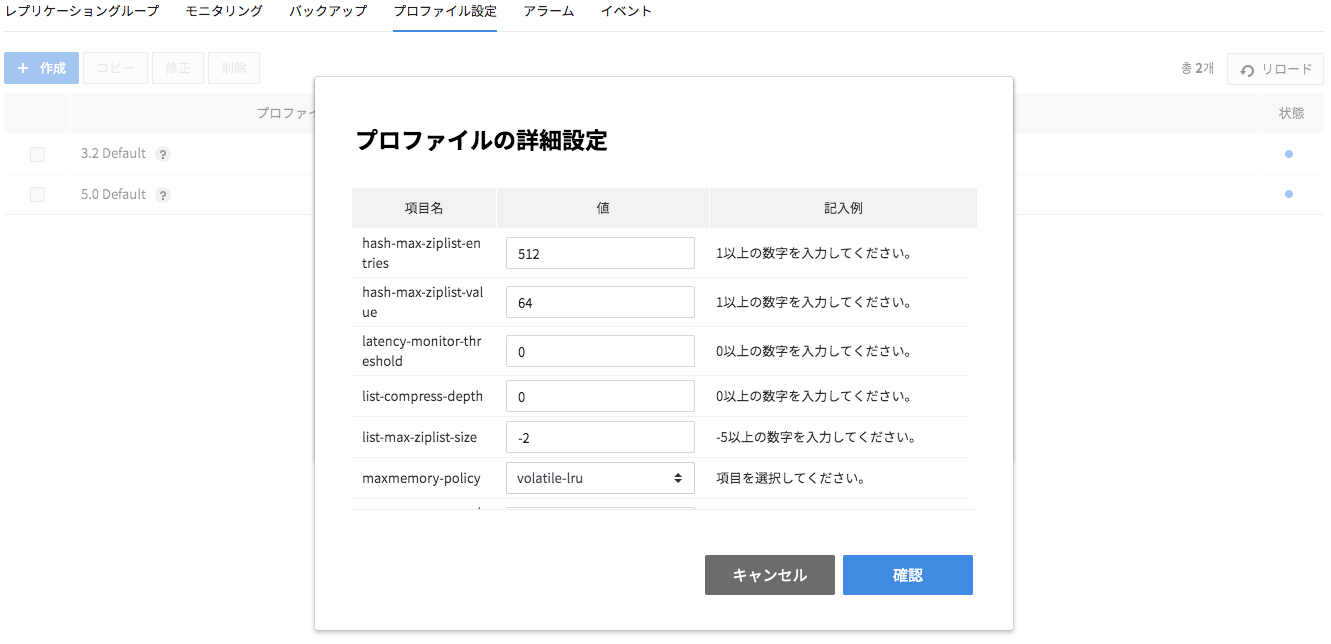
- 登録したプロファイル情報を修正します。
- 利用中のノードにも反映されます。
- 登録したプロファイルを削除します。
- 利用中のノードがあるプロファイルは削除できません。
- 登録したプロファイルをコピーすることが可能です。また、コピーの際に設定値を変更することが可能です。
- 基本設定情報があるDefaultプロファイルを提供します。
- Defaultプロファイルは修正、削除できません。
- プロファイルの状態を確認できます。
- 正常
- プロファイルを修正、削除できます。
- 変更適用中
- プロファイルを変更し、変更内容を各ノードに配信中の状態です。
- 変更内容の配信が終わると、状態は正常に変更されます。
- 変更中状態ではレプリケーショングループの作成、修正、削除ができません。
- 利用中
- プロファイルを利用して作成、変更中のレプリケーショングループがある状態です。
- レプリケーショングループの作成完了後、状態は正常に変更されます。
- プロファイルが利用中の状態では、プロファイルの作成、修正はできません。
- 正常
制約事項
- 設定情報はプロフィールを作成する時に詳細情報設定ボタンを押すか、プロフィールを修正またはコピーする時に変更できます。
- 範囲を超えた値を入力したり、適切でない項目値を入力すると、障害が発生する場合があります。
- 項目値の範囲や適切な入力値はRedis文書を参照してください。
プロファイル詳細
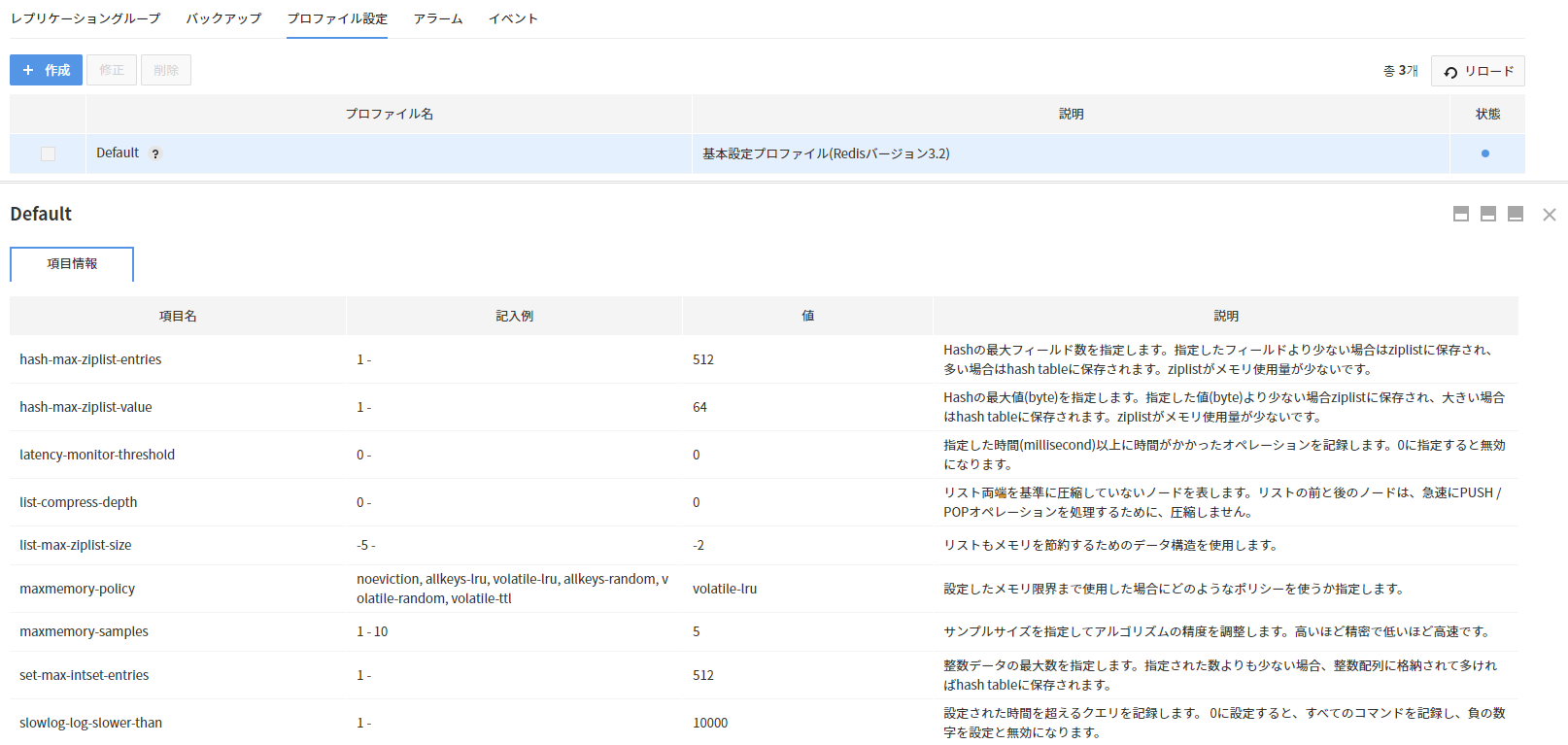
- プロファイルの詳細情報を確認できます。
- 項目名
- 記入例:項目の入力例
- 項目値:実際に設定された値
- 説明:項目の説明
- プロファイルの項目
- hash-max-ziplist-entries
- hash-max-ziplist-value
- latency-monitor-threshold
- list-compress-depth
- list-max-ziplist-size
- maxmemory-policy
- maxmemory-samples
- set-max-intset-entries
- slowlog-log-slower-than
- slowlog-max-len
- tcp-keepalive
- timeout
- zset-max-ziplist-entries
- replica-ignore-maxmemory(Redis 5.0追加)
- lazyfree-lazy-eviction(Redis 5.0追加)
- lazyfree-lazy-expire(Redis 5.0追加)
- lazyfree-lazy-server-del(Redis 5.0追加)
- repl-backlog-size(Redis 5.0追加)
- stream-node-max-bytes(Redis 5.0追加)
- stream-node-max-entries(Redis 5.0追加)
- client-query-buffer-limit(Redis 5.0追加)
- proto-max-bulk-len(Redis 5.0追加)
- activedefrag(Redis 5.0追加)
- active-defrag-ignore-bytes(Redis 5.0追加)
- active-defrag-threshold-lower(Redis 5.0追加)
- active-defrag-threshold-upper(Redis 5.0追加)
- active-defrag-cycle-min(Redis 5.0追加)
- active-defrag-cycle-max(Redis 5.0追加)
- active-defrag-max-scan-fields(Redis 5.0追加)
- active-expire-effort(Redis 6.0追加)
- lazyfree-lazy-user-del(Redis 6.0追加)
アラーム
- EasyCacheは、指定したリソースで発生する特定イベントに対するアラームを受信グループに伝達できます。

アラームルール
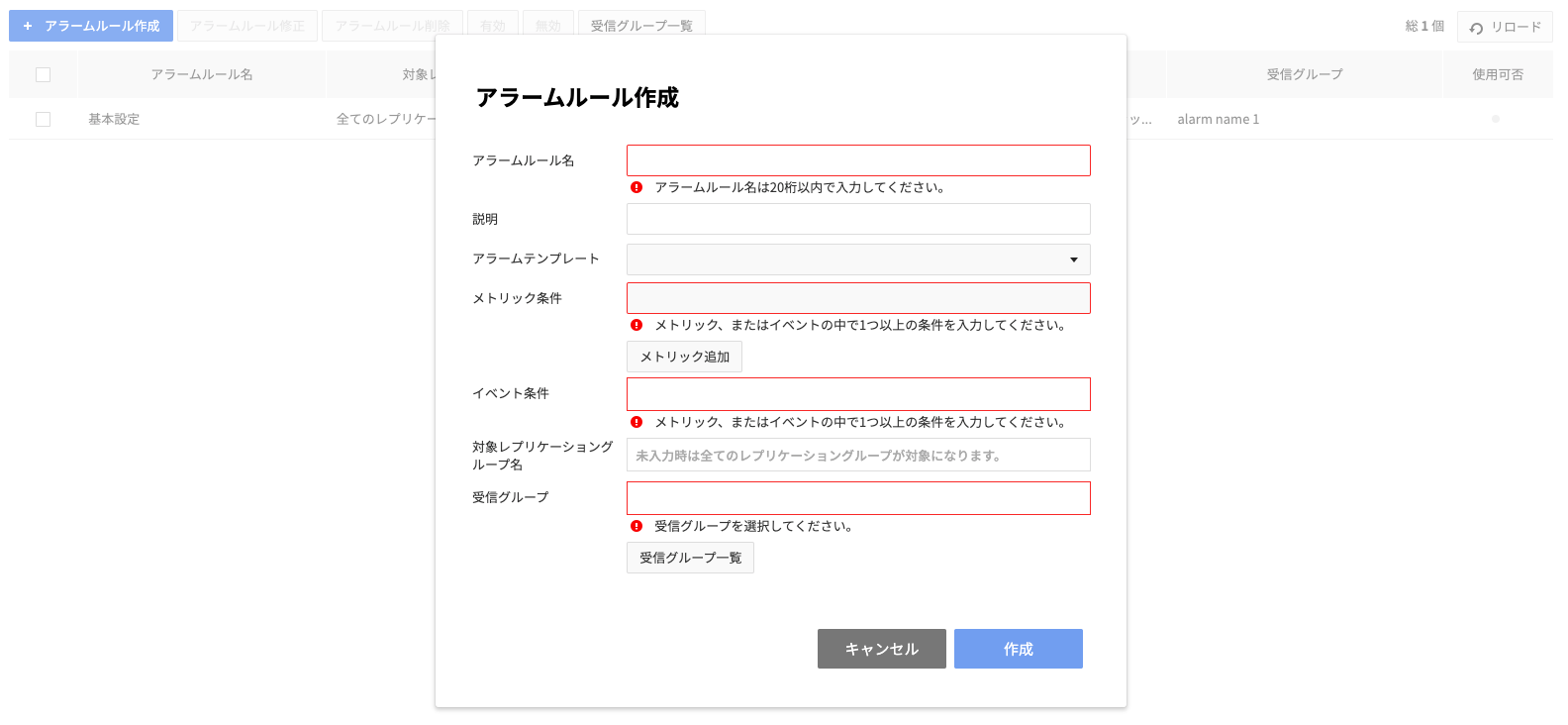
- アラームを発生させる条件と対象、受信グループを指定して作成するアラームのトリガーです。
- アラームを設定するには、アラームタブを選択した後、アラームルール作成ボタンを押します。
-
アラームルールにはアラーム発生条件とアラームを受信する受信グループを指定します。
- アラームの発生条件にはマトリックス条件とイベント条件の2つがあります。
- マトリックス条件:キャッシュインスタンスで収集した各種性能指標値(モニタリング項目参照)を利用してアラーム条件を指定し、下記のような条件を指定できます。
- マトリックス名
- 演算子
- 集計の種類
- 評価の頻度
- しきい値
- イベント条件:サービス内で発生するすべてのイベントの中から、アラームを受信したいイベント(イベント項目参照)を指定できます。
- マトリックス条件:キャッシュインスタンスで収集した各種性能指標値(モニタリング項目参照)を利用してアラーム条件を指定し、下記のような条件を指定できます。
- アラームの発生条件にはマトリックス条件とイベント条件の2つがあります。
-
マトリックス条件とイベント条件に必要な設定を決定するのが難しい場合は、アラームテンプレートで提供する基本テンプレートを利用することを検討してください。
- 基本-Standalone:standaloneで運営中のレプリケーショングループに推薦するアラーム発生条件
- 基本-HA:replicationで運営中のレプリケーショングループに推薦するアラーム発生条件
- 受信グループは、別途のダイアログで確認、追加できます。
- 作成したアラームルールは、基本的にはすべてのレプリケーショングループが対象ですが、対象レプリケーショングループを指定して特定レプリケーショングループ用のアラームルールを作成できます。
- 設定後、OKボタンをクリックします。
- 作成したアラームルールは、アラーム機能を「使用しない」に変更して一時的にアラームを停止できます。 アラームルールはすべてのリージョンに同じように適用されます。
受信グループ
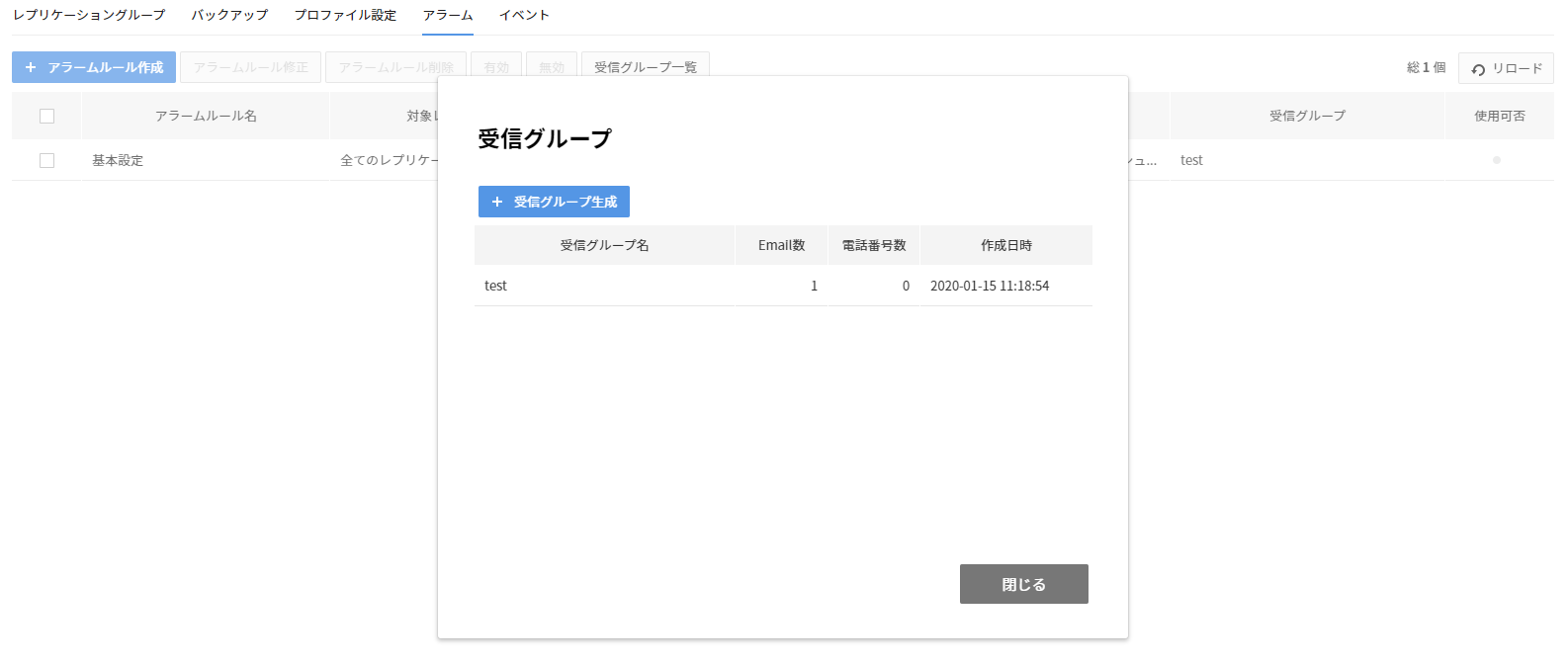
- アラームを受け取る受信者のグループを作成して管理できます。
- 受信グループを確認するには、アラームルール一覧、またはアラームルール作成、変更画面の受信グループ一覧ボタンを押します。
- 受信グループを作成するには、受信グループ一覧で受信グループ作成ボタンを押します。
- 受信グループで指定できる受信者は、プロジェクトメンバーだけです。
- NHN Cloud会員情報に登録したEmail、電話番号にEmail、SMSを送信できます。
- アラームルールで使用中の受信グループを削除すると、アラームルールからも削除されるため、他の受信グループがないアラームルールの場合、今後はアラームを送らなくなるため、注意が必要です。
作成した受信グループはすべてのリージョンで同じように利用できます。
制約事項
- アラームルールの対象レプリケーショングループにレプリケーショングループを1つだけ入力し、そのレプリケーショングループをレプリケーショングループ画面から削除した場合、アラームは唯一の対象レプリケーショングループがなくなった関係で、今後はすべてのレプリケーショングループを対象として認識します。
- アラームルールの受信グループに受信グループを1つだけ入力し、その受信グループを受信グループ詳細画面から削除した場合、アラームは唯一の受信グループがなくなった関係で今後はアラームを送れなくなります。
- レプリケーショングループ作成のアラームは、対象レプリケーショングループがあってもすべてのレプリケーショングループが対象になりアラームを送ります。
- プロジェクトに新しいユーザーを追加する場合、受信グループのプロジェクトユーザーリストに同期されるまで、1時間程度かかる場合があります。
- アラームルールの対象レプリケーショングループに特定レプリケーショングループを指定しても、他のリージョンではレプリケーショングループが指定されていない状態にアラームルールが同期化され、すべてのレプリケーショングループにアラームルールが適用されます
イベント
- EasyCache > イベントタブを選択します。
- EasyCacheは、レプリケーショングループで発生した意味のあるイベントを自動的に記録します。
- 検索ワード欄に単語を入力して検索すると、イベントのリソース名と説明を対象に検索結果を表示します。
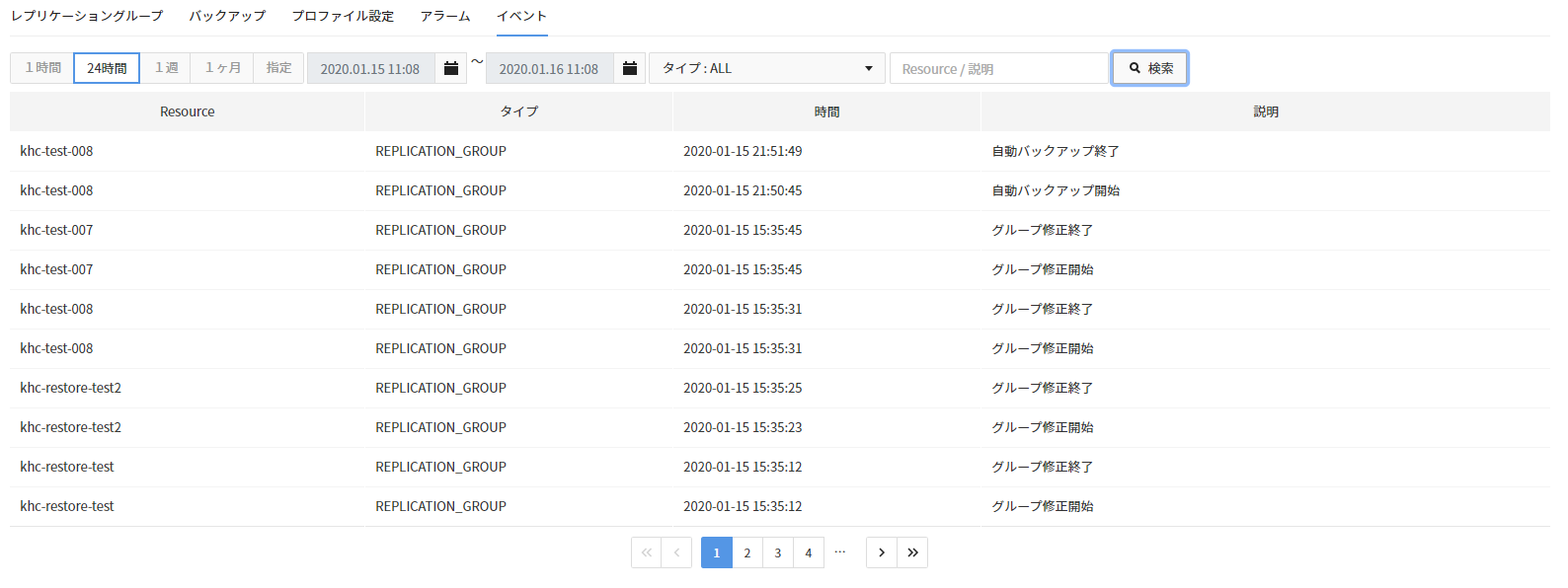
- 時間、日別に検索できます。
- イベントデータの保存期間は1か月です。
- イベントタイプは、どのリソースで発生したイベントなのかを指します。
- ALL:NODEとREPLICATION_GROUP関連のイベントです。
- NODE:NODEに関連するイベントです。
- REPLICATION_GROUP: REPLICATION_GROUPに関連するイベントです。
- FROFILE:FROFILEに関連するイベントです。
イベント項目
| タイプ | イベント | イベント詳細 |
|---|---|---|
| レプリケーショングループ | 削除 | 開始、失敗、終了 |
| 作成 | 開始、失敗、終了 | |
| 修正 | 開始、失敗、終了 | |
| 再起動 | 開始、失敗、終了 | |
| データインポート | 開始、ユーザーOBS設定失敗、データファイルダウンロード失敗、サポートしていないファイル形式、インポートできないRDBバージョン、Max memory不足、破損したファイル、ノード再起動失敗、レプリカ同期失敗、終了 | |
| データエクスポート | 開始、ユーザーObject Storage Service設定失敗、データファイル作成失敗、データファイルアップロード失敗、終了 | |
| 既存レプリケーショングループ復元 | 開始、データファイルダウンロード失敗、サポートしていないファイル形式、復元できないRDBバージョン、Max memory不足、破損したファイル、ノード再起動失敗、レプリケカ同期失敗、終了 | |
| HA設定更新 | 開始、失敗、終了 | |
| バージョンアップグレード | 開始、失敗、終了 | |
| マスター変更 | 開始、失敗、終了 | |
| パブリックドメイン | 設定 | 開始、失敗、終了 |
| 解除 | 開始、失敗、終了 | |
| 読み取り専用ドメイン | 設定 | 開始、失敗、終了 |
| 解除 | 開始、失敗、終了 | |
| キャッシュインスタンス | 接続 | 成功、失敗 |
| ノード | 削除 | 開始、失敗、終了 |
| 追加 | 開始、失敗、終了 | |
| 状態 | 無効化済、有効化済 | |
| プロファイル | 修正 | 開始、失敗、終了 |
| 自動HA | 削除 | 開始、終了 |
| 設定 | 開始、失敗、終了 | |
| failover | 施工 | |
| バックアップ | 手動バックアップ | 開始、失敗、終了 |
| 自動バックアップ | 開始、失敗、終了 |
付録1. ハイパーバイザメンテナンスのためのEasyCache再起動ガイド
- EasyCacheノードを再起動するにはコンソールにある再起動 機能を使用する必要があります。
- レプリケーショングループの再起動機能では、ノードが異なるハイパーバイザへ移動しません。下記のガイドに従ってコンソールにある再起動機能を利用してください。
1. メンテナンス対象に指定されたノードがあるプロジェクトへ移動します。
2. メンテナンス対象レプリケーショングループを確認します。
- レプリケーショングループ名の横に!再起動アイコンがあるレプリケーショングループがメンテナンス対象ノードが含まれるレプリケーショングループです。

- !再起動アイコンにマウスオーバーすると、詳細なメンテナンス日程を確認できます。
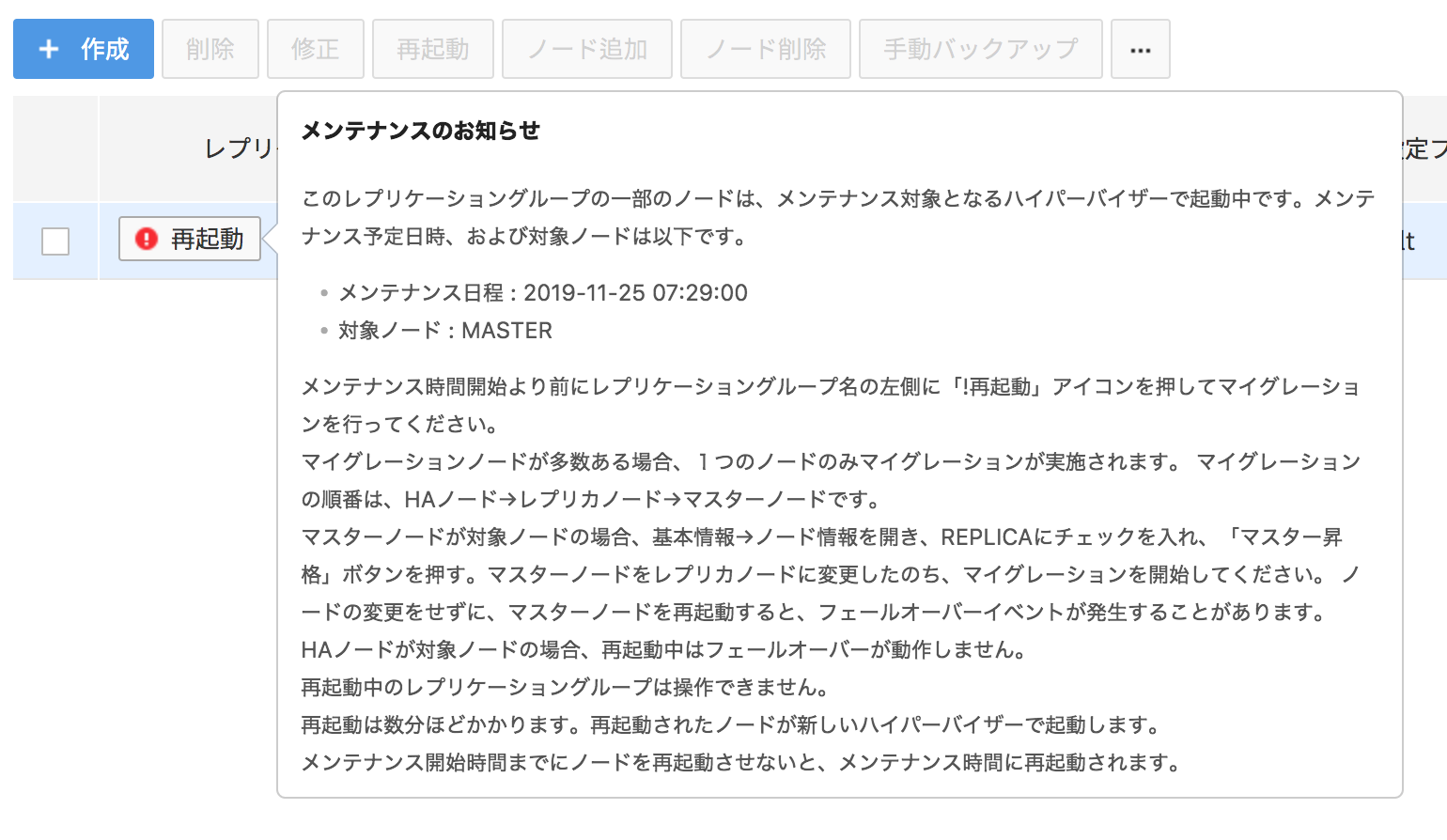
3. メンテナンス対象ノードのタイプを確認します。
- 各ノードタイプで再起動に伴うサービスへの影響は下記のとおりです。
- MASTER:レプリケーショングループ > マスター変更を選択してMasterノードをReplicaノードに変更した後、再起動機能を利用できます。Standaloneの場合は変更しないで利用できます。
- REPLICA:サービスに影響はありません。
-
HA:再起動する間にフェイルオーバー(failover)が保障されず、フェイルオーバー(failover)イベントが発生する場合があります。
-
ノード移動によりサービスに影響があると判断される場合、NHN Cloudサポートへ連絡してくだされば適切な処置をご案内します。
4. メンテナンス対象レプリケーショングループを選択し、右に表示された!再起動アイコンをクリックしてメンテナンスノードを再起動します。
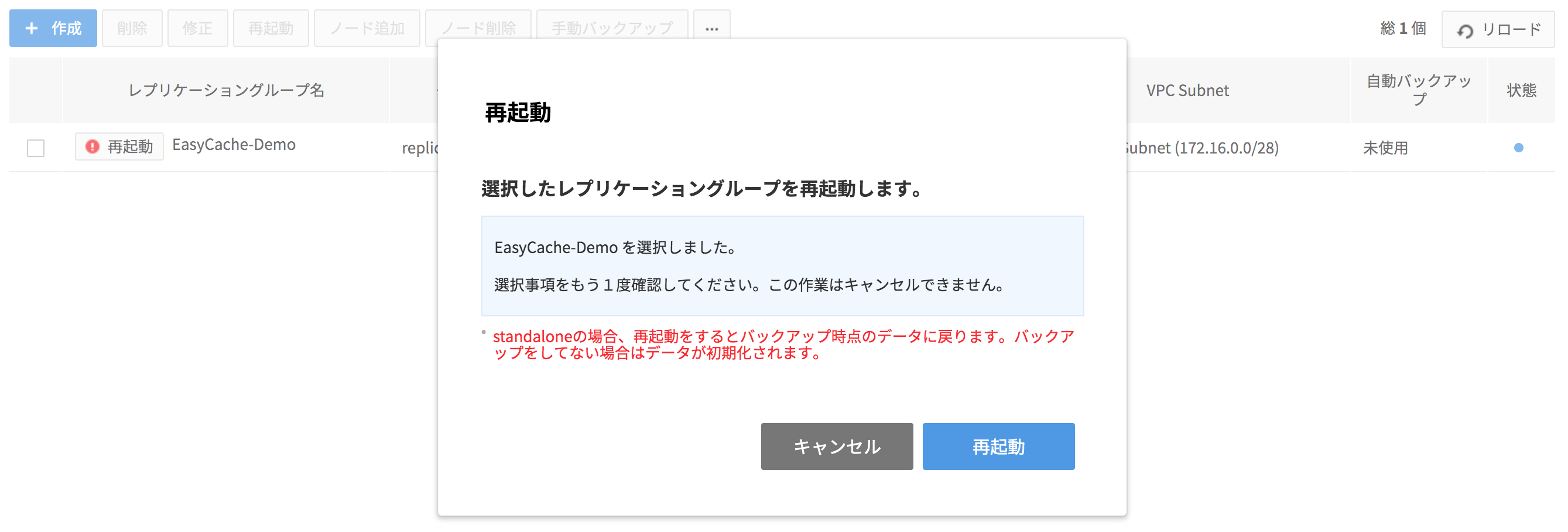
-
メンテナンスノードが複数ある時、1度に1つのノードのみ再起動します。 HAノードが先に再起動し、その後Replicaノードが再起動します。
-
Standaloneの場合、再起動を行うとバックアップ時点のデータに戻り、バックアップを行っていない場合にはデータが初期化されます。
-
ReplicationのMasterノードがメンテナンス対象の場合、すぐに利用できません。 MasterノードをReplicaノードに変更した後、再起動します。
5. レプリケーショングループの状態表示灯が青色に変わり、!再起動アイコンが消えるまで待機します。
- レプリケーショングループが再起動する間は該当レプリケーショングループは操作できません。
付録2. サーバーメンテナンスのためのインターネットゲートウェイ再起動ガイド
- インターネットゲートウェイを再起動するにはコンソールにあるインターネットゲートウェイ再起動機能を使用する必要があります。
- 下記のガイドに従ってコンソールにある再起動機能を利用してください。
1. メンテナンス対象に指定されたインターネットゲートウェイがあるプロジェクトへ移動します。

2. メンテナンス対象レプリケーショングループタブを確認します。
- レプリケーショングループタブの右端にある!インターネットゲートウェイ再起動アイコンを確認します。
- !インターネットゲートウェイ再起動アイコンにマウスオーバーすると、詳細なメンテナンス日程を確認できます。

3. メンテナンス対象レプリケーショングループの右に表示された!インターネットゲートウェイ再起動アイコンをクリックしてメンテナンスノードを再起動します。

4. !インターネットゲートウェイ再起動アイコンが消えるまで待機します。
- 再起動すると、公認ドメインを使用中のノードは外部ネットワークに接続できません。公認ドメインを使用しないノードには影響がありません。
- 再起動にかかる時間は約1分です。再起動したインターネットゲートウェイはメンテナンスが完了した機器で起動します。
目次
- Database > EasyCache > コンソール使用ガイド
- 始める
- レプリケーショングループ
- レプリケーショングループ作成
- レプリケーション(ノード追加)
- レプリケーショングループの修正
- 自動バックアップ
- 手動バックアップ作成
- 公認ドメイン設定
- 読み取り専用ドメイン設定
- データのインポート
- データエクスポート
- インスタンスタイプ変更
- バージョンアップグレード
- マスター変更
- レプリケーショングループの詳細
- モニタリング
- バックアップ
- 復元
- 設定プロファイル
- 設定プロファイル作成
- プロファイル詳細
- アラーム
- アラームルール
- 受信グループ
- イベント
- イベント項目
- 付録1. ハイパーバイザメンテナンスのためのEasyCache再起動ガイド
- 1. メンテナンス対象に指定されたノードがあるプロジェクトへ移動します。
- 2. メンテナンス対象レプリケーショングループを確認します。
- 3. メンテナンス対象ノードのタイプを確認します。
- 4. メンテナンス対象レプリケーショングループを選択し、右に表示された!再起動アイコンをクリックしてメンテナンスノードを再起動します。
- 5. レプリケーショングループの状態表示灯が青色に変わり、!再起動アイコンが消えるまで待機します。
- 付録2. サーバーメンテナンスのためのインターネットゲートウェイ再起動ガイド
- 1. メンテナンス対象に指定されたインターネットゲートウェイがあるプロジェクトへ移動します。
- 2. メンテナンス対象レプリケーショングループタブを確認します。
- 3. メンテナンス対象レプリケーショングループの右に表示された!インターネットゲートウェイ再起動アイコンをクリックしてメンテナンスノードを再起動します。
- 4. !インターネットゲートウェイ再起動アイコンが消えるまで待機します。